 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlow-DPO: Improving LLM Mathematical Reasoning through Online Multi-Agent Learning
Oct 29, 2024



Mathematical reasoning is a crucial capability for Large Language Models (LLMs), yet generating detailed and accurate reasoning traces remains a significant challenge. This paper introduces a novel approach to produce high-quality reasoning traces for LLM fine-tuning using online learning \textbf{Flows}. Our method employs an incremental output production Flow, where component LLMs collaboratively construct solutions through iterative communication. We train the Flow using online Direct Preference Optimization (DPO) learning with rollouts, generating DPO pairs for each training example and updating models in real-time. We directly compare the quality of reasoning traces generated by our method with those produced through direct model inference, demonstrating the effectiveness of our approach in improving LLM performance in mathematical reasoning tasks.
Active, anytime-valid risk controlling prediction sets
Jun 15, 2024

Rigorously establishing the safety of black-box machine learning models concerning critical risk measures is important for providing guarantees about model behavior. Recently, Bates et. al. (JACM '24) introduced the notion of a risk controlling prediction set (RCPS) for producing prediction sets that are statistically guaranteed low risk from machine learning models. Our method extends this notion to the sequential setting, where we provide guarantees even when the data is collected adaptively, and ensures that the risk guarantee is anytime-valid, i.e., simultaneously holds at all time steps. Further, we propose a framework for constructing RCPSes for active labeling, i.e., allowing one to use a labeling policy that chooses whether to query the true label for each received data point and ensures that the expected proportion of data points whose labels are queried are below a predetermined label budget. We also describe how to use predictors (i.e., the machine learning model for which we provide risk control guarantees) to further improve the utility of our RCPSes by estimating the expected risk conditioned on the covariates. We characterize the optimal choices of label policy and predictor under a fixed label budget and show a regret result that relates the estimation error of the optimal labeling policy and predictor to the wealth process that underlies our RCPSes. Lastly, we present practical ways of formulating label policies and empirically show that our label policies use fewer labels to reach higher utility than naive baseline labeling strategies (e.g., labeling all points, randomly labeling points) on both simulations and real data.
Online Joint Fine-tuning of Multi-Agent Flows
Jun 06, 2024A Flow is a collection of component models (``Agents'') which constructs the solution to a complex problem via iterative communication. Flows have emerged as state of the art architectures for code generation, and are the raison d'etre for frameworks like Autogen. However, flows are currently constructed via a combination of manual prompt engineering and stagewise supervised learning techniques; the latter is limited to acyclic flows with granular node supervision. In this writeup I describe a procedure for online joint fine-tuning of an entire flow inspired by the Learning to Search framework. The approach leverages simulator access to reduce preferences over entire episodes to preferences over individual node outputs; when the components are language models the latter is a well-studied problem. The approach is applicable to reward-free settings (e.g., text feedback) if an episode evaluator model is available. I apply to the multi-hop QA dataset Musique achieving a state-of-the-art result.
Provably Efficient Interactive-Grounded Learning with Personalized Reward
May 31, 2024

Interactive-Grounded Learning (IGL) [Xie et al., 2021] is a powerful framework in which a learner aims at maximizing unobservable rewards through interacting with an environment and observing reward-dependent feedback on the taken actions. To deal with personalized rewards that are ubiquitous in applications such as recommendation systems, Maghakian et al. [2022] study a version of IGL with context-dependent feedback, but their algorithm does not come with theoretical guarantees. In this work, we consider the same problem and provide the first provably efficient algorithms with sublinear regret under realizability. Our analysis reveals that the step-function estimator of prior work can deviate uncontrollably due to finite-sample effects. Our solution is a novel Lipschitz reward estimator which underestimates the true reward and enjoys favorable generalization performances. Building on this estimator, we propose two algorithms, one based on explore-then-exploit and the other based on inverse-gap weighting. We apply IGL to learning from image feedback and learning from text feedback, which are reward-free settings that arise in practice. Experimental results showcase the importance of using our Lipschitz reward estimator and the overall effectiveness of our algorithms.
Aligning LLM Agents by Learning Latent Preference from User Edits
Apr 23, 2024
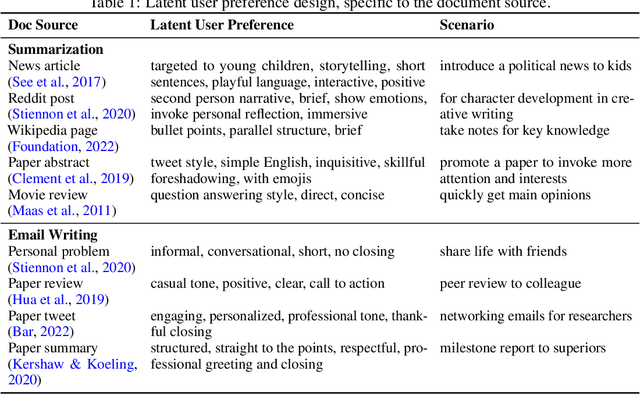


