 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivacy-Preserving Person Detection Using Low-Resolution Infrared Cameras
Sep 22, 2022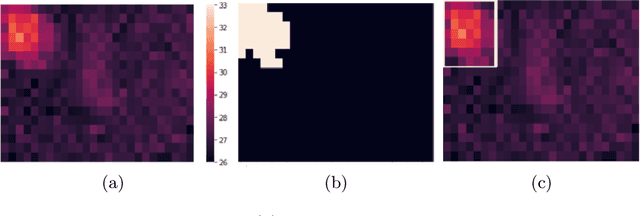
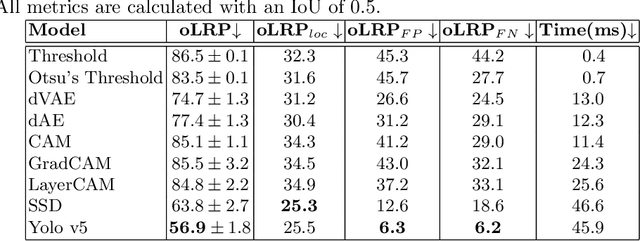
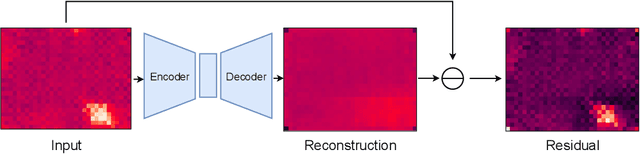
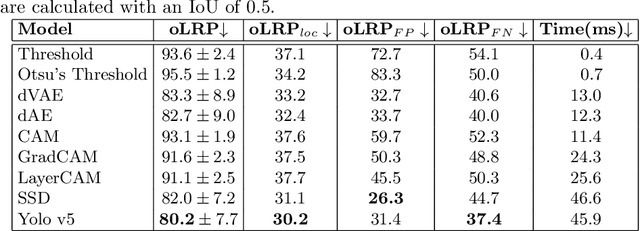
In intelligent building management, knowing the number of people and their location in a room are important for better control of its illumination, ventilation, and heating with reduced costs and improved comfort. This is typically achieved by detecting people using compact embedded devices that are installed on the room's ceiling, and that integrate low-resolution infrared camera, which conceals each person's identity. However, for accurate detection, state-of-the-art deep learning models still require supervised training using a large annotated dataset of images. In this paper, we investigate cost-effective methods that are suitable for person detection based on low-resolution infrared images. Results indicate that for such images, we can reduce the amount of supervision and computation, while still achieving a high level of detection accuracy. Going from single-shot detectors that require bounding box annotations of each person in an image, to auto-encoders that only rely on unlabelled images that do not contain people, allows for considerable savings in terms of annotation costs, and for models with lower computational costs. We validate these experimental findings on two challenging top-view datasets with low-resolution infrared images.
A Multiple Source Hourglass Deep Network for Multi-Focus Image Fusion
Aug 28, 2019
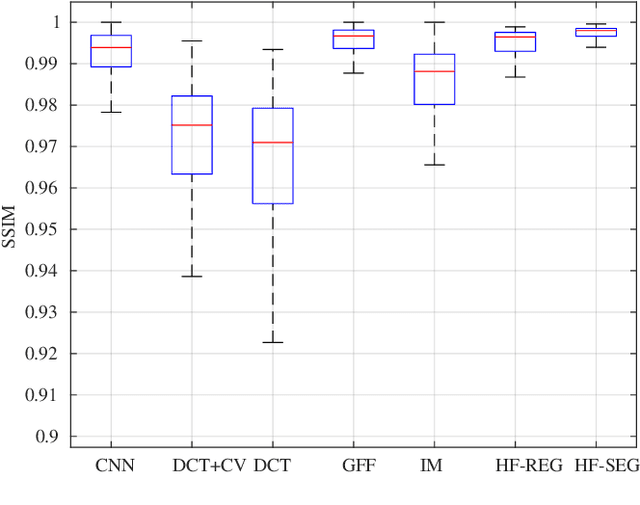

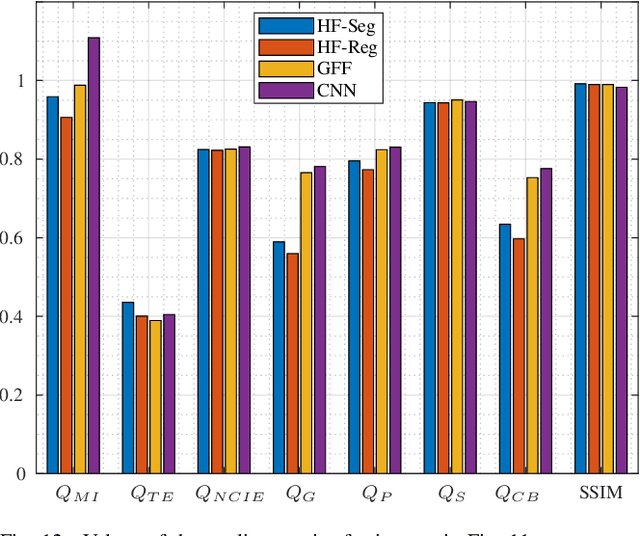
Multi-Focus Image Fusion seeks to improve the quality of an acquired burst of images with different focus planes. For solving the task, an activity level measurement and a fusion rule are typically established to select and fuse the most relevant information from the sources. However, the design of this kind of method by hand is really hard and sometimes restricted to solution spaces where the optimal all-in-focus images are not contained. Then, we propose here two fast and straightforward approaches for image fusion based on deep neural networks. Our solution uses a multiple source Hourglass architecture trained in an end-to-end fashion. Models are data-driven and can be easily generalized for other kinds of fusion problems. A segmentation approach is used for recognition of the focus map, while the weighted average rule is used for fusion. We designed a training loss function for our regression-based fusion function, which allows the network to learn both the activity level measurement and the fusion rule. Experimental results show our approach has comparable results to the state-of-the-art methods with a 60X increase of computational efficiency for 520X520 resolution images.