 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen does predictive inverse dynamics outperform behavior cloning?
Jan 29, 2026Behavior cloning (BC) is a practical offline imitation learning method, but it often fails when expert demonstrations are limited. Recent works have introduced a class of architectures named predictive inverse dynamics models (PIDM) that combine a future state predictor with an inverse dynamics model (IDM). While PIDM often outperforms BC, the reasons behind its benefits remain unclear. In this paper, we provide a theoretical explanation: PIDM introduces a bias-variance tradeoff. While predicting the future state introduces bias, conditioning the IDM on the prediction can significantly reduce variance. We establish conditions on the state predictor bias for PIDM to achieve lower prediction error and higher sample efficiency than BC, with the gap widening when additional data sources are available. We validate the theoretical insights empirically in 2D navigation tasks, where BC requires up to five times (three times on average) more demonstrations than PIDM to reach comparable performance; and in a complex 3D environment in a modern video game with high-dimensional visual inputs and stochastic transitions, where BC requires over 66\% more samples than PIDM.
Behaviour Discovery and Attribution for Explainable Reinforcement Learning
Mar 19, 2025Explaining the decisions made by reinforcement learning (RL) agents is critical for building trust and ensuring reliability in real-world applications. Traditional approaches to explainability often rely on saliency analysis, which can be limited in providing actionable insights. Recently, there has been growing interest in attributing RL decisions to specific trajectories within a dataset. However, these methods often generalize explanations to long trajectories, potentially involving multiple distinct behaviors. Often, providing multiple more fine grained explanations would improve clarity. In this work, we propose a framework for behavior discovery and action attribution to behaviors in offline RL trajectories. Our method identifies meaningful behavioral segments, enabling more precise and granular explanations associated with high level agent behaviors. This approach is adaptable across diverse environments with minimal modifications, offering a scalable and versatile solution for behavior discovery and attribution for explainable RL.
Unsupervised Event Outlier Detection in Continuous Time
Nov 25, 2024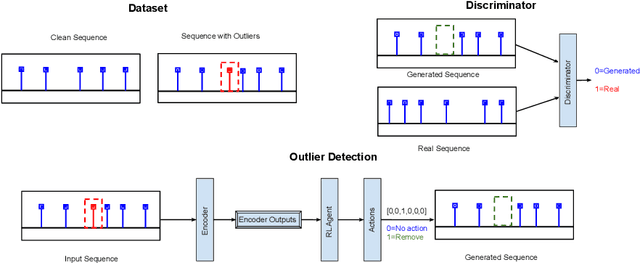
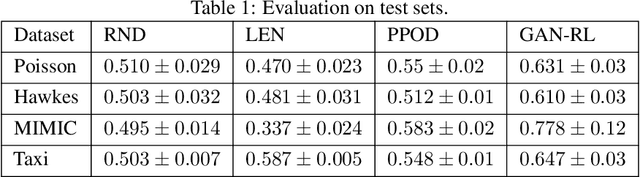
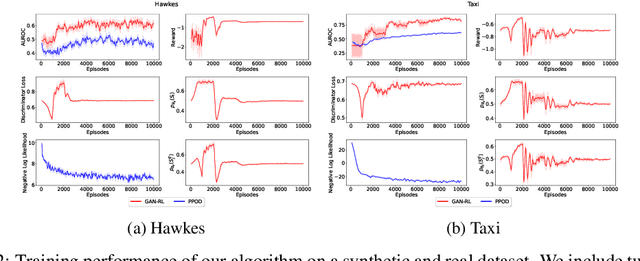
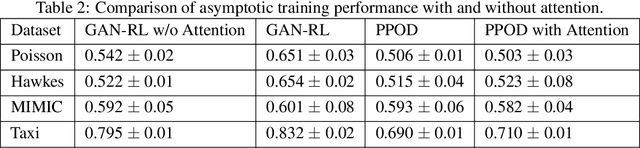
Event sequence data record the occurrences of events in continuous time. Event sequence forecasting based on temporal point processes (TPPs) has been extensively studied, but outlier or anomaly detection, especially without any supervision from humans, is still underexplored. In this work, we develop, to the best our knowledge, the first unsupervised outlier detection approach to detecting abnormal events. Our novel unsupervised outlier detection framework is based on ideas from generative adversarial networks (GANs) and reinforcement learning (RL). We train a 'generator' that corrects outliers in the data with a 'discriminator' that learns to discriminate the corrected data from the real data, which may contain outliers. A key insight is that if the generator made a mistake in the correction, it would generate anomalies that are different from the anomalies in the real data, so it serves as data augmentation for the discriminator learning. Different from typical GAN-based outlier detection approaches, our method employs the generator to detect outliers in an online manner. The experimental results show that our method can detect event outliers more accurately than the state-of-the-art approaches.
