 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Metric Structured Learning For Facial Expression Recognition
Jan 18, 2020

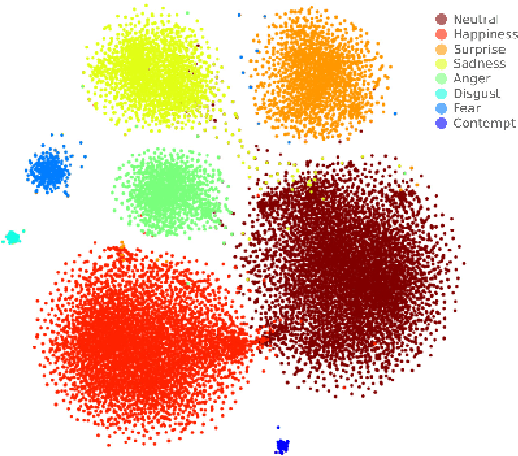
We propose a deep metric learning model to create embedded sub-spaces with a well defined structure. A new loss function that imposes Gaussian structures on the output space is introduced to create these sub-spaces thus shaping the distribution of the data. Having a mixture of Gaussians solution space is advantageous given its simplified and well established structure. It allows fast discovering of classes within classes and the identification of mean representatives at the centroids of individual classes. We also propose a new semi-supervised method to create sub-classes. We illustrate our methods on the facial expression recognition problem and validate results on the FER+, AffectNet, Extended Cohn-Kanade (CK+), BU-3DFE, and JAFFE datasets. We experimentally demonstrate that the learned embedding can be successfully used for various applications including expression retrieval and emotion recognition.
J Regularization Improves Imbalanced Multiclass Segmentation
Oct 22, 2019
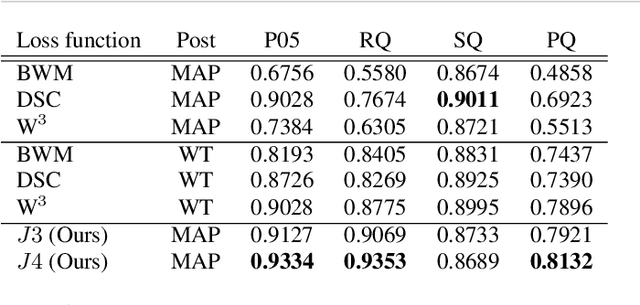
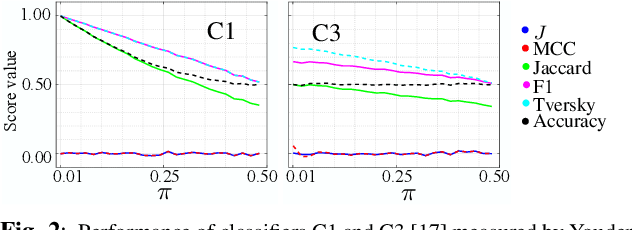
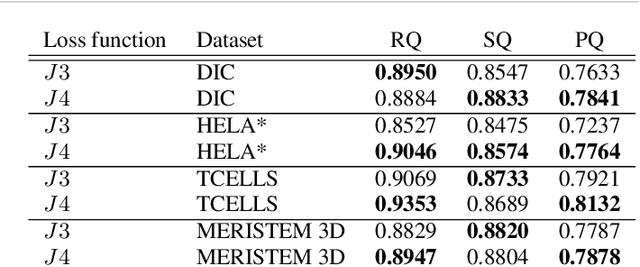
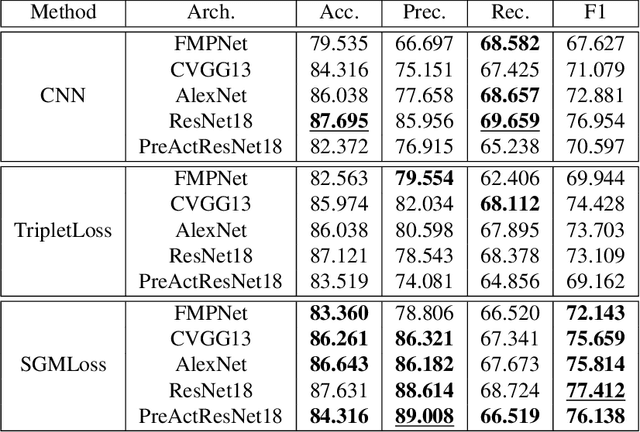
We propose a new loss formulation to further advance the multiclass segmentation of cluttered cells under weakly supervised conditions. We improve the separation of touching and immediate cells, obtaining sharp segmentation boundaries with high adequacy, when we add Youden's $J$ statistic regularization term to the cross entropy loss. This regularization intrinsically supports class imbalance thus eliminating the necessity of explicitly using weights to balance training. Simulations demonstrate this capability and show how the regularization leads to better results by helping advancing the optimization when cross entropy stalls. We build upon our previous work on multiclass segmentation by adding yet another training class representing gaps between adjacent cells. This addition helps the classifier identify narrow gaps as background and no longer as touching regions. We present results of our methods for 2D and 3D images, from bright field to confocal stacks containing different types of cells, and we show that they accurately segment individual cells after training with a limited number of annotated images, some of which are poorly annotated.
