 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain Generalization by Rejecting Extreme Augmentations
Oct 10, 2023



Data augmentation is one of the most effective techniques for regularizing deep learning models and improving their recognition performance in a variety of tasks and domains. However, this holds for standard in-domain settings, in which the training and test data follow the same distribution. For the out-of-domain case, where the test data follow a different and unknown distribution, the best recipe for data augmentation is unclear. In this paper, we show that for out-of-domain and domain generalization settings, data augmentation can provide a conspicuous and robust improvement in performance. To do that, we propose a simple training procedure: (i) use uniform sampling on standard data augmentation transformations; (ii) increase the strength transformations to account for the higher data variance expected when working out-of-domain, and (iii) devise a new reward function to reject extreme transformations that can harm the training. With this procedure, our data augmentation scheme achieves a level of accuracy that is comparable to or better than state-of-the-art methods on benchmark domain generalization datasets. Code: \url{https://github.com/Masseeh/DCAug}
Re-basin via implicit Sinkhorn differentiation
Dec 22, 2022The recent emergence of new algorithms for permuting models into functionally equivalent regions of the solution space has shed some light on the complexity of error surfaces, and some promising properties like mode connectivity. However, finding the right permutation is challenging, and current optimization techniques are not differentiable, which makes it difficult to integrate into a gradient-based optimization, and often leads to sub-optimal solutions. In this paper, we propose a Sinkhorn re-basin network with the ability to obtain the transportation plan that better suits a given objective. Unlike the current state-of-art, our method is differentiable and, therefore, easy to adapt to any task within the deep learning domain. Furthermore, we show the advantage of our re-basin method by proposing a new cost function that allows performing incremental learning by exploiting the linear mode connectivity property. The benefit of our method is compared against similar approaches from the literature, under several conditions for both optimal transport finding and linear mode connectivity. The effectiveness of our continual learning method based on re-basin is also shown for several common benchmark datasets, providing experimental results that are competitive with state-of-art results from the literature.
Deep Metric Structured Learning For Facial Expression Recognition
Jan 18, 2020

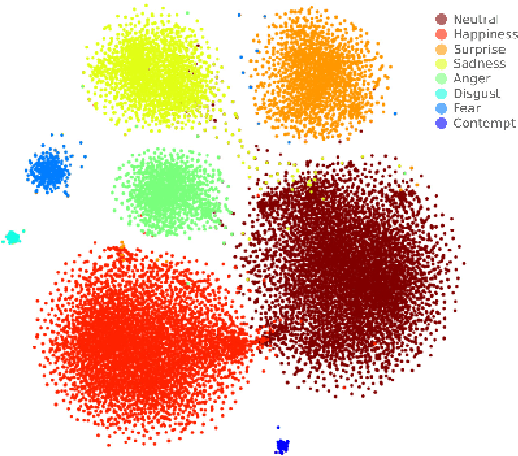
We propose a deep metric learning model to create embedded sub-spaces with a well defined structure. A new loss function that imposes Gaussian structures on the output space is introduced to create these sub-spaces thus shaping the distribution of the data. Having a mixture of Gaussians solution space is advantageous given its simplified and well established structure. It allows fast discovering of classes within classes and the identification of mean representatives at the centroids of individual classes. We also propose a new semi-supervised method to create sub-classes. We illustrate our methods on the facial expression recognition problem and validate results on the FER+, AffectNet, Extended Cohn-Kanade (CK+), BU-3DFE, and JAFFE datasets. We experimentally demonstrate that the learned embedding can be successfully used for various applications including expression retrieval and emotion recognition.
J Regularization Improves Imbalanced Multiclass Segmentation
Oct 22, 2019
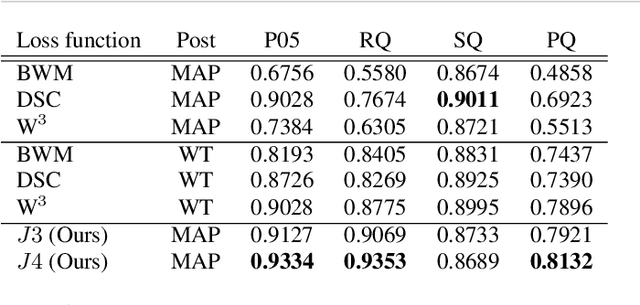
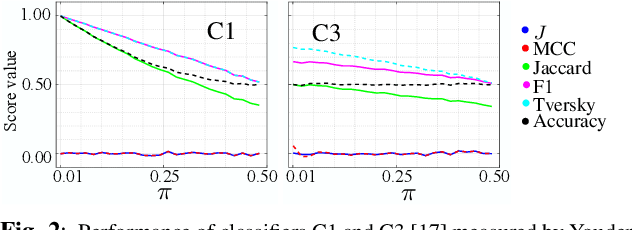
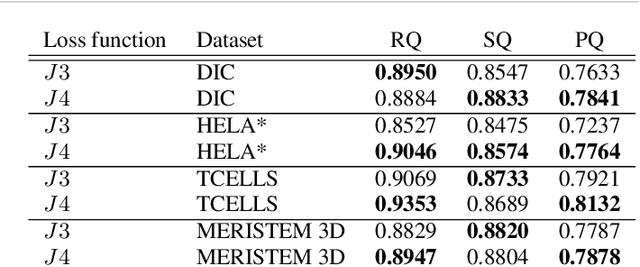
We propose a new loss formulation to further advance the multiclass segmentation of cluttered cells under weakly supervised conditions. We improve the separation of touching and immediate cells, obtaining sharp segmentation boundaries with high adequacy, when we add Youden's $J$ statistic regularization term to the cross entropy loss. This regularization intrinsically supports class imbalance thus eliminating the necessity of explicitly using weights to balance training. Simulations demonstrate this capability and show how the regularization leads to better results by helping advancing the optimization when cross entropy stalls. We build upon our previous work on multiclass segmentation by adding yet another training class representing gaps between adjacent cells. This addition helps the classifier identify narrow gaps as background and no longer as touching regions. We present results of our methods for 2D and 3D images, from bright field to confocal stacks containing different types of cells, and we show that they accurately segment individual cells after training with a limited number of annotated images, some of which are poorly annotated.
FERAtt: Facial Expression Recognition with Attention Net
Feb 08, 2019
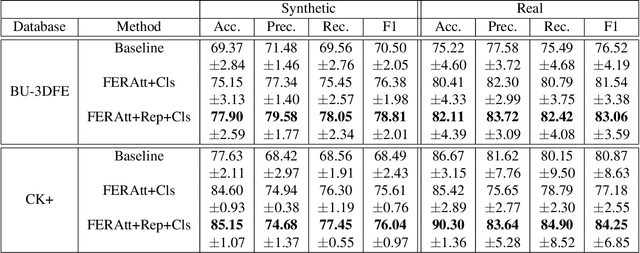

