 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSource-Free Domain Adaptation for YOLO Object Detection
Sep 25, 2024
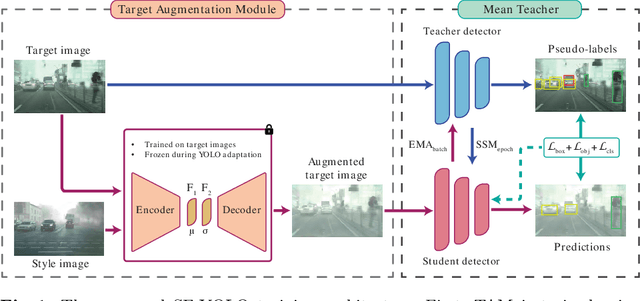

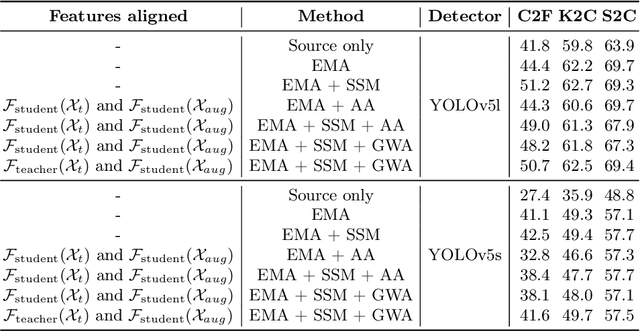
Source-free domain adaptation (SFDA) is a challenging problem in object detection, where a pre-trained source model is adapted to a new target domain without using any source domain data for privacy and efficiency reasons. Most state-of-the-art SFDA methods for object detection have been proposed for Faster-RCNN, a detector that is known to have high computational complexity. This paper focuses on domain adaptation techniques for real-world vision systems, particularly for the YOLO family of single-shot detectors known for their fast baselines and practical applications. Our proposed SFDA method - Source-Free YOLO (SF-YOLO) - relies on a teacher-student framework in which the student receives images with a learned, target domain-specific augmentation, allowing the model to be trained with only unlabeled target data and without requiring feature alignment. A challenge with self-training using a mean-teacher architecture in the absence of labels is the rapid decline of accuracy due to noisy or drifting pseudo-labels. To address this issue, a teacher-to-student communication mechanism is introduced to help stabilize the training and reduce the reliance on annotated target data for model selection. Despite its simplicity, our approach is competitive with state-of-the-art detectors on several challenging benchmark datasets, even sometimes outperforming methods that use source data for adaptation.