 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
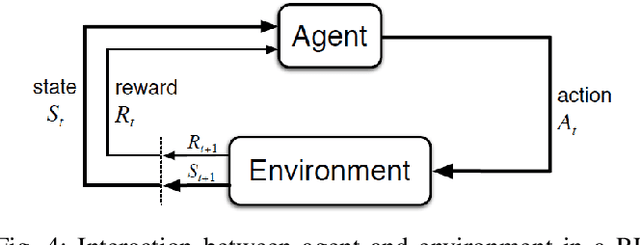
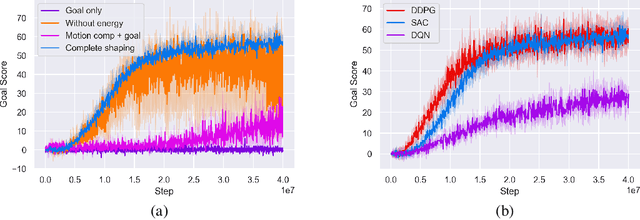
Add to EdgePlanning the path with Reinforcement Learning: Optimal Robot Motion Planning in RoboCup Small Size League Environments
Apr 23, 2024This work investigates the potential of Reinforcement Learning (RL) to tackle robot motion planning challenges in the dynamic RoboCup Small Size League (SSL). Using a heuristic control approach, we evaluate RL's effectiveness in obstacle-free and single-obstacle path-planning environments. Ablation studies reveal significant performance improvements. Our method achieved a 60% time gain in obstacle-free environments compared to baseline algorithms. Additionally, our findings demonstrated dynamic obstacle avoidance capabilities, adeptly navigating around moving blocks. These findings highlight the potential of RL to enhance robot motion planning in the challenging and unpredictable SSL environment.
Bridging the Gap Between Offline and Online Reinforcement Learning Evaluation Methodologies
Dec 15, 2022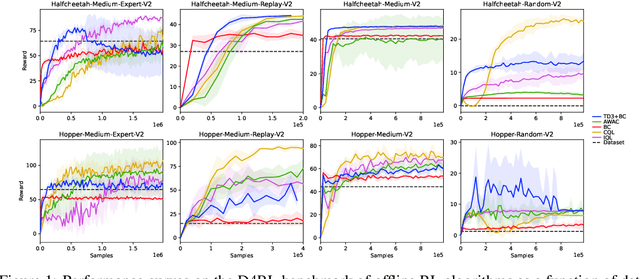
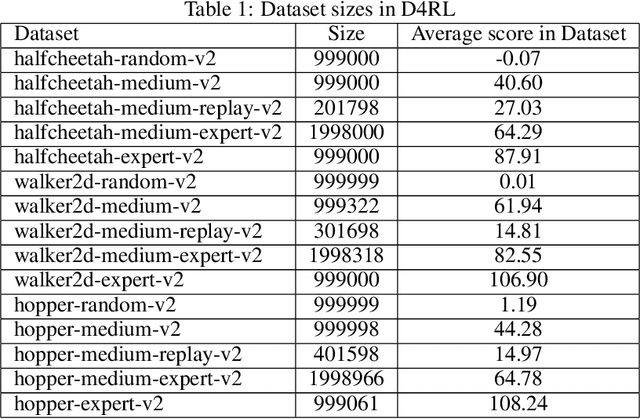

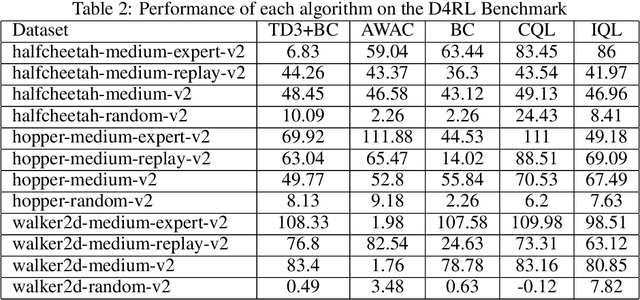
Reinforcement learning (RL) has shown great promise with algorithms learning in environments with large state and action spaces purely from scalar reward signals. A crucial challenge for current deep RL algorithms is that they require a tremendous amount of environment interactions for learning. This can be infeasible in situations where such interactions are expensive; such as in robotics. Offline RL algorithms try to address this issue by bootstrapping the learning process from existing logged data without needing to interact with the environment from the very beginning. While online RL algorithms are typically evaluated as a function of the number of environment interactions, there exists no single established protocol for evaluating offline RL methods.In this paper, we propose a sequential approach to evaluate offline RL algorithms as a function of the training set size and thus by their data efficiency. Sequential evaluation provides valuable insights into the data efficiency of the learning process and the robustness of algorithms to distribution changes in the dataset while also harmonizing the visualization of the offline and online learning phases. Our approach is generally applicable and easy to implement. We compare several existing offline RL algorithms using this approach and present insights from a variety of tasks and offline datasets.
