 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRed-Teaming Vision-Language-Action Models via Quality Diversity Prompt Generation for Robust Robot Policies
Mar 12, 2026Vision-Language-Action (VLA) models have significant potential to enable general-purpose robotic systems for a range of vision-language tasks. However, the performance of VLA-based robots is highly sensitive to the precise wording of language instructions, and it remains difficult to predict when such robots will fail. To improve the robustness of VLAs to different wordings, we present Q-DIG (Quality Diversity for Diverse Instruction Generation), which performs red-teaming by scalably identifying diverse natural language task descriptions that induce failures while remaining task-relevant. Q-DIG integrates Quality Diversity (QD) techniques with Vision-Language Models (VLMs) to generate a broad spectrum of adversarial instructions that expose meaningful vulnerabilities in VLA behavior. Our results across multiple simulation benchmarks show that Q-DIG finds more diverse and meaningful failure modes compared to baseline methods, and that fine-tuning VLAs on the generated instructions improves task success rates. Furthermore, results from a user study highlight that Q-DIG generates prompts judged to be more natural and human-like than those from baselines. Finally, real-world evaluations of Q-DIG prompts show results consistent with simulation, and fine-tuning VLAs on the generated prompts further success rates on unseen instructions. Together, these findings suggest that Q-DIG is a promising approach for identifying vulnerabilities and improving the robustness of VLA-based robots. Our anonymous project website is at qdigvla.github.io.
Prosody as a Teaching Signal for Agent Learning: Exploratory Studies and Algorithmic Implications
Oct 31, 2024



Agent learning from human interaction often relies on explicit signals, but implicit social cues, such as prosody in speech, could provide valuable information for more effective learning. This paper advocates for the integration of prosody as a teaching signal to enhance agent learning from human teachers. Through two exploratory studies--one examining voice feedback in an interactive reinforcement learning setup and the other analyzing restricted audio from human demonstrations in three Atari games--we demonstrate that prosody carries significant information about task dynamics. Our findings suggest that prosodic features, when coupled with explicit feedback, can enhance reinforcement learning outcomes. Moreover, we propose guidelines for prosody-sensitive algorithm design and discuss insights into teaching behavior. Our work underscores the potential of leveraging prosody as an implicit signal for more efficient agent learning, thus advancing human-agent interaction paradigms.
Towards Principled Representation Learning from Videos for Reinforcement Learning
Mar 20, 2024



We study pre-training representations for decision-making using video data, which is abundantly available for tasks such as game agents and software testing. Even though significant empirical advances have been made on this problem, a theoretical understanding remains absent. We initiate the theoretical investigation into principled approaches for representation learning and focus on learning the latent state representations of the underlying MDP using video data. We study two types of settings: one where there is iid noise in the observation, and a more challenging setting where there is also the presence of exogenous noise, which is non-iid noise that is temporally correlated, such as the motion of people or cars in the background. We study three commonly used approaches: autoencoding, temporal contrastive learning, and forward modeling. We prove upper bounds for temporal contrastive learning and forward modeling in the presence of only iid noise. We show that these approaches can learn the latent state and use it to do efficient downstream RL with polynomial sample complexity. When exogenous noise is also present, we establish a lower bound result showing that the sample complexity of learning from video data can be exponentially worse than learning from action-labeled trajectory data. This partially explains why reinforcement learning with video pre-training is hard. We evaluate these representational learning methods in two visual domains, yielding results that are consistent with our theoretical findings.
In-Context Learning in Large Language Models: A Neuroscience-inspired Analysis of Representations
Oct 18, 2023



Large language models (LLMs) exhibit remarkable performance improvement through in-context learning (ICL) by leveraging task-specific examples in the input. However, the mechanisms behind this improvement remain elusive. In this work, we investigate embeddings and attention representations in Llama-2 70B and Vicuna 13B. Specifically, we study how embeddings and attention change after in-context-learning, and how these changes mediate improvement in behavior. We employ neuroscience-inspired techniques, such as representational similarity analysis (RSA), and propose novel methods for parameterized probing and attention ratio analysis (ARA, measuring the ratio of attention to relevant vs. irrelevant information). We designed three tasks with a priori relationships among their conditions: reading comprehension, linear regression, and adversarial prompt injection. We formed hypotheses about expected similarities in task representations to investigate latent changes in embeddings and attention. Our analyses revealed a meaningful correlation between changes in both embeddings and attention representations with improvements in behavioral performance after ICL. This empirical framework empowers a nuanced understanding of how latent representations affect LLM behavior with and without ICL, offering valuable tools and insights for future research and practical applications.
Streaming Active Learning with Deep Neural Networks
Mar 05, 2023Active learning is perhaps most naturally posed as an online learning problem. However, prior active learning approaches with deep neural networks assume offline access to the entire dataset ahead of time. This paper proposes VeSSAL, a new algorithm for batch active learning with deep neural networks in streaming settings, which samples groups of points to query for labels at the moment they are encountered. Our approach trades off between uncertainty and diversity of queried samples to match a desired query rate without requiring any hand-tuned hyperparameters. Altogether, we expand the applicability of deep neural networks to realistic active learning scenarios, such as applications relevant to HCI and large, fractured datasets.
Personalized Reward Learning with Interaction-Grounded Learning (IGL)
Nov 28, 2022



