 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFair-GNE : Generalized Nash Equilibrium-Seeking Fairness in Multiagent Healthcare Automation
Nov 18, 2025
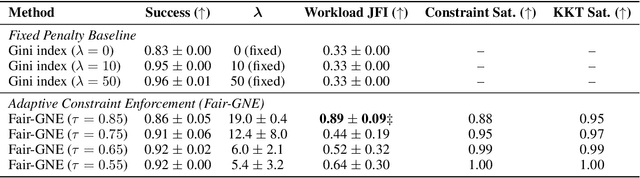
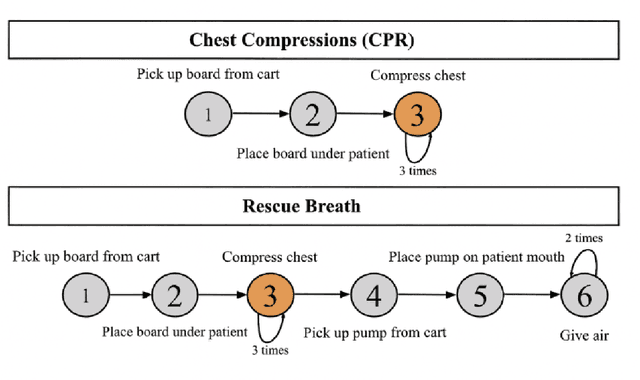
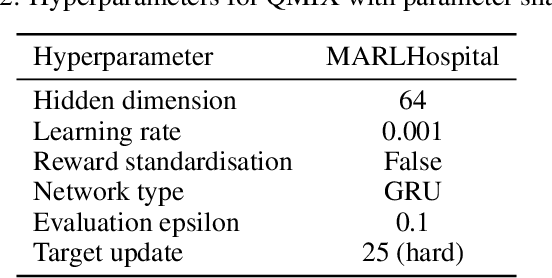
Enforcing a fair workload allocation among multiple agents tasked to achieve an objective in learning enabled demand side healthcare worker settings is crucial for consistent and reliable performance at runtime. Existing multi-agent reinforcement learning (MARL) approaches steer fairness by shaping reward through post hoc orchestrations, leaving no certifiable self-enforceable fairness that is immutable by individual agents at runtime. Contextualized within a setting where each agent shares resources with others, we address this shortcoming with a learning enabled optimization scheme among self-interested decision makers whose individual actions affect those of other agents. This extends the problem to a generalized Nash equilibrium (GNE) game-theoretic framework where we steer group policy to a safe and locally efficient equilibrium, so that no agent can improve its utility function by unilaterally changing its decisions. Fair-GNE models MARL as a constrained generalized Nash equilibrium-seeking (GNE) game, prescribing an ideal equitable collective equilibrium within the problem's natural fabric. Our hypothesis is rigorously evaluated in our custom-designed high-fidelity resuscitation simulator. Across all our numerical experiments, Fair-GNE achieves significant improvement in workload balance over fixed-penalty baselines (0.89 vs.\ 0.33 JFI, $p < 0.01$) while maintaining 86\% task success, demonstrating statistically significant fairness gains through adaptive constraint enforcement. Our results communicate our formulations, evaluation metrics, and equilibrium-seeking innovations in large multi-agent learning-based healthcare systems with clarity and principled fairness enforcement.
Is Bellman Equation Enough for Learning Control?
Mar 06, 2025The Bellman equation and its continuous-time counterpart, the Hamilton-Jacobi-Bellman (HJB) equation, serve as necessary conditions for optimality in reinforcement learning and optimal control. While the value function is known to be the unique solution to the Bellman equation in tabular settings, we demonstrate that this uniqueness fails to hold in continuous state spaces. Specifically, for linear dynamical systems, we prove the Bellman equation admits at least $\binom{2n}{n}$ solutions, where $n$ is the state dimension. Crucially, only one of these solutions yields both an optimal policy and a stable closed-loop system. We then demonstrate a common failure mode in value-based methods: convergence to unstable solutions due to the exponential imbalance between admissible and inadmissible solutions. Finally, we introduce a positive-definite neural architecture that guarantees convergence to the stable solution by construction to address this issue.