A Weakly Supervised Method for Instance Segmentation of Biological Cells
Aug 26, 2019
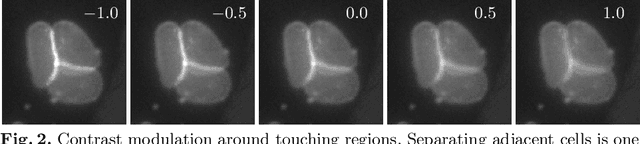
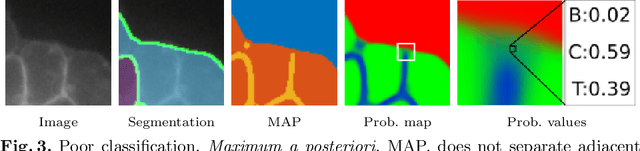

We present a weakly supervised deep learning method to perform instance segmentation of cells present in microscopy images. Annotation of biomedical images in the lab can be scarce, incomplete, and inaccurate. This is of concern when supervised learning is used for image analysis as the discriminative power of a learning model might be compromised in these situations. To overcome the curse of poor labeling, our method focuses on three aspects to improve learning: i) we propose a loss function operating in three classes to facilitate separating adjacent cells and to drive the optimizer to properly classify underrepresented regions; ii) a contour-aware weight map model is introduced to strengthen contour detection while improving the network generalization capacity; and iii) we augment data by carefully modulating local intensities on edges shared by adjoining regions and to account for possibly weak signals on these edges. Generated probability maps are segmented using different methods, with the watershed based one generally offering the best solutions, specially in those regions where the prevalence of a single class is not clear. The combination of these contributions allows segmenting individual cells on challenging images. We demonstrate our methods in sparse and crowded cell images, showing improvements in the learning process for a fixed network architecture.
FERAtt: Facial Expression Recognition with Attention Net
Feb 08, 2019
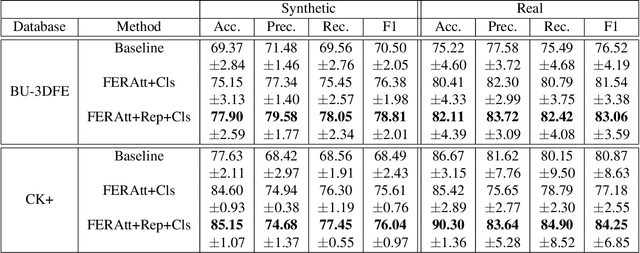

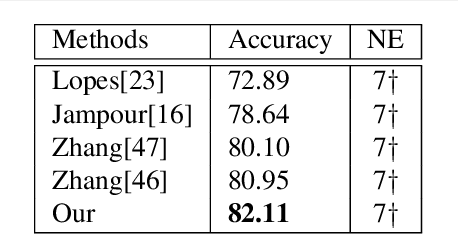
We present a new end-to-end network architecture for facial expression recognition with an attention model. It focuses attention in the human face and uses a Gaussian space representation for expression recognition. We devise this architecture based on two fundamental complementary components: (1) facial image correction and attention and (2) facial expression representation and classification. The first component uses an encoder-decoder style network and a convolutional feature extractor that are pixel-wise multiplied to obtain a feature attention map. The second component is responsible for obtaining an embedded representation and classification of the facial expression. We propose a loss function that creates a Gaussian structure on the representation space. To demonstrate the proposed method, we create two larger and more comprehensive synthetic datasets using the traditional BU3DFE and CK+ facial datasets. We compared results with the PreActResNet18 baseline. Our experiments on these datasets have shown the superiority of our approach in recognizing facial expressions.