Spectral Temporal Contrastive Learning
Dec 07, 2023


Learning useful data representations without requiring labels is a cornerstone of modern deep learning. Self-supervised learning methods, particularly contrastive learning (CL), have proven successful by leveraging data augmentations to define positive pairs. This success has prompted a number of theoretical studies to better understand CL and investigate theoretical bounds for downstream linear probing tasks. This work is concerned with the temporal contrastive learning (TCL) setting where the sequential structure of the data is used instead to define positive pairs, which is more commonly used in RL and robotics contexts. In this paper, we adapt recent work on Spectral CL to formulate Spectral Temporal Contrastive Learning (STCL). We discuss a population loss based on a state graph derived from a time-homogeneous reversible Markov chain with uniform stationary distribution. The STCL loss enables to connect the linear probing performance to the spectral properties of the graph, and can be estimated by considering previously observed data sequences as an ensemble of MCMC chains.
Discovering Object-Centric Generalized Value Functions From Pixels
Apr 27, 2023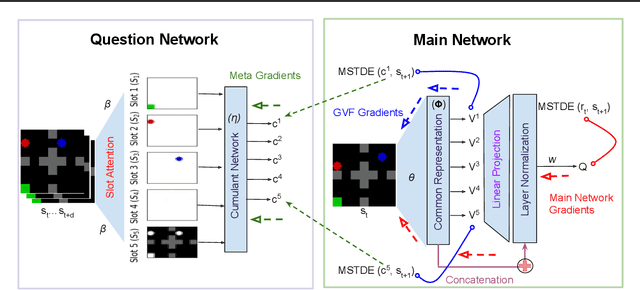
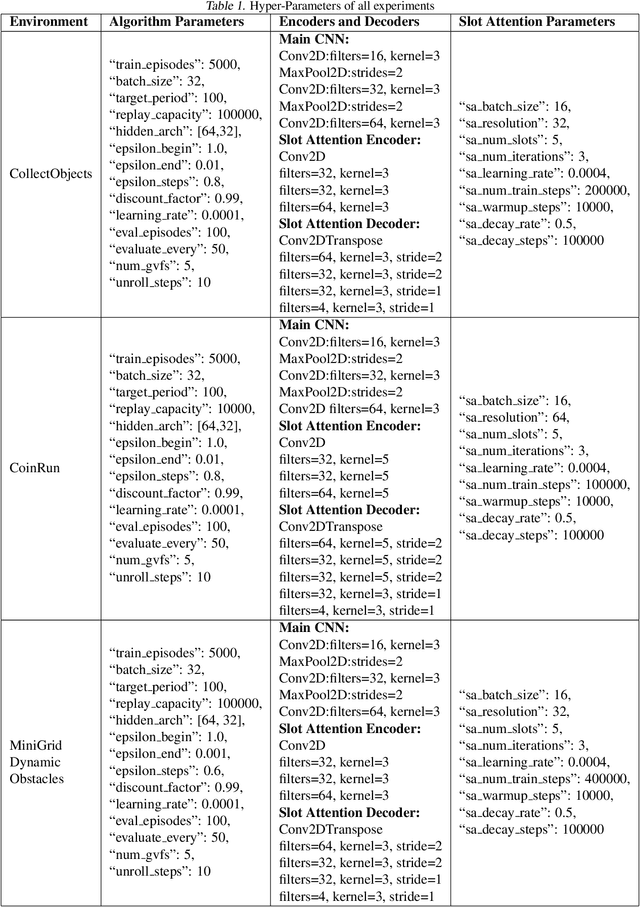
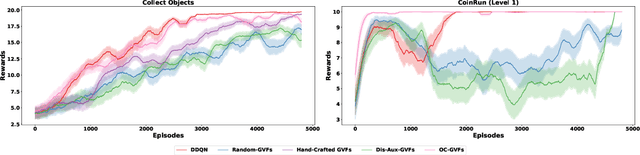
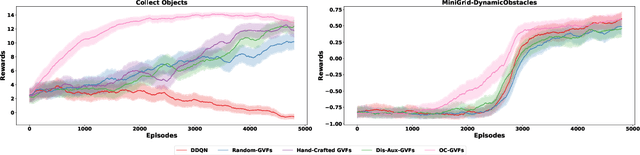
Deep Reinforcement Learning has shown significant progress in extracting useful representations from high-dimensional inputs albeit using hand-crafted auxiliary tasks and pseudo rewards. Automatically learning such representations in an object-centric manner geared towards control and fast adaptation remains an open research problem. In this paper, we introduce a method that tries to discover meaningful features from objects, translating them to temporally coherent "question" functions and leveraging the subsequent learned general value functions for control. We compare our approach