Verification-Aided Learning of Neural Network Barrier Functions with Termination Guarantees
Mar 12, 2024Barrier functions are a general framework for establishing a safety guarantee for a system. However, there is no general method for finding these functions. To address this shortcoming, recent approaches use self-supervised learning techniques to learn these functions using training data that are periodically generated by a verification procedure, leading to a verification-aided learning framework. Despite its immense potential in automating barrier function synthesis, the verification-aided learning framework does not have termination guarantees and may suffer from a low success rate of finding a valid barrier function in practice. In this paper, we propose a holistic approach to address these drawbacks. With a convex formulation of the barrier function synthesis, we propose to first learn an empirically well-behaved NN basis function and then apply a fine-tuning algorithm that exploits the convexity and counterexamples from the verification failure to find a valid barrier function with finite-step termination guarantees: if there exist valid barrier functions, the fine-tuning algorithm is guaranteed to find one in a finite number of iterations. We demonstrate that our fine-tuning method can significantly boost the performance of the verification-aided learning framework on examples of different scales and using various neural network verifiers.
Singularly Perturbed Layered Control of Deformable Bodies
Dec 21, 2023Variable curvature modeling tools provide an accurate means of controlling infinite degrees-of-freedom deformable bodies and structures. However, their forward and inverse Newton-Euler dynamics are fraught with high computational costs. Assuming piecewise constant strains across discretized Cosserat rods imposed on the soft material, a composite two time-scale singularly perturbed nonlinear backstepping control scheme is here introduced. This is to alleviate the long computational times of the recursive Newton-Euler dynamics for soft structures. Our contribution is three-pronged: (i) we decompose the system's Newton-Euler dynamics to a two coupled sub-dynamics by introducing a perturbation parameter; (ii) we then prescribe a set of stabilizing controllers for regulating each subsystem's dynamics; and (iii) we study the interconnected singularly perturbed system and analyze its stability.
