 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLT-Soups: Bridging Head and Tail Classes via Subsampled Model Soups
Nov 11, 2025Real-world datasets typically exhibit long-tailed (LT) distributions, where a few head classes dominate and many tail classes are severely underrepresented. While recent work shows that parameter-efficient fine-tuning (PEFT) methods like LoRA and AdaptFormer preserve tail-class performance on foundation models such as CLIP, we find that they do so at the cost of head-class accuracy. We identify the head-tail ratio, the proportion of head to tail classes, as a crucial but overlooked factor influencing this trade-off. Through controlled experiments on CIFAR100 with varying imbalance ratio ($ρ$) and head-tail ratio ($η$), we show that PEFT excels in tail-heavy scenarios but degrades in more balanced and head-heavy distributions. To overcome these limitations, we propose LT-Soups, a two-stage model soups framework designed to generalize across diverse LT regimes. In the first stage, LT-Soups averages models fine-tuned on balanced subsets to reduce head-class bias; in the second, it fine-tunes only the classifier on the full dataset to restore head-class accuracy. Experiments across six benchmark datasets show that LT-Soups achieves superior trade-offs compared to both PEFT and traditional model soups across a wide range of imbalance regimes.
Revisiting Mixout: An Overlooked Path to Robust Finetuning
Oct 08, 2025Finetuning vision foundation models often improves in-domain accuracy but comes at the cost of robustness under distribution shift. We revisit Mixout, a stochastic regularizer that intermittently replaces finetuned weights with their pretrained reference, through the lens of a single-run, weight-sharing implicit ensemble. This perspective reveals three key levers that govern robustness: the \emph{masking anchor}, \emph{resampling frequency}, and \emph{mask sparsity}. Guided by this analysis, we introduce GMixout, which (i) replaces the fixed anchor with an exponential moving-average snapshot that adapts during training, and (ii) regulates masking period via an explicit resampling-frequency hyperparameter. Our sparse-kernel implementation updates only a small fraction of parameters with no inference-time overhead, enabling training on consumer-grade GPUs. Experiments on benchmarks covering covariate shift, corruption, and class imbalance, ImageNet / ImageNet-LT, DomainNet, iWildCam, and CIFAR100-C, GMixout consistently improves in-domain accuracy beyond zero-shot performance while surpassing both Model Soups and strong parameter-efficient finetuning baselines under distribution shift.
High-Rate Mixout: Revisiting Mixout for Robust Domain Generalization
Oct 08, 2025Ensembling fine-tuned models initialized from powerful pre-trained weights is a common strategy to improve robustness under distribution shifts, but it comes with substantial computational costs due to the need to train and store multiple models. Dropout offers a lightweight alternative by simulating ensembles through random neuron deactivation; however, when applied to pre-trained models, it tends to over-regularize and disrupt critical representations necessary for generalization. In this work, we investigate Mixout, a stochastic regularization technique that provides an alternative to Dropout for domain generalization. Rather than deactivating neurons, Mixout mitigates overfitting by probabilistically swapping a subset of fine-tuned weights with their pre-trained counterparts during training, thereby maintaining a balance between adaptation and retention of prior knowledge. Our study reveals that achieving strong performance with Mixout on domain generalization benchmarks requires a notably high masking probability of 0.9 for ViTs and 0.8 for ResNets. While this may seem like a simple adjustment, it yields two key advantages for domain generalization: (1) higher masking rates more strongly penalize deviations from the pre-trained parameters, promoting better generalization to unseen domains; and (2) high-rate masking substantially reduces computational overhead, cutting gradient computation by up to 45% and gradient memory usage by up to 90%. Experiments across five domain generalization benchmarks, PACS, VLCS, OfficeHome, TerraIncognita, and DomainNet, using ResNet and ViT architectures, show that our approach, High-rate Mixout, achieves out-of-domain accuracy comparable to ensemble-based methods while significantly reducing training costs.