Prioritizing Samples in Reinforcement Learning with Reducible Loss
Aug 22, 2022
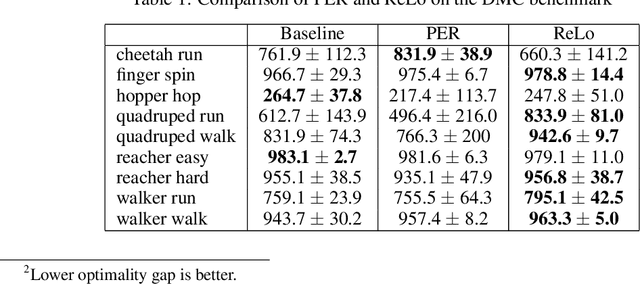


Most reinforcement learning algorithms take advantage of an experience replay buffer to repeatedly train on samples the agent has observed in the past. This prevents catastrophic forgetting, however simply assigning equal importance to each of the samples is a naive strategy. In this paper, we propose a method to prioritize samples based on how much we can learn from a sample. We define the learn-ability of a sample as the steady decrease of the training loss associated with this sample over time. We develop an algorithm to prioritize samples with high learn-ability, while assigning lower priority to those that are hard-to-learn, typically caused by noise or stochasticity. We empirically show that our method is more robust than random sampling and also better than just prioritizing with respect to the training loss, i.e. the temporal difference loss, which is used in vanilla prioritized experience replay.
rSoccer: A Framework for Studying Reinforcement Learning in Small and Very Small Size Robot Soccer
Jun 15, 2021

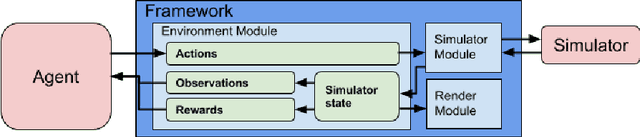
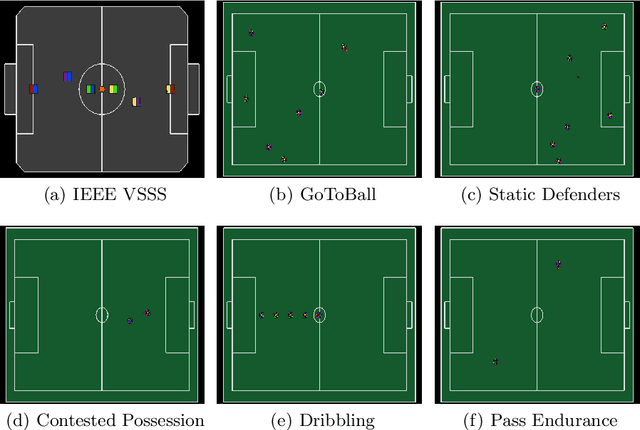
Reinforcement learning is an active research area with a vast number of applications in robotics, and the RoboCup competition is an interesting environment for studying and evaluating reinforcement learning methods. A known difficulty in applying reinforcement learning to robotics is the high number of experience samples required, being the use of simulated environments for training the agents followed by transfer learning to real-world (sim-to-real) a viable path. This article introduces an open-source simulator for the IEEE Very Small Size Soccer and the Small Size League optimized for reinforcement learning experiments. We also propose a framework for creating OpenAI Gym environments with a set of benchmarks tasks for evaluating single-agent and multi-agent robot soccer skills. We then demonstrate the learning capabilities of two state-of-the-art reinforcement learning methods as well as their limitations in certain scenarios introduced in this framework. We believe this will make it easier for more teams to compete in these categories using end-to-end reinforcement learning approaches and further develop this research area.