Lagrangian Properties and Control of Soft Robots Modeled with Discrete Cosserat Rods
Dec 10, 2023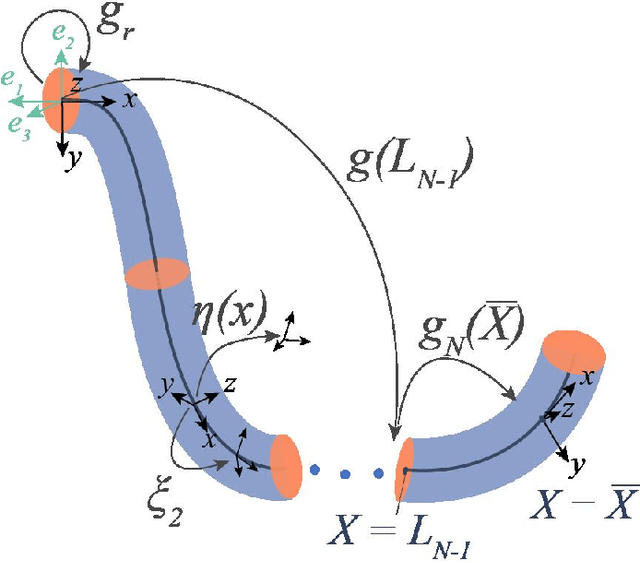
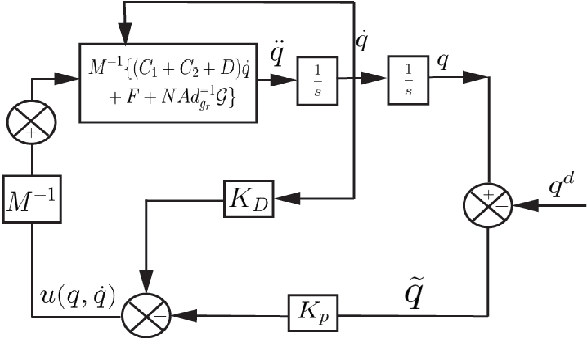
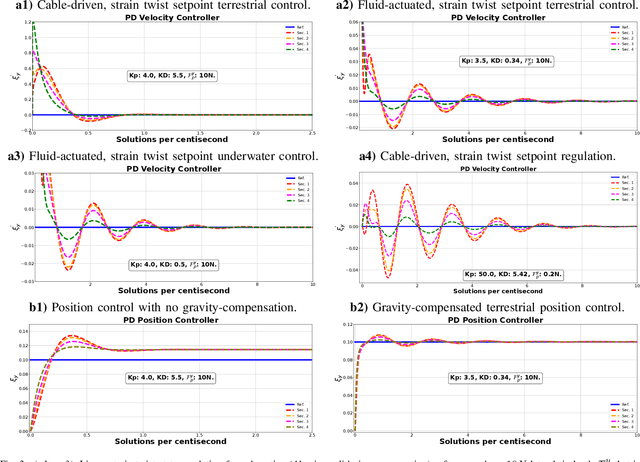
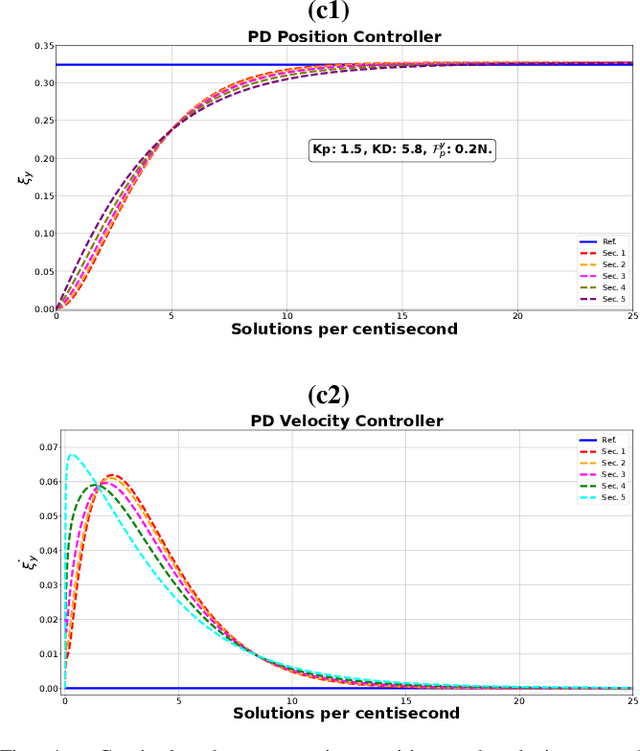
The characteristic ``in-plane" bending associated with soft robots' deformation make them preferred over rigid robots in sophisticated manipulation and movement tasks. Executing such motion strategies to precision in soft deformable robots and structures is however fraught with modeling and control challenges given their infinite degrees-of-freedom. Imposing \textit{piecewise constant strains} (PCS) across (discretized) Cosserat microsolids on the continuum material however, their dynamics become amenable to tractable mathematical analysis. While this PCS model handles the characteristic difficult-to-model ``in-plane" bending well, its Lagrangian properties are not exploited for control in literature neither is there a rigorous study on the dynamic performance of multisection deformable materials for ``in-plane" bending that guarantees steady-state convergence. In this sentiment, we first establish the PCS model's structural Lagrangian properties. Second, we exploit these for control on various strain goal states. Third, we benchmark our hypotheses against an Octopus-inspired robot arm under different constant tip loads. These induce non-constant ``in-plane" deformation and we regulate strain states throughout the continuum in these configurations. Our numerical results establish convergence to desired equilibrium throughout the continuum in all of our tests. Within the bounds here set, we conjecture that our methods can find wide adoption in the control of cable- and fluid-driven multisection soft robotic arms; and may be extensible to the (learning-based) control of deformable agents employed in simulated, mixed, or augmented reality.