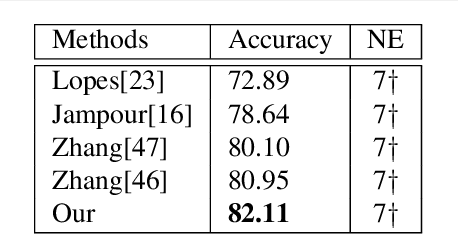
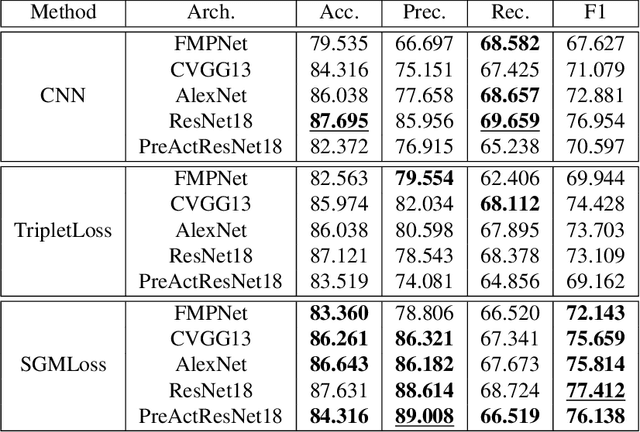
We present a new end-to-end network architecture for facial expression recognition with an attention model. It focuses attention in the human face and uses a Gaussian space representation for expression recognition. We devise this architecture based on two fundamental complementary components: (1) facial image correction and attention and (2) facial expression representation and classification. The first component uses an encoder-decoder style network and a convolutional feature extractor that are pixel-wise multiplied to obtain a feature attention map. The second component is responsible for obtaining an embedded representation and classification of the facial expression. We propose a loss function that creates a Gaussian structure on the representation space. To demonstrate the proposed method, we create two larger and more comprehensive synthetic datasets using the traditional BU3DFE and CK+ facial datasets. We compared results with the PreActResNet18 baseline. Our experiments on these datasets have shown the superiority of our approach in recognizing facial expressions.
Burst ranking for blind multi-image deblurring
Oct 30, 2018
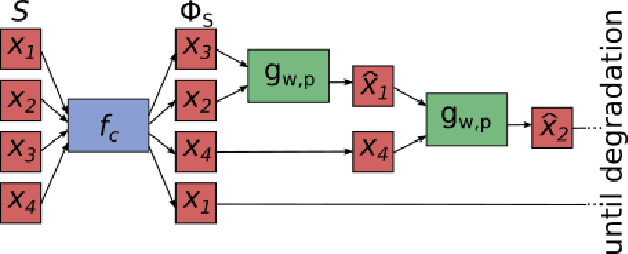

We propose a new incremental aggregation algorithm for multi-image deblurring with automatic image selection. The primary motivation is that current bursts deblurring methods do not handle well situations in which misalignment or out-of-context frames are present in the burst. These real-life situations result in poor reconstructions or manual selection of the images that will be used to deblur. Automatically selecting best frames within the burst to improve the base reconstruction is challenging because the amount of possible images fusions is equal to the power set cardinal. Here, we approach the multi-image deblurring problem as a two steps process. First, we successfully learn a comparison function to rank a burst of images using a deep convolutional neural network. Then, an incremental Fourier burst accumulation with a reconstruction degradation mechanism is applied fusing only less blurred images that are sufficient to maximize the reconstruction quality. Experiments with the proposed algorithm have shown superior results when compared to other similar approaches, outperforming other methods described in the literature in previously described situations. We validate our findings on several synthetic and real datasets.