 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContrastive meta-domain adaptation for robust skin lesion classification across clinical and acquisition conditions
Feb 23, 2026Deep learning models for dermatological image analysis remain sensitive to acquisition variability and domain-specific visual characteristics, leading to performance degradation when deployed in clinical settings. We investigate how visual artifacts and domain shifts affect deep learning-based skin lesion classification. We propose an adaptation strategy, grounded in the idea of visual meta-domains, that transfers visual representations from larger dermoscopic datasets into clinical image domains, thereby improving generalization robustness. Experiments across multiple dermatology datasets show consistent gains in classification performance and reduced gaps between dermoscopic and clinical images. These results emphasize the importance of domain-aware training for deployable systems.
DerMAE: Improving skin lesion classification through conditioned latent diffusion and MAE distillation
Feb 23, 2026Skin lesion classification datasets often suffer from severe class imbalance, with malignant cases significantly underrepresented, leading to biased decision boundaries during deep learning training. We address this challenge using class-conditioned diffusion models to generate synthetic dermatological images, followed by self-supervised MAE pretraining to enable huge ViT models to learn robust, domain-relevant features. To support deployment in practical clinical settings, where lightweight models are required, we apply knowledge distillation to transfer these representations to a smaller ViT student suitable for mobile devices. Our results show that MAE pretraining on synthetic data, combined with distillation, improves classification performance while enabling efficient on-device inference for practical clinical use.
Single Tensor Cell Segmentation using Scalar Field Representations
Nov 17, 2025



We investigate image segmentation of cells under the lens of scalar fields. Our goal is to learn a continuous scalar field on image domains such that its segmentation produces robust instances for cells present in images. This field is a function parameterized by the trained network, and its segmentation is realized by the watershed method. The fields we experiment with are solutions to the Poisson partial differential equation and a diffusion mimicking the steady-state solution of the heat equation. These solutions are obtained by minimizing just the field residuals, no regularization is needed, providing a robust regression capable of diminishing the adverse impacts of outliers in the training data and allowing for sharp cell boundaries. A single tensor is all that is needed to train a \unet\ thus simplifying implementation, lowering training and inference times, hence reducing energy consumption, and requiring a small memory footprint, all attractive features in edge computing. We present competitive results on public datasets from the literature and show that our novel, simple yet geometrically insightful approach can achieve excellent cell segmentation results.
DermAI: Clinical dermatology acquisition through quality-driven image collection for AI classification in mobile
Nov 14, 2025AI-based dermatology adoption remains limited by biased datasets, variable image quality, and limited validation. We introduce DermAI, a lightweight, smartphone-based application that enables real-time capture, annotation, and classification of skin lesions during routine consultations. Unlike prior dermoscopy-focused tools, DermAI performs on-device quality checks, and local model adaptation. The DermAI clinical dataset, encompasses a wide range of skin tones, ethinicity and source devices. In preliminary experiments, models trained on public datasets failed to generalize to our samples, while fine-tuning with local data improved performance. These results highlight the importance of standardized, diverse data collection aligned with healthcare needs and oriented to machine learning development.
An analysis of data variation and bias in image-based dermatological datasets for machine learning classification
Jan 15, 2025AI algorithms have become valuable in aiding professionals in healthcare. The increasing confidence obtained by these models is helpful in critical decision demands. In clinical dermatology, classification models can detect malignant lesions on patients' skin using only RGB images as input. However, most learning-based methods employ data acquired from dermoscopic datasets on training, which are large and validated by a gold standard. Clinical models aim to deal with classification on users' smartphone cameras that do not contain the corresponding resolution provided by dermoscopy. Also, clinical applications bring new challenges. It can contain captures from uncontrolled environments, skin tone variations, viewpoint changes, noises in data and labels, and unbalanced classes. A possible alternative would be to use transfer learning to deal with the clinical images. However, as the number of samples is low, it can cause degradations on the model's performance; the source distribution used in training differs from the test set. This work aims to evaluate the gap between dermoscopic and clinical samples and understand how the dataset variations impact training. It assesses the main differences between distributions that disturb the model's prediction. Finally, from experiments on different architectures, we argue how to combine the data from divergent distributions, decreasing the impact on the model's final accuracy.