PcLast: Discovering Plannable Continuous Latent States
Nov 06, 2023



Goal-conditioned planning benefits from learned low-dimensional representations of rich, high-dimensional observations. While compact latent representations, typically learned from variational autoencoders or inverse dynamics, enable goal-conditioned planning they ignore state affordances, thus hampering their sample-efficient planning capabilities. In this paper, we learn a representation that associates reachable states together for effective onward planning. We first learn a latent representation with multi-step inverse dynamics (to remove distracting information); and then transform this representation to associate reachable states together in $\ell_2$ space. Our proposals are rigorously tested in various simulation testbeds. Numerical results in reward-based and reward-free settings show significant improvements in sampling efficiency, and yields layered state abstractions that enable computationally efficient hierarchical planning.
Guaranteed Discovery of Controllable Latent States with Multi-Step Inverse Models
Jul 17, 2022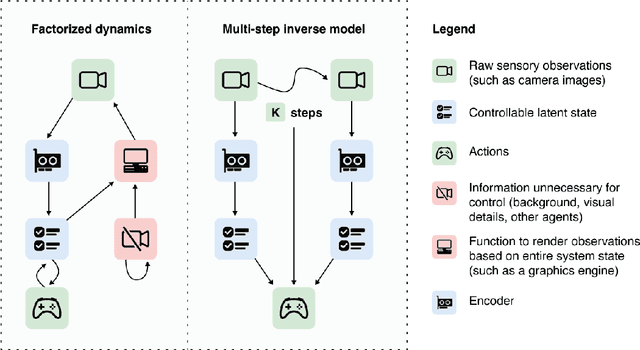
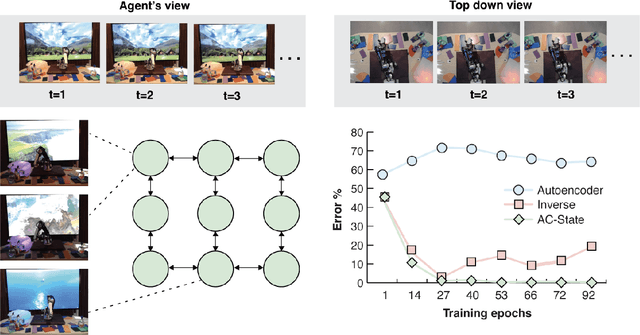
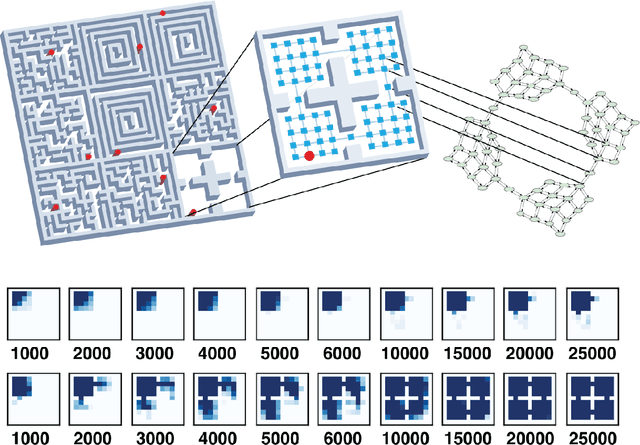
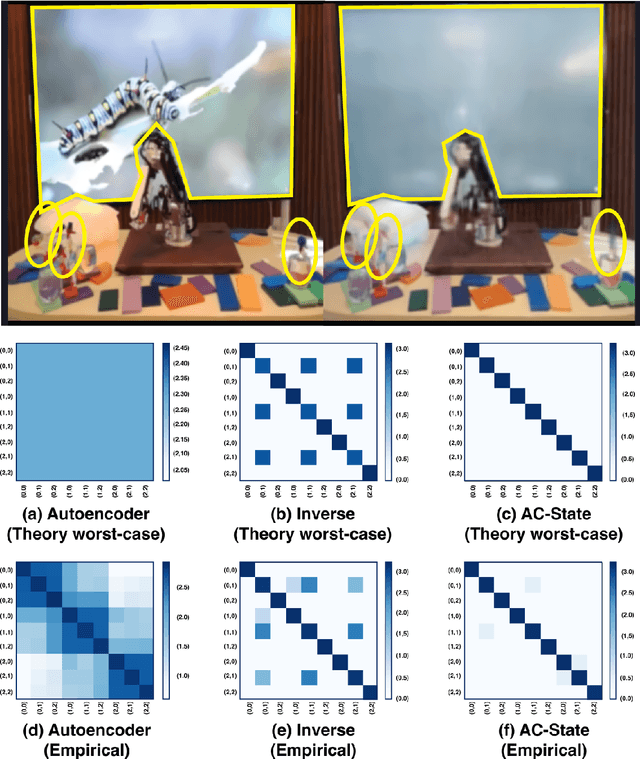
A person walking along a city street who tries to model all aspects of the world would quickly be overwhelmed by a multitude of shops, cars, and people moving in and out of view, following their own complex and inscrutable dynamics. Exploration and navigation in such an environment is an everyday task, requiring no vast exertion of mental resources. Is it possible to turn this fire hose of sensory information into a minimal latent state which is necessary and sufficient for an agent to successfully act in the world? We formulate this question concretely, and propose the