An analysis of Reinforcement Learning applied to Coach task in IEEE Very Small Size Soccer
Nov 23, 2020
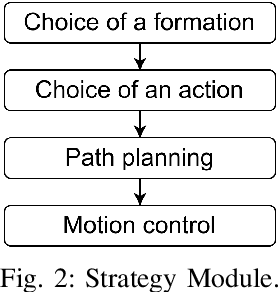
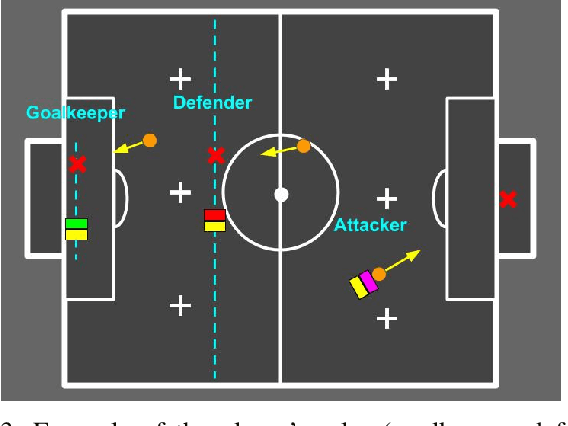
The IEEE Very Small Size Soccer (VSSS) is a robot soccer competition in which two teams of three small robots play against each other. Traditionally, a deterministic coach agent will choose the most suitable strategy and formation for each adversary's strategy. Therefore, the role of a coach is of great importance to the game. In this sense, this paper proposes an end-to-end approach for the coaching task based on Reinforcement Learning (RL). The proposed system processes the information during the simulated matches to learn an optimal policy that chooses the current formation, depending on the opponent and game conditions. We trained two RL policies against three different teams (balanced, offensive, and heavily offensive) in a simulated environment. Our results were assessed against one of the top teams of the VSSS league, showing promising results after achieving a win/loss ratio of approximately 2.0.
A Framework for Studying Reinforcement Learning and Sim-to-Real in Robot Soccer
Aug 18, 2020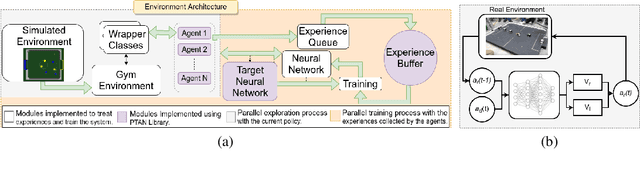
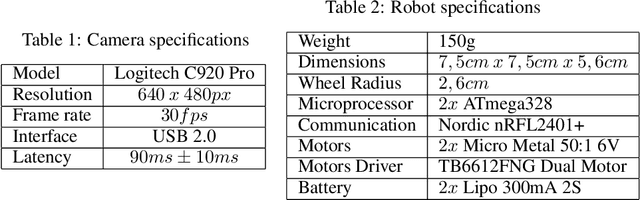

This article introduces an open framework, called VSSS-RL, for studying Reinforcement Learning (RL) and sim-to-real in robot soccer, focusing on the IEEE Very Small Size Soccer (VSSS) league. We propose a simulated environment in which continuous or discrete control policies can be trained to control the complete behavior of soccer agents and a sim-to-real method based on domain adaptation to adapt the obtained policies to real robots. Our results show that the trained policies learned a broad repertoire of behaviors that are difficult to implement with handcrafted control policies. With VSSS-RL, we were able to beat human-designed policies in the 2019 Latin American Robotics Competition (LARC), achieving 4th place out of 21 teams, being the first to apply Reinforcement Learning (RL) successfully in this competition. Both environment and hardware specifications are available open-source to allow reproducibility of our results and further studies.