An analysis of Reinforcement Learning applied to Coach task in IEEE Very Small Size Soccer
Nov 23, 2020
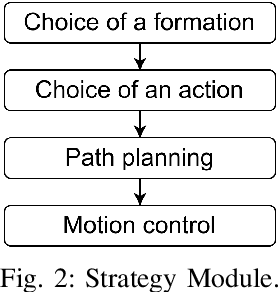
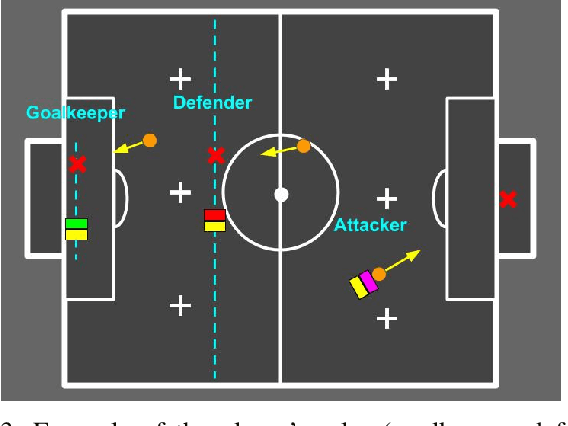
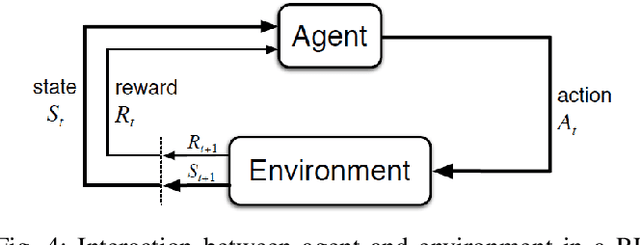
The IEEE Very Small Size Soccer (VSSS) is a robot soccer competition in which two teams of three small robots play against each other. Traditionally, a deterministic coach agent will choose the most suitable strategy and formation for each adversary's strategy. Therefore, the role of a coach is of great importance to the game. In this sense, this paper proposes an end-to-end approach for the coaching task based on Reinforcement Learning (RL). The proposed system processes the information during the simulated matches to learn an optimal policy that chooses the current formation, depending on the opponent and game conditions. We trained two RL policies against three different teams (balanced, offensive, and heavily offensive) in a simulated environment. Our results were assessed against one of the top teams of the VSSS league, showing promising results after achieving a win/loss ratio of approximately 2.0.
Deep Metric Structured Learning For Facial Expression Recognition
Jan 18, 2020

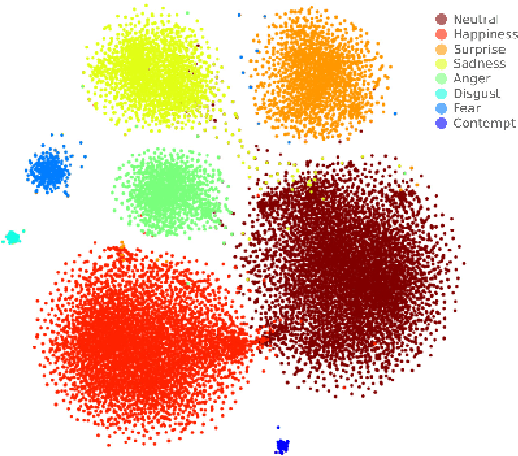
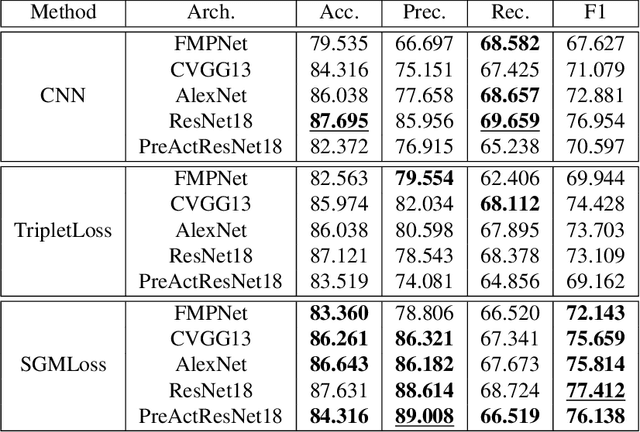
We propose a deep metric learning model to create embedded sub-spaces with a well defined structure. A new loss function that imposes Gaussian structures on the output space is introduced to create these sub-spaces thus shaping the distribution of the data. Having a mixture of Gaussians solution space is advantageous given its simplified and well established structure. It allows fast discovering of classes within classes and the identification of mean representatives at the centroids of individual classes. We also propose a new semi-supervised method to create sub-classes. We illustrate our methods on the facial expression recognition problem and validate results on the FER+, AffectNet, Extended Cohn-Kanade (CK+), BU-3DFE, and JAFFE datasets. We experimentally demonstrate that the learned embedding can be successfully used for various applications including expression retrieval and emotion recognition.
