 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain Generalization by Rejecting Extreme Augmentations
Oct 10, 2023



Data augmentation is one of the most effective techniques for regularizing deep learning models and improving their recognition performance in a variety of tasks and domains. However, this holds for standard in-domain settings, in which the training and test data follow the same distribution. For the out-of-domain case, where the test data follow a different and unknown distribution, the best recipe for data augmentation is unclear. In this paper, we show that for out-of-domain and domain generalization settings, data augmentation can provide a conspicuous and robust improvement in performance. To do that, we propose a simple training procedure: (i) use uniform sampling on standard data augmentation transformations; (ii) increase the strength transformations to account for the higher data variance expected when working out-of-domain, and (iii) devise a new reward function to reject extreme transformations that can harm the training. With this procedure, our data augmentation scheme achieves a level of accuracy that is comparable to or better than state-of-the-art methods on benchmark domain generalization datasets. Code: \url{https://github.com/Masseeh/DCAug}
HalluciDet: Hallucinating RGB Modality for Person Detection Through Privileged Information
Oct 07, 2023A powerful way to adapt a visual recognition model to a new domain is through image translation. However, common image translation approaches only focus on generating data from the same distribution of the target domain. In visual recognition tasks with complex images, such as pedestrian detection on aerial images with a large cross-modal shift in data distribution from Infrared (IR) to RGB images, a translation focused on generation might lead to poor performance as the loss focuses on irrelevant details for the task. In this paper, we propose HalluciDet, an IR-RGB image translation model for object detection that, instead of focusing on reconstructing the original image on the IR modality, is guided directly on reducing the detection loss of an RGB detector, and therefore avoids the need to access RGB data. This model produces a new image representation that enhances the object of interest in the scene and greatly improves detection performance. We empirically compare our approach against state-of-the-art image translation methods as well as with the commonly used fine-tuning on IR, and show that our method improves detection accuracy in most cases, by exploiting the privileged information encoded in a pre-trained RGB detector.
Re-basin via implicit Sinkhorn differentiation
Dec 22, 2022The recent emergence of new algorithms for permuting models into functionally equivalent regions of the solution space has shed some light on the complexity of error surfaces, and some promising properties like mode connectivity. However, finding the right permutation is challenging, and current optimization techniques are not differentiable, which makes it difficult to integrate into a gradient-based optimization, and often leads to sub-optimal solutions. In this paper, we propose a Sinkhorn re-basin network with the ability to obtain the transportation plan that better suits a given objective. Unlike the current state-of-art, our method is differentiable and, therefore, easy to adapt to any task within the deep learning domain. Furthermore, we show the advantage of our re-basin method by proposing a new cost function that allows performing incremental learning by exploiting the linear mode connectivity property. The benefit of our method is compared against similar approaches from the literature, under several conditions for both optimal transport finding and linear mode connectivity. The effectiveness of our continual learning method based on re-basin is also shown for several common benchmark datasets, providing experimental results that are competitive with state-of-art results from the literature.
Privacy-Preserving Person Detection Using Low-Resolution Infrared Cameras
Sep 22, 2022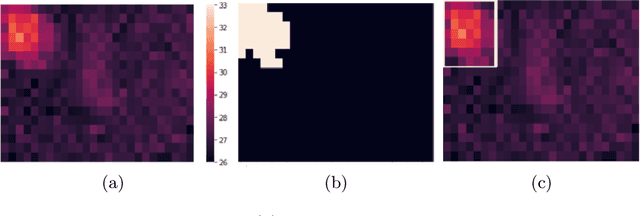
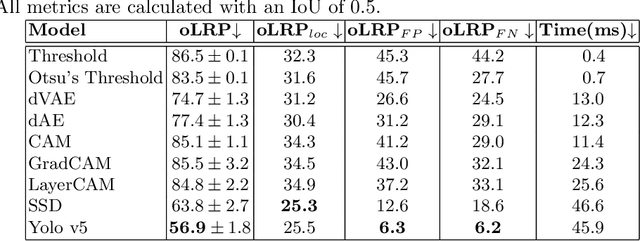
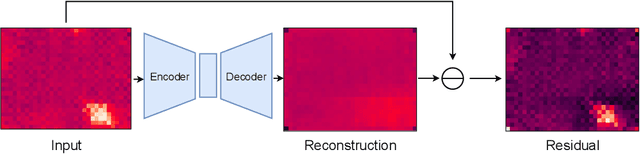
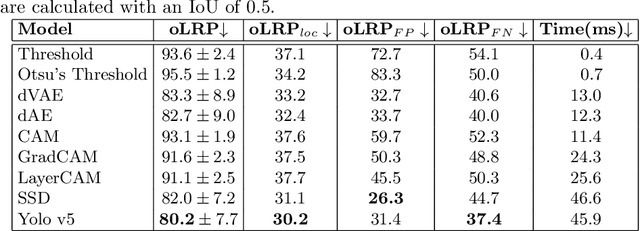
In intelligent building management, knowing the number of people and their location in a room are important for better control of its illumination, ventilation, and heating with reduced costs and improved comfort. This is typically achieved by detecting people using compact embedded devices that are installed on the room's ceiling, and that integrate low-resolution infrared camera, which conceals each person's identity. However, for accurate detection, state-of-the-art deep learning models still require supervised training using a large annotated dataset of images. In this paper, we investigate cost-effective methods that are suitable for person detection based on low-resolution infrared images. Results indicate that for such images, we can reduce the amount of supervision and computation, while still achieving a high level of detection accuracy. Going from single-shot detectors that require bounding box annotations of each person in an image, to auto-encoders that only rely on unlabelled images that do not contain people, allows for considerable savings in terms of annotation costs, and for models with lower computational costs. We validate these experimental findings on two challenging top-view datasets with low-resolution infrared images.