with state-of-the-art techniques alongside other ablations and show competitive performance in both stationary and non-stationary settings. Finally, we also investigate the discovered general value functions and through qualitative analysis show that the learned representations are not only interpretable but also, centered around objects that are invariant to changes across tasks facilitating fast adaptation.
Locally Constrained Representations in Reinforcement Learning
Sep 20, 2022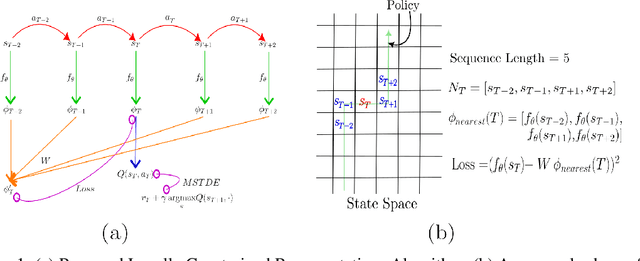
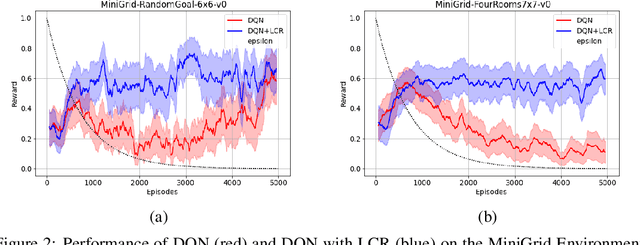
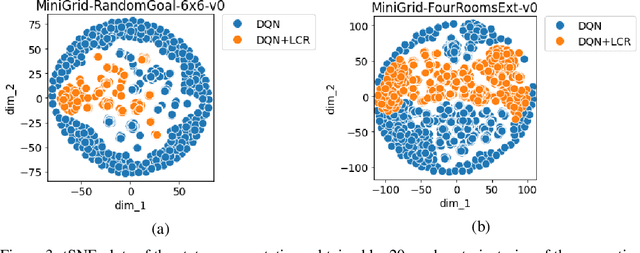
The success of Reinforcement Learning (RL) heavily relies on the ability to learn robust representations from the observations of the environment. In most cases, the representations learned purely by the reinforcement learning loss can differ vastly across states depending on how the value functions change. However, the representations learned need not be very specific to the task at hand. Relying only on the RL objective may yield representations that vary greatly across successive time steps. In addition, since the RL loss has a changing target, the representations learned would depend on how good the current values/policies are. Thus, disentangling the representations from the main task would allow them to focus more on capturing transition dynamics which can improve generalization. To this end, we propose locally constrained representations, where an auxiliary loss forces the state representations to be predictable by the representations of the neighbouring states. This encourages the representations to be driven not only by the value/policy learning but also self-supervised learning, which constrains the representations from changing too rapidly. We evaluate the proposed method on several known benchmarks and observe strong performance. Especially in continuous control tasks, our experiments show a significant advantage over a strong baseline.