Deep Categorization with Semi-Supervised Self-Organizing Maps
Jun 17, 2020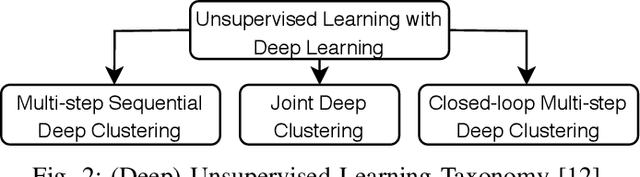
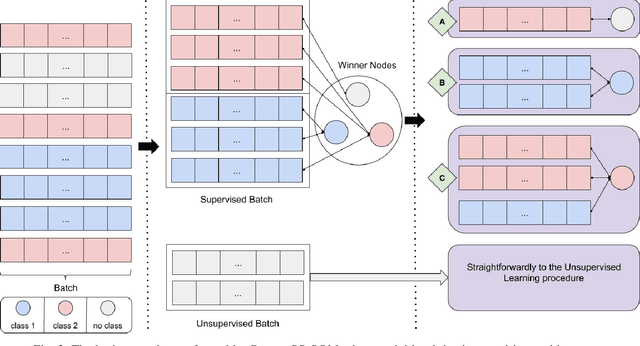
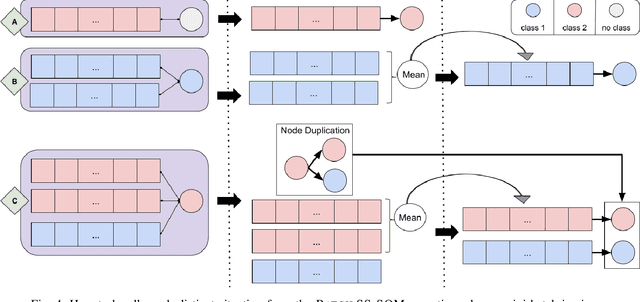

Nowadays, with the advance of technology, there is an increasing amount of unstructured data being generated every day. However, it is a painful job to label and organize it. Labeling is an expensive, time-consuming, and difficult task. It is usually done manually, which collaborates with the incorporation of noise and errors to the data. Hence, it is of great importance to developing intelligent models that can benefit from both labeled and unlabeled data. Currently, works on unsupervised and semi-supervised learning are still being overshadowed by the successes of purely supervised learning. However, it is expected that they become far more important in the longer term. This article presents a semi-supervised model, called Batch Semi-Supervised Self-Organizing Map (Batch SS-SOM), which is an extension of a SOM incorporating some advances that came with the rise of Deep Learning, such as batch training. The results show that Batch SS-SOM is a good option for semi-supervised classification and clustering. It performs well in terms of accuracy and clustering error, even with a small number of labeled samples, as well as when presented to unsupervised data, and shows competitive results in transfer learning scenarios in traditional image classification benchmark datasets.
Learning to Play Soccer by Reinforcement and Applying Sim-to-Real to Compete in the Real World
Mar 24, 2020
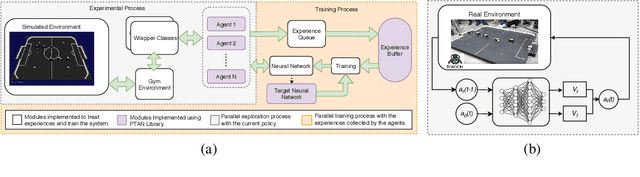
This work presents an application of Reinforcement Learning (RL) for the complete control of real soccer robots of the IEEE Very Small Size Soccer (VSSS), a traditional league in the Latin American Robotics Competition (LARC). In the VSSS league, two teams of three small robots play against each other. We propose a simulated environment in which continuous or discrete control policies can be trained, and a Sim-to-Real method to allow using the obtained policies to control a robot in the real world. The results show that the learned policies display a broad repertoire of behaviors that are difficult to specify by hand. This approach, called VSSS-RL, was able to beat the human-designed policy for the striker of the team ranked 3rd place in the 2018 LARC, in 1-vs-1 matches.