In an era of countless content offerings, recommender systems alleviate information overload by providing users with personalized content suggestions. Due to the scarcity of explicit user feedback, modern recommender systems typically optimize for the same fixed combination of implicit feedback signals across all users. However, this approach disregards a growing body of work highlighting that (i) implicit signals can be used by users in diverse ways, signaling anything from satisfaction to active dislike, and (ii) different users communicate preferences in different ways. We propose applying the recent Interaction Grounded Learning (IGL) paradigm to address the challenge of learning representations of diverse user communication modalities. Rather than taking a fixed, human-designed reward function, IGL is able to learn personalized reward functions for different users and then optimize directly for the latent user satisfaction. We demonstrate the success of IGL with experiments using simulations as well as with real-world production traces.
Understanding Acoustic Patterns of Human Teachers Demonstrating Manipulation Tasks to Robots
Nov 01, 2022



Humans use audio signals in the form of spoken language or verbal reactions effectively when teaching new skills or tasks to other humans. While demonstrations allow humans to teach robots in a natural way, learning from trajectories alone does not leverage other available modalities including audio from human teachers. To effectively utilize audio cues accompanying human demonstrations, first it is important to understand what kind of information is present and conveyed by such cues. This work characterizes audio from human teachers demonstrating multi-step manipulation tasks to a situated Sawyer robot using three feature types: (1) duration of speech used, (2) expressiveness in speech or prosody, and (3) semantic content of speech. We analyze these features along four dimensions and find that teachers convey similar semantic concepts via spoken words for different conditions of (1) demonstration types, (2) audio usage instructions, (3) subtasks, and (4) errors during demonstrations. However, differentiating properties of speech in terms of duration and expressiveness are present along the four dimensions, highlighting that human audio carries rich information, potentially beneficial for technological advancement of robot learning from demonstration methods.
Interaction-Grounded Learning with Action-inclusive Feedback
Jun 16, 2022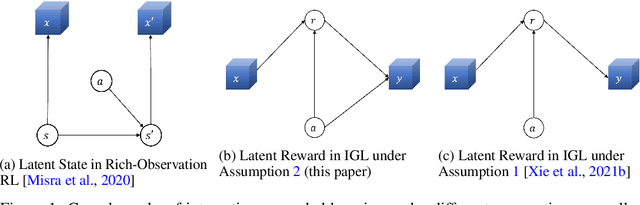