Prioritizing Samples in Reinforcement Learning with Reducible Loss
Aug 22, 2022
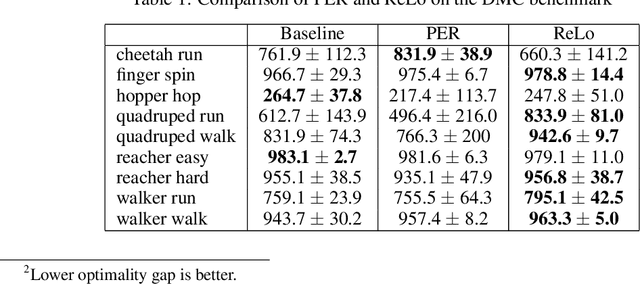


Most reinforcement learning algorithms take advantage of an experience replay buffer to repeatedly train on samples the agent has observed in the past. This prevents catastrophic forgetting, however simply assigning equal importance to each of the samples is a naive strategy. In this paper, we propose a method to prioritize samples based on how much we can learn from a sample. We define the learn-ability of a sample as the steady decrease of the training loss associated with this sample over time. We develop an algorithm to prioritize samples with high learn-ability, while assigning lower priority to those that are hard-to-learn, typically caused by noise or stochasticity. We empirically show that our method is more robust than random sampling and also better than just prioritizing with respect to the training loss, i.e. the temporal difference loss, which is used in vanilla prioritized experience replay.
A Learning Based Framework for Handling Uncertain Lead Times in Multi-Product Inventory Management
Mar 09, 2022
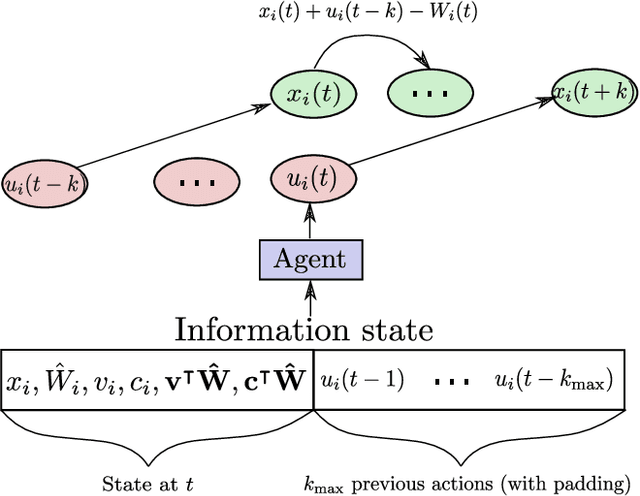
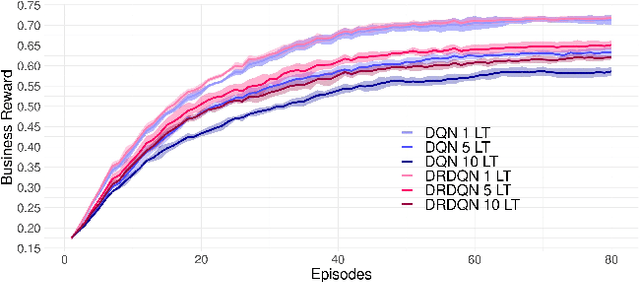
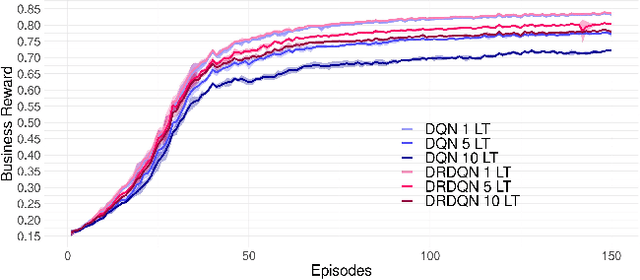
Most existing literature on supply chain and inventory management consider stochastic demand processes with zero or constant lead times. While it is true that in certain niche scenarios, uncertainty in lead times can be ignored, most real-world scenarios exhibit stochasticity in lead times. These random fluctuations can be caused due to uncertainty in arrival of raw materials at the manufacturer's end, delay in transportation, an unforeseen surge in demands, and switching to a different vendor, to name a few. Stochasticity in lead times is known to