MOEA/D with Uniformly Randomly Adaptive Weights
Aug 15, 2019
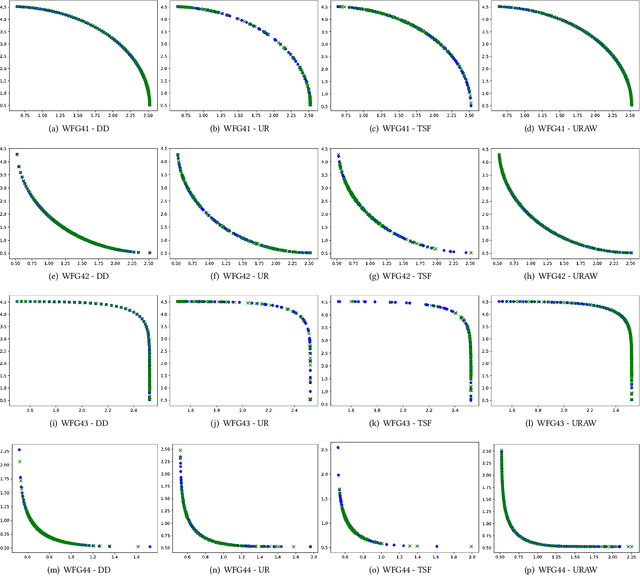
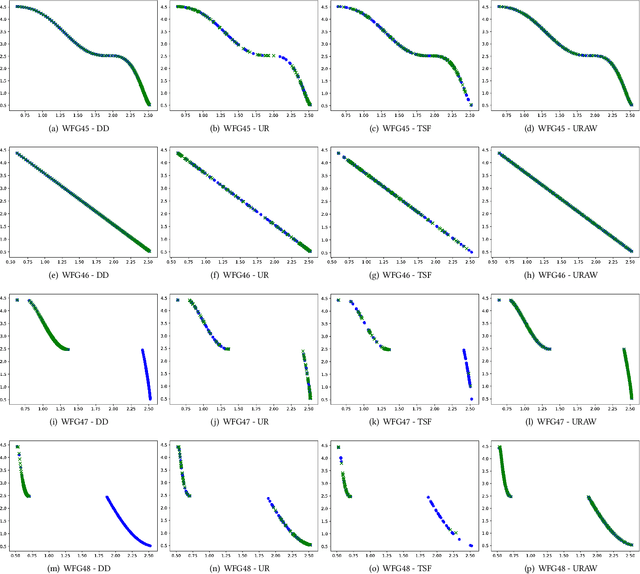
When working with decomposition-based algorithms, an appropriate set of weights might improve quality of the final solution. A set of uniformly distributed weights usually leads to well-distributed solutions on a Pareto front. However, there are two main difficulties with this approach. Firstly, it may fail depending on the problem geometry. Secondly, the population size becomes not flexible as the number of objectives increases. In this paper, we propose the MOEA/D with Uniformly Randomly Adaptive Weights (MOEA/DURAW) which uses the Uniformly Randomly method as an approach to subproblems generation, allowing a flexible population size even when working with many objective problems. During the evolutionary process, MOEA/D-URAW adds and removes subproblems as a function of the sparsity level of the population. Moreover, instead of requiring assumptions about the Pareto front shape, our method adapts its weights to the shape of the problem during the evolutionary process. Experimental results using WFG41-48 problem classes, with different Pareto front shapes, shows that the present method presents better or equal results in 77.5% of the problems evaluated from 2 to 6 objectives when compared with state-of-the-art methods in the literature.
A Semi-Supervised Self-Organizing Map with Adaptive Local Thresholds
Jul 01, 2019


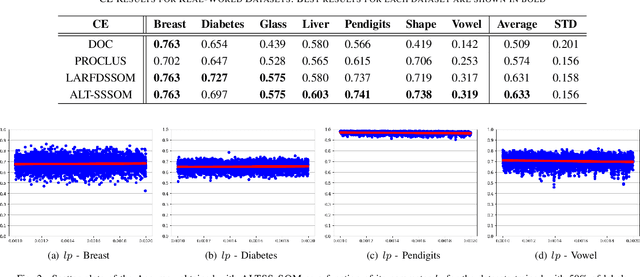
In the recent years, there is a growing interest in semi-supervised learning, since, in many learning tasks, there is a plentiful supply of unlabeled data, but insufficient labeled ones. Hence, Semi-Supervised learning models can benefit from both types of data to improve the obtained performance. Also, it is important to develop methods that are easy to parameterize in a way that is robust to the different characteristics of the data at hand. This article presents a new method based on Self-Organizing Map (SOM) for clustering and classification, called Adaptive Local Thresholds Semi-Supervised Self-Organizing Map (ALTSS-SOM). It can dynamically switch between two forms of learning at training time, according to the availability of labels, as in previous models, and can automatically adjust itself to the local variance observed in each data cluster. The results show that the ALTSS-SOM surpass the performance of other semi-supervised methods in terms of classification, and other pure clustering methods when there are no labels available, being also less sensitive than previous methods to the parameters values.