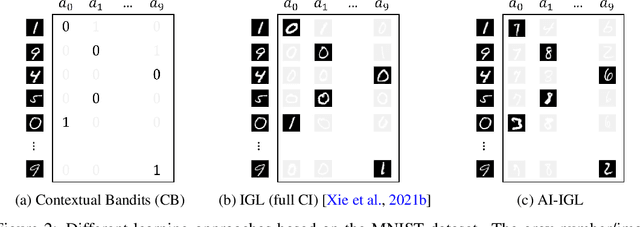

Consider the problem setting of Interaction-Grounded Learning (IGL), in which a learner's goal is to optimally interact with the environment with no explicit reward to ground its policies. The agent observes a context vector, takes an action, and receives a feedback vector, using this information to effectively optimize a policy with respect to a latent reward function. Prior analyzed approaches fail when the feedback vector contains the action, which significantly limits IGL's success in many potential scenarios such as Brain-computer interface (BCI) or Human-computer interface (HCI) applications. We address this by creating an algorithm and analysis which allows IGL to work even when the feedback vector contains the action, encoded in any fashion. We provide theoretical guarantees and large-scale experiments based on supervised datasets to demonstrate the effectiveness of the new approach.
A Ranking Game for Imitation Learning
Feb 07, 2022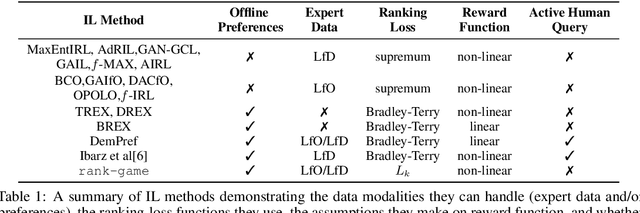
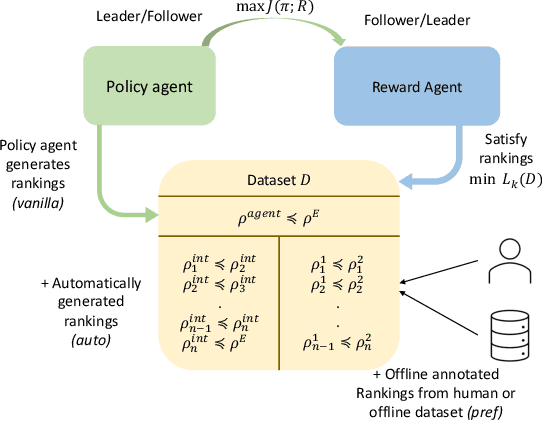
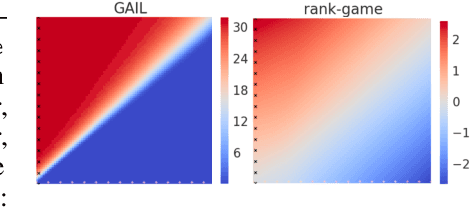
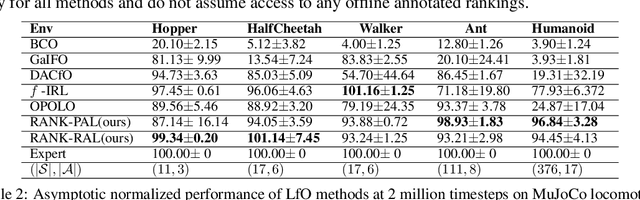
We propose a new framework for imitation learning - treating imitation as a two-player ranking-based Stackelberg game between a $\textit{policy}$ and a $\textit{reward}$ function. In this game, the reward agent learns to satisfy pairwise performance rankings within a set of policies, while the policy agent learns to maximize this reward. This game encompasses a large subset of both inverse reinforcement learning (IRL) methods and methods which learn from offline preferences. The Stackelberg game formulation allows us to use optimization methods that take the game structure into account, leading to more sample efficient and stable learning dynamics compared to existing IRL methods. We theoretically analyze the requirements of the loss function used for ranking policy performances to facilitate near-optimal imitation learning at equilibrium. We use insights from this analysis to further increase sample efficiency of the ranking game by using automatically generated rankings or with offline annotated rankings. Our experiments show that the proposed method achieves state-of-the-art sample efficiency and is able to solve previously unsolvable tasks in the Learning from Observation (LfO) setting.
Efficiently Guiding Imitation Learning Algorithms with Human Gaze
Mar 05, 2020
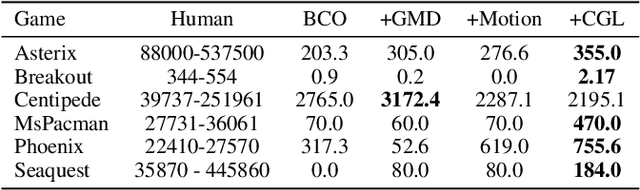
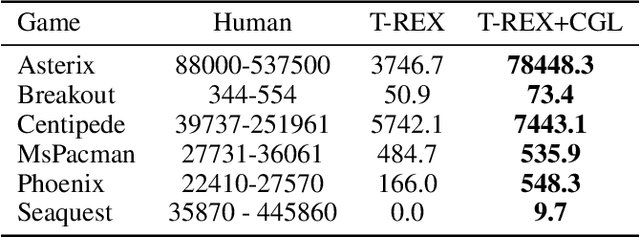
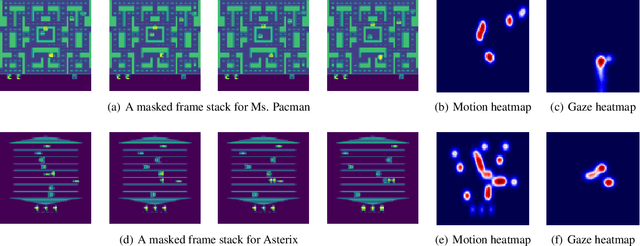
Human gaze is known to be an intention-revealing signal in human demonstrations of tasks. In this work, we use gaze cues from human demonstrators to enhance the performance of state-of-the-art inverse reinforcement learning (IRL) and behavioral cloning (BC) algorithms. We propose a novel approach for utilizing gaze data in a computationally efficient manner --- encoding the human's attention as part of an auxiliary loss function, without adding any additional learnable parameters to those models and without requiring gaze data at test time. The auxiliary loss encourages a network to have convolutional activations in regions where the human's gaze fixated. We show how to augment any existing convolutional architecture with our auxiliary gaze loss (coverage-based gaze loss or CGL) that can guide learning toward a better reward function or policy. We show that our proposed approach improves performance of both BC and IRL methods on a variety of Atari games. We also compare against two baseline methods for utilizing gaze data with imitation learning methods. Our approach outperforms a baseline method, called gaze-modulated dropout (GMD), and is comparable to another method (AGIL) which uses gaze as input to the network and thus increases the amount of learnable parameters.