severely degrade the performance in an inventory management system, and it is only fair to abridge this gap in supply chain system through a principled approach. Motivated by the recently introduced delay-resolved deep Q-learning (DRDQN) algorithm, this paper develops a reinforcement learning based paradigm for handling uncertainty in lead times (\emph{action delay}). Through empirical evaluations, it is further shown that the inventory management with uncertain lead times is not only equivalent to that of delay in information sharing across multiple echelons (\emph{observation delay}), a model trained to handle one kind of delay is capable to handle delays of another kind without requiring to be retrained. Finally, we apply the delay-resolved framework to scenarios comprising of multiple products subjected to stochasticity in lead times, and elucidate how the delay-resolved framework negates the effect of any delay to achieve near-optimal performance.
Follow your Nose: Using General Value Functions for Directed Exploration in Reinforcement Learning
Mar 02, 2022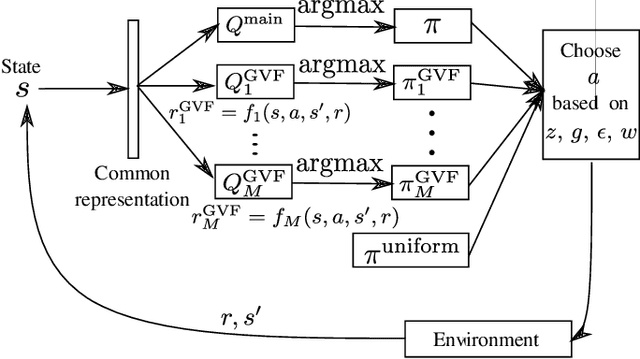
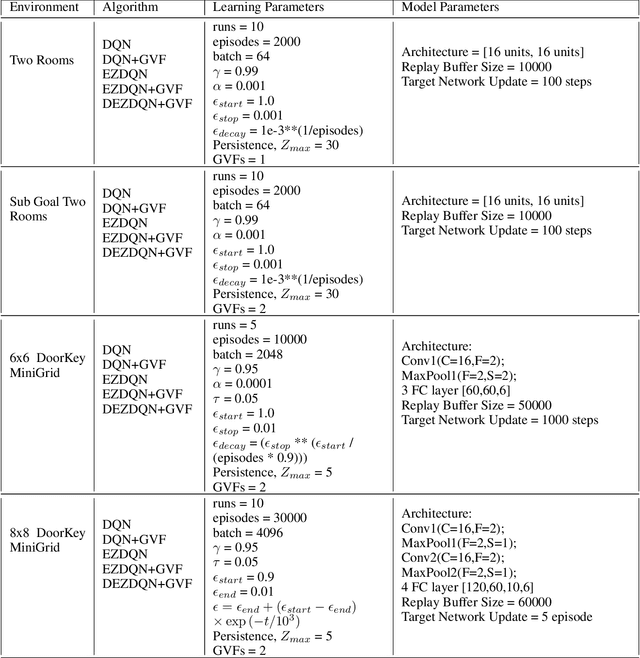
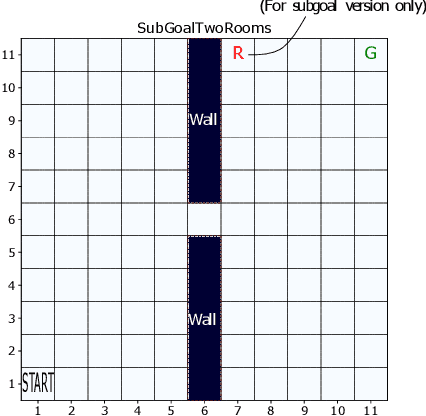
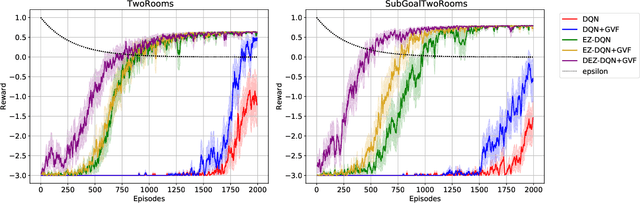
Exploration versus exploitation dilemma is a significant problem in reinforcement learning (RL), particularly in complex environments with large state space and sparse rewards. When optimizing for a particular goal, running simple smaller tasks can often be a good way to learn additional information about the environment. Exploration methods have been used to sample better trajectories from the environment for improved performance while auxiliary tasks have been incorporated generally where the reward is sparse. If there is little reward signal available, the agent requires clever