Distilling semantically aware orders for autoregressive image generation
Apr 23, 2025Autoregressive patch-based image generation has recently shown competitive results in terms of image quality and scalability. It can also be easily integrated and scaled within Vision-Language models. Nevertheless, autoregressive models require a defined order for patch generation. While a natural order based on the dictation of the words makes sense for text generation, there is no inherent generation order that exists for image generation. Traditionally, a raster-scan order (from top-left to bottom-right) guides autoregressive image generation models. In this paper, we argue that this order is suboptimal, as it fails to respect the causality of the image content: for instance, when conditioned on a visual description of a sunset, an autoregressive model may generate clouds before the sun, even though the color of clouds should depend on the color of the sun and not the inverse. In this work, we show that first by training a model to generate patches in any-given-order, we can infer both the content and the location (order) of each patch during generation. Secondly, we use these extracted orders to finetune the any-given-order model to produce better-quality images. Through our experiments, we show on two datasets that this new generation method produces better images than the traditional raster-scan approach, with similar training costs and no extra annotations.
Source-Free Domain Adaptation for YOLO Object Detection
Sep 25, 2024
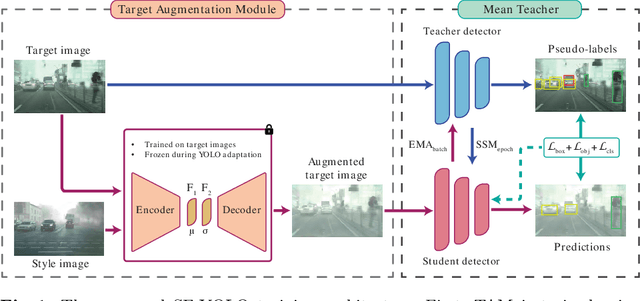

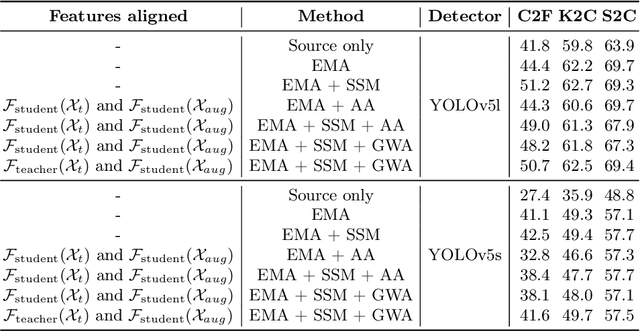
Source-free domain adaptation (SFDA) is a challenging problem in object detection, where a pre-trained source model is adapted to a new target domain without using any source domain data for privacy and efficiency reasons. Most state-of-the-art SFDA methods for object detection have been proposed for Faster-RCNN, a detector that is known to have high computational complexity. This paper focuses on domain adaptation techniques for real-world vision systems, particularly for the YOLO family of single-shot detectors known for their fast baselines and practical applications. Our proposed SFDA method - Source-Free YOLO (SF-YOLO) - relies on a teacher-student framework in which the student receives images with a learned, target domain-specific augmentation, allowing the model to be trained with only unlabeled target data and without requiring feature alignment. A challenge with self-training using a mean-teacher architecture in the absence of labels is the rapid decline of accuracy due to noisy or drifting pseudo-labels. To address this issue, a teacher-to-student communication mechanism is introduced to help stabilize the training and reduce the reliance on annotated target data for model selection. Despite its simplicity, our approach is competitive with state-of-the-art detectors on several challenging benchmark datasets, even sometimes outperforming methods that use source data for adaptation.
WASH: Train your Ensemble with Communication-Efficient Weight Shuffling, then Average
May 27, 2024



The performance of deep neural networks is enhanced by ensemble methods, which average the output of several models. However, this comes at an increased cost at inference. Weight averaging methods aim at balancing the generalization of ensembling and the inference speed of a single model by averaging the parameters of an ensemble of models. Yet, naive averaging results in poor performance as models converge to different loss basins, and aligning the models to improve the performance of the average is challenging. Alternatively, inspired by distributed training, methods like DART and PAPA have been proposed to train several models in parallel such that they will end up in the same basin, resulting in good averaging accuracy. However, these methods either compromise ensembling accuracy or demand significant communication between models during training. In this paper, we introduce WASH, a novel distributed method for training model ensembles for weight averaging that achieves state-of-the-art image classification accuracy. WASH maintains models within the same basin by randomly shuffling a small percentage of weights during training, resulting in diverse models and lower communication costs compared to standard parameter averaging methods.
