 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlowMaps: Modeling Long-Term Multimodal Object Dynamics with Flow Matching
Jun 18, 2026Joint spatial and temporal understanding of 3D scenes is a crucial requirement for robots deployed in everyday household environments. Such agents must not only comprehend and navigate spatial layouts, but also reason about how these spaces evolve over time. In particular, humans interact with objects daily, causing them to change position throughout the environment and making it difficult for robots to reliably associate current observations with previously seen objects. However, these interactions are not random: human habits and routines induce spatio-temporally consistent patterns in object locations, which robotic agents can potentially learn and then exploit for downstream tasks such as navigation. To this end, we introduce FlowMaps, a latent flow matching model for estimating multimodal distributions over the future locations of dynamic objects in a continuous 3D space. By learning the implicit dependencies among objects and their temporal evolution, FlowMaps predicts likely changes in object locations conditioned on past human interactions, while supporting generalization across previously unseen environments that share similar object routines. To demonstrate the utility of this method, we deploy FlowMaps in a downstream dynamic Object Navigation task in both simulated and real-world environments. Across more than 600 episodes, FlowMaps outperforms state-of-the-art approaches, showing that modeling object dynamics through continuous, multimodal spatio-temporal distributions improves robotic search and navigation in changing household environments. Code and additional material is available at https://fra-tsuna.github.io/flowmaps/.
PerceptTwin: Semantic Scene Reconstruction for Iterative LLM Planning and Verification
Jun 02, 2026Simulation environments are useful for both robot policy learning and planning verification and validation. Traditionally, the process of creating a simulation was onerous. Creating a bespoke simulation environment for each individual environment that a robot would operate in was simply infeasible. In this work, we introduce PerceptTwin, a fully automatic pipeline that constructs interactive simulations directly from semantic scene representations produced by a robot's perception stack. PerceptTwin combines open-vocabulary object maps with 3D asset generation, affordance prediction, and commonsense condition checking. These interactive simulations can be used to validate and refine plans before they are executed on the robot hardware. Borrowing from the AI alignment literature, we also introduce an LLM judge that verifies plan correctness and alignment with human preferences. Experiments show that PerceptTwin feedback allows LLM planners to refine plans, enhance safety, and resist harmful black-box prompting attacks. In our suite of tasks, PerceptTwin improves plan success by an average of approximately 39% for GPT5, GPT5Mini, and GPT5Nano planners. Additionally, PerceptTwin also improves human plan verification by up to 18% on average for plans that fail due to unfilled skill preconditions. Our results demonstrate the potential of open-vocabulary scene simulation from robot perception as a foundation for safer, more reliable robot planning.
On the Sample Efficiency of Inverse Dynamics Models for Semi-Supervised Imitation Learning
Feb 02, 2026Semi-supervised imitation learning (SSIL) consists in learning a policy from a small dataset of action-labeled trajectories and a much larger dataset of action-free trajectories. Some SSIL methods learn an inverse dynamics model (IDM) to predict the action from the current state and the next state. An IDM can act as a policy when paired with a video model (VM-IDM) or as a label generator to perform behavior cloning on action-free data (IDM labeling). In this work, we first show that VM-IDM and IDM labeling learn the same policy in a limit case, which we call the IDM-based policy. We then argue that the previously observed advantage of IDM-based policies over behavior cloning is due to the superior sample efficiency of IDM learning, which we attribute to two causes: (i) the ground-truth IDM tends to be contained in a lower complexity hypothesis class relative to the expert policy, and (ii) the ground-truth IDM is often less stochastic than the expert policy. We argue these claims based on insights from statistical learning theory and novel experiments, including a study of IDM-based policies using recent architectures for unified video-action prediction (UVA). Motivated by these insights, we finally propose an improved version of the existing LAPO algorithm for latent action policy learning.
OpenLex3D: A New Evaluation Benchmark for Open-Vocabulary 3D Scene Representations
Mar 25, 2025



3D scene understanding has been transformed by open-vocabulary language models that enable interaction via natural language. However, the evaluation of these representations is limited to closed-set semantics that do not capture the richness of language. This work presents OpenLex3D, a dedicated benchmark to evaluate 3D open-vocabulary scene representations. OpenLex3D provides entirely new label annotations for 23 scenes from Replica, ScanNet++, and HM3D, which capture real-world linguistic variability by introducing synonymical object categories and additional nuanced descriptions. By introducing an open-set 3D semantic segmentation task and an object retrieval task, we provide insights on feature precision, segmentation, and downstream capabilities. We evaluate various existing 3D open-vocabulary methods on OpenLex3D, showcasing failure cases, and avenues for improvement. The benchmark is publicly available at: https://openlex3d.github.io/.