exploration strategies to reach parts of the state space that contain relevant sub-goals. However, that exploration needs to be balanced with the need for exploiting the learned policy. This paper explores the idea of combining exploration with auxiliary task learning using General Value Functions (GVFs) and a directed exploration strategy. We provide a simple way to learn options (sequences of actions) instead of having to handcraft them, and demonstrate the performance advantage in three navigation tasks.
Revisiting State Augmentation methods for Reinforcement Learning with Stochastic Delays
Aug 17, 2021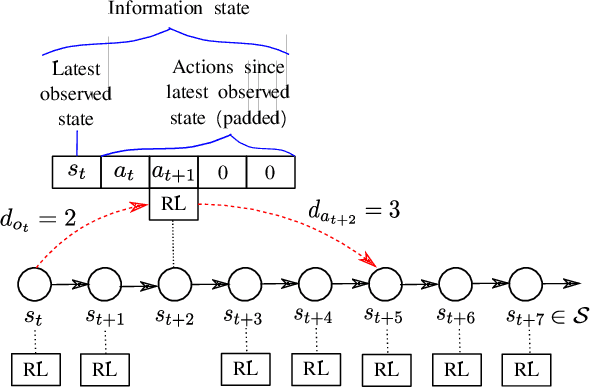
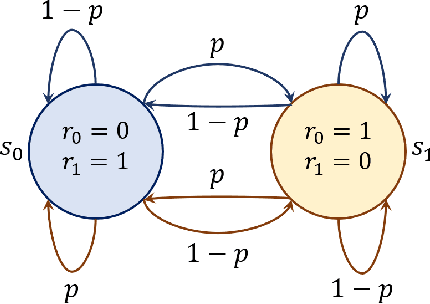
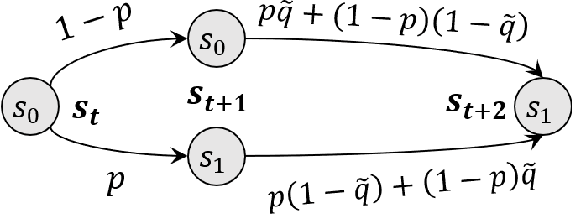
Several real-world scenarios, such as remote control and sensing, are comprised of action and observation delays. The presence of delays degrades the performance of reinforcement learning (RL) algorithms, often to such an extent that algorithms fail to learn anything substantial. This paper formally describes the notion of Markov Decision Processes (MDPs) with stochastic delays and shows that delayed MDPs can be transformed into equivalent standard MDPs (without delays) with significantly simplified cost structure. We employ this equivalence to derive a model-free Delay-Resolved RL framework and show that even a simple RL algorithm built upon this framework achieves near-optimal rewards in environments with stochastic delays in actions and observations. The delay-resolved deep Q-network (DRDQN) algorithm is bench-marked on a variety of environments comprising of multi-step and stochastic delays and results in better performance, both in terms of achieving near-optimal rewards and minimizing the computational overhead thereof, with respect to the currently established algorithms.