J Regularization Improves Imbalanced Multiclass Segmentation
Oct 22, 2019
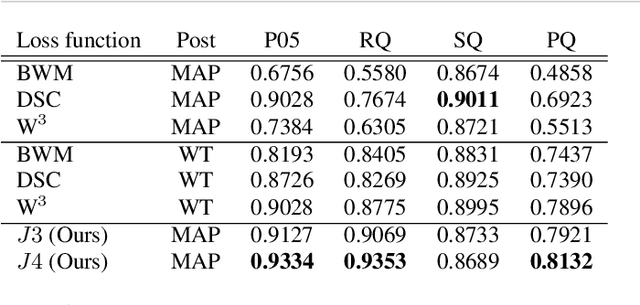
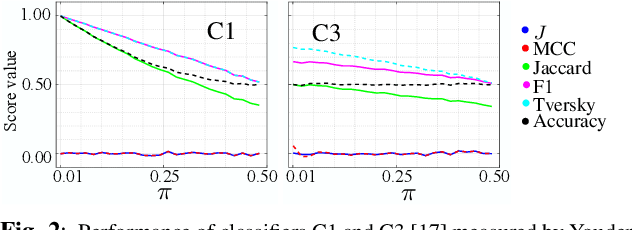
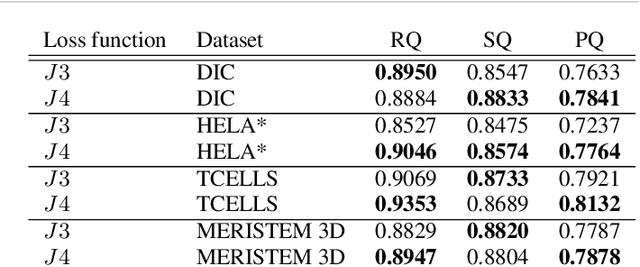
We propose a new loss formulation to further advance the multiclass segmentation of cluttered cells under weakly supervised conditions. We improve the separation of touching and immediate cells, obtaining sharp segmentation boundaries with high adequacy, when we add Youden's $J$ statistic regularization term to the cross entropy loss. This regularization intrinsically supports class imbalance thus eliminating the necessity of explicitly using weights to balance training. Simulations demonstrate this capability and show how the regularization leads to better results by helping advancing the optimization when cross entropy stalls. We build upon our previous work on multiclass segmentation by adding yet another training class representing gaps between adjacent cells. This addition helps the classifier identify narrow gaps as background and no longer as touching regions. We present results of our methods for 2D and 3D images, from bright field to confocal stacks containing different types of cells, and we show that they accurately segment individual cells after training with a limited number of annotated images, some of which are poorly annotated.