Fast and Robust Multiple ColorChecker Detection using Deep Convolutional Neural Networks
Oct 19, 2018
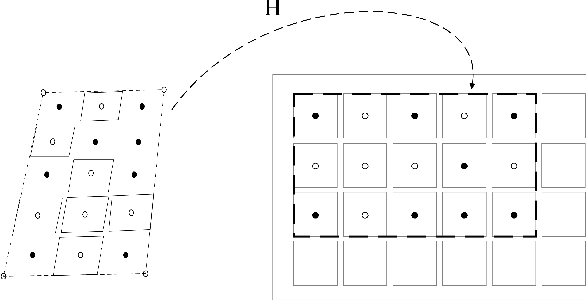
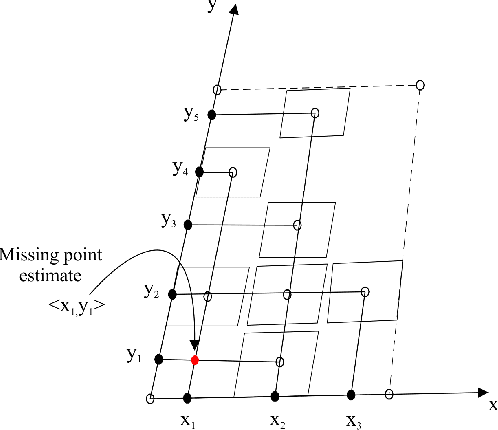
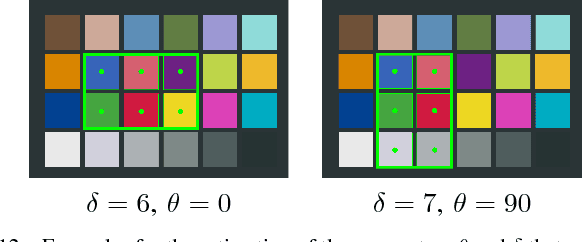
ColorCheckers are reference standards that professional photographers and filmmakers use to ensure predictable results under every lighting condition. The objective of this work is to propose a new fast and robust method for automatic ColorChecker detection. The process is divided into two steps: (1) ColorCheckers localization and (2) ColorChecker patches recognition. For the ColorChecker localization, we trained a detection convolutional neural network using synthetic images. The synthetic images are created with the 3D models of the ColorChecker and different background images. The output of the neural networks are the bounding box of each possible ColorChecker candidates in the input image. Each bounding box defines a cropped image which is evaluated by a recognition system, and each image is canonized with regards to color and dimensions. Subsequently, all possible color patches are extracted and grouped with respect to the center's distance. Each group is evaluated as a candidate for a ColorChecker part, and its position in the scene is estimated. Finally, a cost function is applied to evaluate the accuracy of the estimation. The method is tested using real and synthetic images. The proposed method is fast, robust to overlaps and invariant to affine projections. The algorithm also performs well in case of multiple ColorCheckers detection.
Multiclass Weighted Loss for Instance Segmentation of Cluttered Cells
Feb 21, 2018
We propose a new multiclass weighted loss function for instance segmentation of cluttered cells. We are primarily motivated by the need of developmental biologists to quantify and model the behavior of blood T-cells which might help us in understanding their regulation mechanisms and ultimately help researchers in their quest for developing an effective immuno-therapy cancer treatment. Segmenting individual touching cells in cluttered regions is challenging as the feature distribution on shared borders and cell foreground are similar thus difficulting discriminating pixels into proper classes. We present two novel weight maps applied to the weighted cross entropy loss function which take into account both class imbalance and cell geometry. Binary ground truth training data is augmented so the learning model can handle not only foreground and background but also a third touching class. This framework allows training using U-Net. Experiments with our formulations have shown superior results when compared to other similar schemes, outperforming binary class models with significant improvement of boundary adequacy and instance detection. We validate our results on manually annotated microscope images of T-cells.