We study interactive learning of language agents based on user edits made to the agent's output. In a typical setting such as writing assistants, the user interacts with a language agent to generate a response given a context, and may optionally edit the agent response to personalize it based on their latent preference, in addition to improving the correctness. The edit feedback is naturally generated, making it a suitable candidate for improving the agent's alignment with the user's preference, and for reducing the cost of user edits over time. We propose a learning framework, PRELUDE that infers a description of the user's latent preference based on historic edit data and using it to define a prompt policy that drives future response generation. This avoids fine-tuning the agent, which is costly, challenging to scale with the number of users, and may even degrade its performance on other tasks. Furthermore, learning descriptive preference improves interpretability, allowing the user to view and modify the learned preference. However, user preference can be complex and vary based on context, making it challenging to learn. To address this, we propose a simple yet effective algorithm named CIPHER that leverages a large language model (LLM) to infer the user preference for a given context based on user edits. In the future, CIPHER retrieves inferred preferences from the k-closest contexts in the history, and forms an aggregate preference for response generation. We introduce two interactive environments -- summarization and email writing, for evaluation using a GPT-4 simulated user. We compare with algorithms that directly retrieve user edits but do not learn descriptive preference, and algorithms that learn context-agnostic preference. On both tasks, CIPHER achieves the lowest edit distance cost and learns preferences that show significant similarity to the ground truth preferences
Efficient Contextual Bandits with Uninformed Feedback Graphs
Feb 12, 2024Bandits with feedback graphs are powerful online learning models that interpolate between the full information and classic bandit problems, capturing many real-life applications. A recent work by Zhang et al. (2023) studies the contextual version of this problem and proposes an efficient and optimal algorithm via a reduction to online regression. However, their algorithm crucially relies on seeing the feedback graph before making each decision, while in many applications, the feedback graph is uninformed, meaning that it is either only revealed after the learner makes her decision or even never fully revealed at all. This work develops the first contextual algorithm for such uninformed settings, via an efficient reduction to online regression over both the losses and the graphs. Importantly, we show that it is critical to learn the graphs using log loss instead of squared loss to obtain favorable regret guarantees. We also demonstrate the empirical effectiveness of our algorithm on a bidding application using both synthetic and real-world data.
Time-uniform confidence bands for the CDF under nonstationarity
Feb 28, 2023



Estimation of the complete distribution of a random variable is a useful primitive for both manual and automated decision making. This problem has received extensive attention in the i.i.d. setting, but the arbitrary data dependent setting remains largely unaddressed. Consistent with known impossibility results, we present computationally felicitous time-uniform and value-uniform bounds on the CDF of the running averaged conditional distribution of a real-valued random variable which are always valid and sometimes trivial, along with an instance-dependent convergence guarantee. The importance-weighted extension is appropriate for estimating complete counterfactual distributions of rewards given controlled experimentation data exhaust, e.g., from an A/B test or a contextual bandit.
Graph Feedback via Reduction to Regression
Feb 17, 2023When feedback is partial, leveraging all available information is critical to minimizing data requirements. Graph feedback, which interpolates between the supervised and bandit regimes, has been extensively studied; but the mature theory is grounded in impractical algorithms. We present and analyze an approach to contextual bandits with graph feedback based upon reduction to regression. The resulting algorithms are practical and achieve known minimax rates.
Infinite Action Contextual Bandits with Reusable Data Exhaust
Feb 16, 2023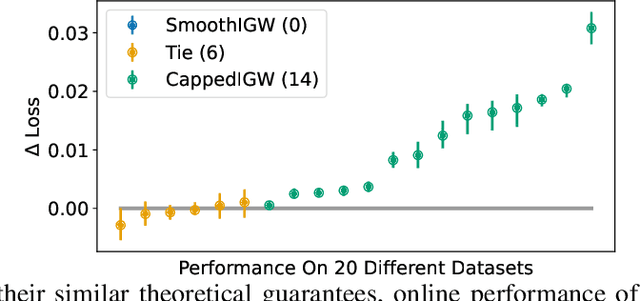

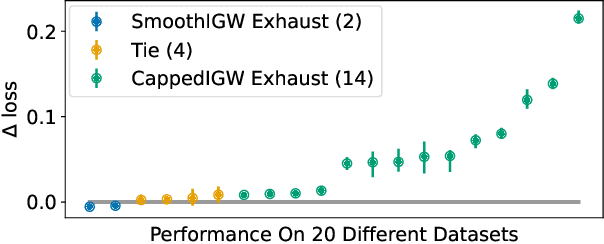
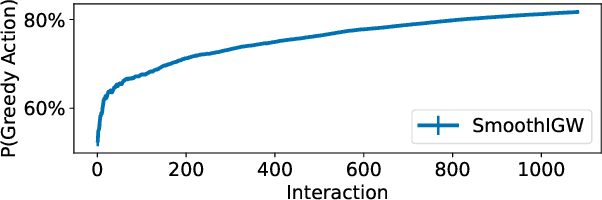
For infinite action contextual bandits, smoothed regret and reduction to regression results in state-of-the-art online statistical performance with computational cost independent of the action set: unfortunately, the resulting data exhaust does not have well-defined importance-weights. This frustrates the execution of downstream data science processes such as offline model selection. In this paper we describe an online algorithm with an equivalent smoothed regret guarantee, but which generates well-defined importance weights: in exchange, the online computational cost increases, but only to order smoothness (i.e., still independent of the action set). This removes a key obstacle to adoption of smoothed regret in production scenarios.
Personalized Reward Learning with Interaction-Grounded Learning (IGL)
Nov 28, 2022



In an era of countless content offerings, recommender systems alleviate information overload by providing users with personalized content suggestions. Due to the scarcity of explicit user feedback, modern recommender systems typically optimize for the same fixed combination of implicit feedback signals across all users. However, this approach disregards a growing body of work highlighting that (i) implicit signals can be used by users in diverse ways, signaling anything from satisfaction to active dislike, and (ii) different users communicate preferences in different ways. We propose applying the recent Interaction Grounded Learning (IGL) paradigm to address the challenge of learning representations of diverse user communication modalities. Rather than taking a fixed, human-designed reward function, IGL is able to learn personalized reward functions for different users and then optimize directly for the latent user satisfaction. We demonstrate the success of IGL with experiments using simulations as well as with real-world production traces.