Agent-Controllable State Discovery algorithm (AC-State), which has theoretical guarantees and is practically demonstrated to discover the \textit{minimal controllable latent state} which contains all of the information necessary for controlling the agent, while fully discarding all irrelevant information. This algorithm consists of a multi-step inverse model (predicting actions from distant observations) with an information bottleneck. AC-State enables localization, exploration, and navigation without reward or demonstrations. We demonstrate the discovery of controllable latent state in three domains: localizing a robot arm with distractions (e.g., changing lighting conditions and background), exploring in a maze alongside other agents, and navigating in the Matterport house simulator.
Interaction-Grounded Learning with Action-inclusive Feedback
Jun 16, 2022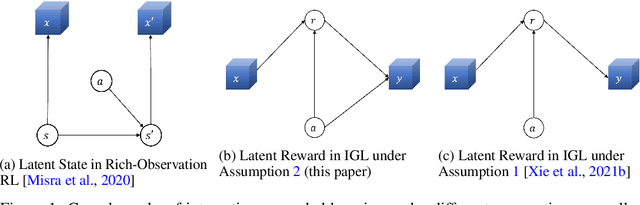

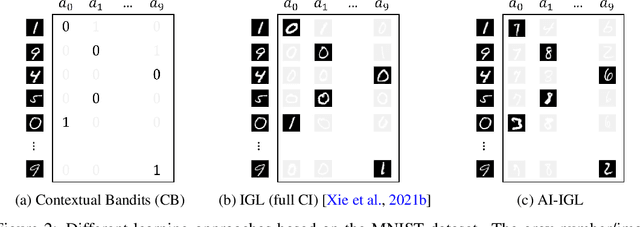

Consider the problem setting of Interaction-Grounded Learning (IGL), in which a learner's goal is to optimally interact with the environment with no explicit reward to ground its policies. The agent observes a context vector, takes an action, and receives a feedback vector, using this information to effectively optimize a policy with respect to a latent reward function. Prior analyzed approaches fail when the feedback vector contains the action, which significantly limits IGL's success in many potential scenarios such as Brain-computer interface (BCI) or Human-computer interface (HCI) applications. We address this by creating an algorithm and analysis which allows IGL to work even when the feedback vector contains the action, encoded in any fashion. We provide theoretical guarantees and large-scale experiments based on supervised datasets to demonstrate the effectiveness of the new approach.