Modality Translation for Object Detection Adaptation Without Forgetting Prior Knowledge
Apr 11, 2024



A common practice in deep learning consists of training large neural networks on massive datasets to perform accurately for different domains and tasks. While this methodology may work well in numerous application areas, it only applies across modalities due to a larger distribution shift in data captured using different sensors. This paper focuses on the problem of adapting a large object detection model to one or multiple modalities while being efficient. To do so, we propose ModTr as an alternative to the common approach of fine-tuning large models. ModTr consists of adapting the input with a small transformation network trained to minimize the detection loss directly. The original model can therefore work on the translated inputs without any further change or fine-tuning to its parameters. Experimental results on translating from IR to RGB images on two well-known datasets show that this simple ModTr approach provides detectors that can perform comparably or better than the standard fine-tuning without forgetting the original knowledge. This opens the doors to a more flexible and efficient service-based detection pipeline in which, instead of using a different detector for each modality, a unique and unaltered server is constantly running, where multiple modalities with the corresponding translations can query it. Code: https://github.com/heitorrapela/ModTr.
Domain Generalization by Rejecting Extreme Augmentations
Oct 10, 2023



Data augmentation is one of the most effective techniques for regularizing deep learning models and improving their recognition performance in a variety of tasks and domains. However, this holds for standard in-domain settings, in which the training and test data follow the same distribution. For the out-of-domain case, where the test data follow a different and unknown distribution, the best recipe for data augmentation is unclear. In this paper, we show that for out-of-domain and domain generalization settings, data augmentation can provide a conspicuous and robust improvement in performance. To do that, we propose a simple training procedure: (i) use uniform sampling on standard data augmentation transformations; (ii) increase the strength transformations to account for the higher data variance expected when working out-of-domain, and (iii) devise a new reward function to reject extreme transformations that can harm the training. With this procedure, our data augmentation scheme achieves a level of accuracy that is comparable to or better than state-of-the-art methods on benchmark domain generalization datasets. Code: \url{https://github.com/Masseeh/DCAug}
HalluciDet: Hallucinating RGB Modality for Person Detection Through Privileged Information
Oct 07, 2023A powerful way to adapt a visual recognition model to a new domain is through image translation. However, common image translation approaches only focus on generating data from the same distribution of the target domain. In visual recognition tasks with complex images, such as pedestrian detection on aerial images with a large cross-modal shift in data distribution from Infrared (IR) to RGB images, a translation focused on generation might lead to poor performance as the loss focuses on irrelevant details for the task. In this paper, we propose HalluciDet, an IR-RGB image translation model for object detection that, instead of focusing on reconstructing the original image on the IR modality, is guided directly on reducing the detection loss of an RGB detector, and therefore avoids the need to access RGB data. This model produces a new image representation that enhances the object of interest in the scene and greatly improves detection performance. We empirically compare our approach against state-of-the-art image translation methods as well as with the commonly used fine-tuning on IR, and show that our method improves detection accuracy in most cases, by exploiting the privileged information encoded in a pre-trained RGB detector.
Re-basin via implicit Sinkhorn differentiation
Dec 22, 2022The recent emergence of new algorithms for permuting models into functionally equivalent regions of the solution space has shed some light on the complexity of error surfaces, and some promising properties like mode connectivity. However, finding the right permutation is challenging, and current optimization techniques are not differentiable, which makes it difficult to integrate into a gradient-based optimization, and often leads to sub-optimal solutions. In this paper, we propose a Sinkhorn re-basin network with the ability to obtain the transportation plan that better suits a given objective. Unlike the current state-of-art, our method is differentiable and, therefore, easy to adapt to any task within the deep learning domain. Furthermore, we show the advantage of our re-basin method by proposing a new cost function that allows performing incremental learning by exploiting the linear mode connectivity property. The benefit of our method is compared against similar approaches from the literature, under several conditions for both optimal transport finding and linear mode connectivity. The effectiveness of our continual learning method based on re-basin is also shown for several common benchmark datasets, providing experimental results that are competitive with state-of-art results from the literature.