A Multiple Source Hourglass Deep Network for Multi-Focus Image Fusion
Aug 28, 2019
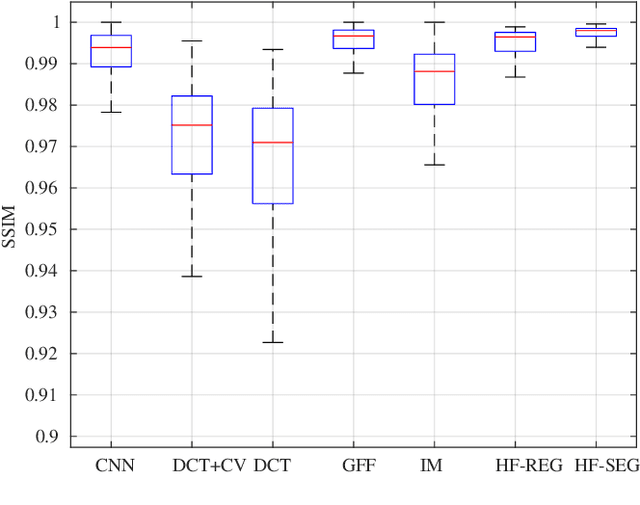

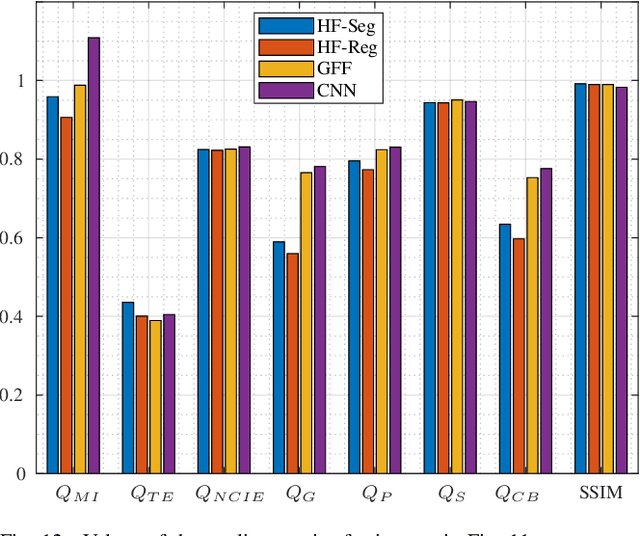
Multi-Focus Image Fusion seeks to improve the quality of an acquired burst of images with different focus planes. For solving the task, an activity level measurement and a fusion rule are typically established to select and fuse the most relevant information from the sources. However, the design of this kind of method by hand is really hard and sometimes restricted to solution spaces where the optimal all-in-focus images are not contained. Then, we propose here two fast and straightforward approaches for image fusion based on deep neural networks. Our solution uses a multiple source Hourglass architecture trained in an end-to-end fashion. Models are data-driven and can be easily generalized for other kinds of fusion problems. A segmentation approach is used for recognition of the focus map, while the weighted average rule is used for fusion. We designed a training loss function for our regression-based fusion function, which allows the network to learn both the activity level measurement and the fusion rule. Experimental results show our approach has comparable results to the state-of-the-art methods with a 60X increase of computational efficiency for 520X520 resolution images.
A Weakly Supervised Method for Instance Segmentation of Biological Cells
Aug 26, 2019
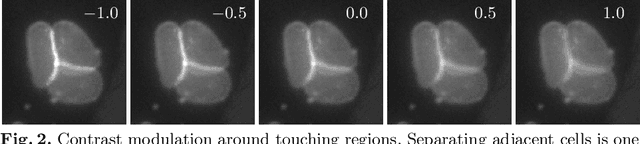
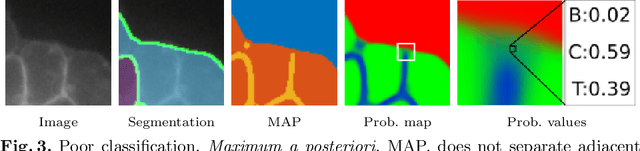

We present a weakly supervised deep learning method to perform instance segmentation of cells present in microscopy images. Annotation of biomedical images in the lab can be scarce, incomplete, and inaccurate. This is of concern when supervised learning is used for image analysis as the discriminative power of a learning model might be compromised in these situations. To overcome the curse of poor labeling, our method focuses on three aspects to improve learning: i) we propose a loss function operating in three classes to facilitate separating adjacent cells and to drive the optimizer to properly classify underrepresented regions; ii) a contour-aware weight map model is introduced to strengthen contour detection while improving the network generalization capacity; and iii) we augment data by carefully modulating local intensities on edges shared by adjoining regions and to account for possibly weak signals on these edges. Generated probability maps are segmented using different methods, with the watershed based one generally offering the best solutions, specially in those regions where the prevalence of a single class is not clear. The combination of these contributions allows segmenting individual cells on challenging images. We demonstrate our methods in sparse and crowded cell images, showing improvements in the learning process for a fixed network architecture.