 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Low-Cost Teleoperation: Augmenting GELLO with Force
Jul 18, 2025In this work we extend the low-cost GELLO teleoperation system, initially designed for joint position control, with additional force information. Our first extension is to implement force feedback, allowing users to feel resistance when interacting with the environment. Our second extension is to add force information into the data collection process and training of imitation learning models. We validate our additions by implementing these on a GELLO system with a Franka Panda arm as the follower robot, performing a user study, and comparing the performance of policies trained with and without force information on a range of simulated and real dexterous manipulation tasks. Qualitatively, users with robotics experience preferred our controller, and the addition of force inputs improved task success on the majority of tasks.
Reinforcement Learning for Sequence Design Leveraging Protein Language Models
Jul 03, 2024



Protein sequence design, determined by amino acid sequences, are essential to protein engineering problems in drug discovery. Prior approaches have resorted to evolutionary strategies or Monte-Carlo methods for protein design, but often fail to exploit the structure of the combinatorial search space, to generalize to unseen sequences. In the context of discrete black box optimization over large search spaces, learning a mutation policy to generate novel sequences with reinforcement learning is appealing. Recent advances in protein language models (PLMs) trained on large corpora of protein sequences offer a potential solution to this problem by scoring proteins according to their biological plausibility (such as the TM-score). In this work, we propose to use PLMs as a reward function to generate new sequences. Yet the PLM can be computationally expensive to query due to its large size. To this end, we propose an alternative paradigm where optimization can be performed on scores from a smaller proxy model that is periodically finetuned, jointly while learning the mutation policy. We perform extensive experiments on various sequence lengths to benchmark RL-based approaches, and provide comprehensive evaluations along biological plausibility and diversity of the protein. Our experimental results include favorable evaluations of the proposed sequences, along with high diversity scores, demonstrating that RL is a strong candidate for biological sequence design. Finally, we provide a modular open source implementation can be easily integrated in most RL training loops, with support for replacing the reward model with other PLMs, to spur further research in this domain. The code for all experiments is provided in the supplementary material.
PcLast: Discovering Plannable Continuous Latent States
Nov 06, 2023



Goal-conditioned planning benefits from learned low-dimensional representations of rich, high-dimensional observations. While compact latent representations, typically learned from variational autoencoders or inverse dynamics, enable goal-conditioned planning they ignore state affordances, thus hampering their sample-efficient planning capabilities. In this paper, we learn a representation that associates reachable states together for effective onward planning. We first learn a latent representation with multi-step inverse dynamics (to remove distracting information); and then transform this representation to associate reachable states together in $\ell_2$ space. Our proposals are rigorously tested in various simulation testbeds. Numerical results in reward-based and reward-free settings show significant improvements in sampling efficiency, and yields layered state abstractions that enable computationally efficient hierarchical planning.
Bridging the Gap Between Offline and Online Reinforcement Learning Evaluation Methodologies
Dec 15, 2022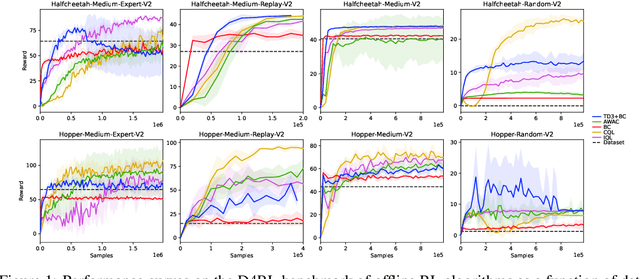
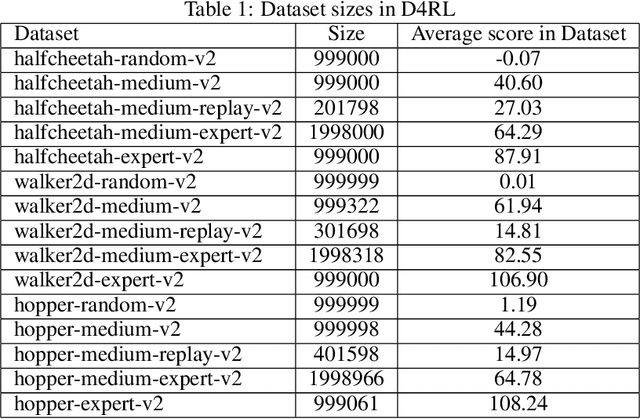

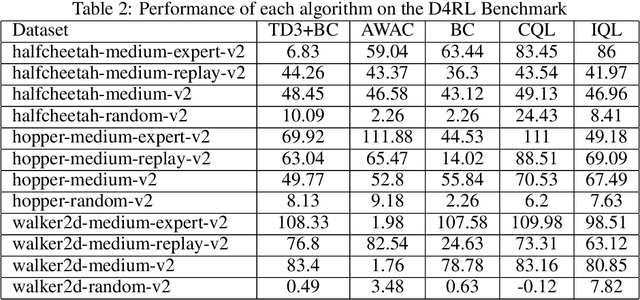
Reinforcement learning (RL) has shown great promise with algorithms learning in environments with large state and action spaces purely from scalar reward signals. A crucial challenge for current deep RL algorithms is that they require a tremendous amount of environment interactions for learning. This can be infeasible in situations where such interactions are expensive; such as in robotics. Offline RL algorithms try to address this issue by bootstrapping the learning process from existing logged data without needing to interact with the environment from the very beginning. While online RL algorithms are typically evaluated as a function of the number of environment interactions, there exists no single established protocol for evaluating offline RL methods.In this paper, we propose a sequential approach to evaluate offline RL algorithms as a function of the training set size and thus by their data efficiency. Sequential evaluation provides valuable insights into the data efficiency of the learning process and the robustness of algorithms to distribution changes in the dataset while also harmonizing the visualization of the offline and online learning phases. Our approach is generally applicable and easy to implement. We compare several existing offline RL algorithms using this approach and present insights from a variety of tasks and offline datasets.
Prioritizing Samples in Reinforcement Learning with Reducible Loss
Aug 22, 2022
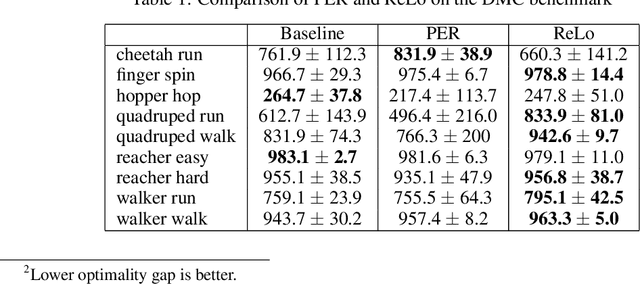


Most reinforcement learning algorithms take advantage of an experience replay buffer to repeatedly train on samples the agent has observed in the past. This prevents catastrophic forgetting, however simply assigning equal importance to each of the samples is a naive strategy. In this paper, we propose a method to prioritize samples based on how much we can learn from a sample. We define the learn-ability of a sample as the steady decrease of the training loss associated with this sample over time. We develop an algorithm to prioritize samples with high learn-ability, while assigning lower priority to those that are hard-to-learn, typically caused by noise or stochasticity. We empirically show that our method is more robust than random sampling and also better than just prioritizing with respect to the training loss, i.e. the temporal difference loss, which is used in vanilla prioritized experience replay.