The Bare Necessities: Designing Simple, Effective Open-Vocabulary Scene Graphs
Dec 02, 20243D open-vocabulary scene graph methods are a promising map representation for embodied agents, however many current approaches are computationally expensive. In this paper, we reexamine the critical design choices established in previous works to optimize both efficiency and performance. We propose a general scene graph framework and conduct three studies that focus on image pre-processing, feature fusion, and feature selection. Our findings reveal that commonly used image pre-processing techniques provide minimal performance improvement while tripling computation (on a per object view basis). We also show that averaging feature labels across different views significantly degrades performance. We study alternative feature selection strategies that enhance performance without adding unnecessary computational costs. Based on our findings, we introduce a computationally balanced approach for 3D point cloud segmentation with per-object features. The approach matches state-of-the-art classification accuracy while achieving a threefold reduction in computation.
Spectral Temporal Contrastive Learning
Dec 07, 2023


Learning useful data representations without requiring labels is a cornerstone of modern deep learning. Self-supervised learning methods, particularly contrastive learning (CL), have proven successful by leveraging data augmentations to define positive pairs. This success has prompted a number of theoretical studies to better understand CL and investigate theoretical bounds for downstream linear probing tasks. This work is concerned with the temporal contrastive learning (TCL) setting where the sequential structure of the data is used instead to define positive pairs, which is more commonly used in RL and robotics contexts. In this paper, we adapt recent work on Spectral CL to formulate Spectral Temporal Contrastive Learning (STCL). We discuss a population loss based on a state graph derived from a time-homogeneous reversible Markov chain with uniform stationary distribution. The STCL loss enables to connect the linear probing performance to the spectral properties of the graph, and can be estimated by considering previously observed data sequences as an ensemble of MCMC chains.
ConceptGraphs: Open-Vocabulary 3D Scene Graphs for Perception and Planning
Sep 28, 2023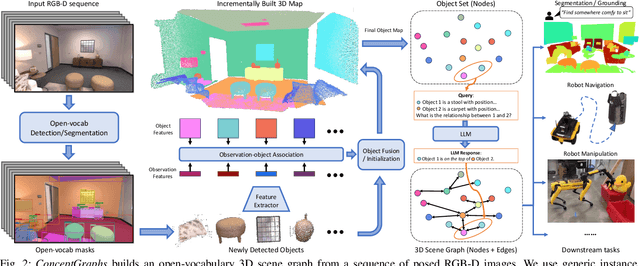
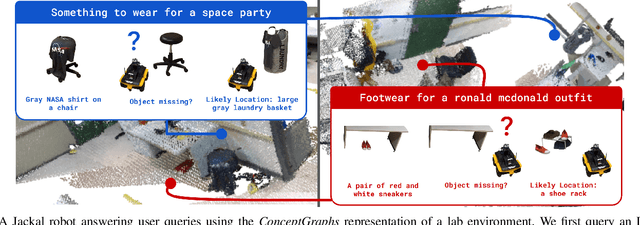
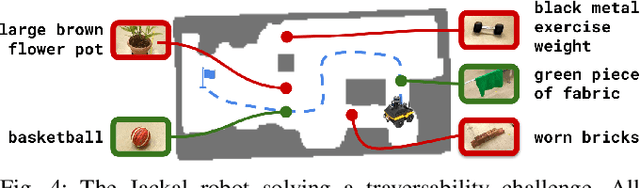
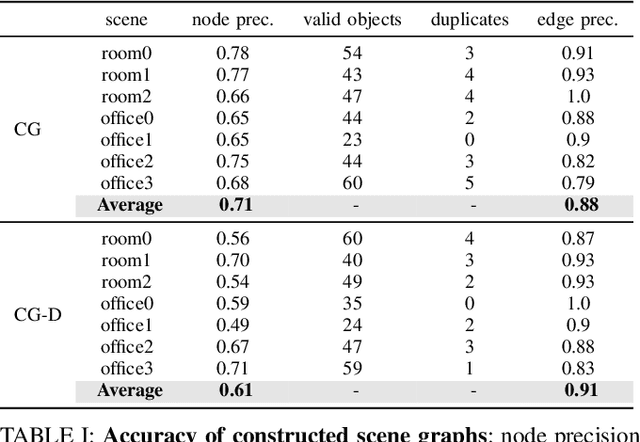
For robots to perform a wide variety of tasks, they require a 3D representation of the world that is semantically rich, yet compact and efficient for task-driven perception and planning. Recent approaches have attempted to leverage features from large vision-language models to encode semantics in 3D representations. However, these approaches tend to produce maps with per-point feature vectors, which do not scale well in larger environments, nor do they contain semantic spatial relationships between entities in the environment, which are useful for downstream planning. In this work, we propose ConceptGraphs, an open-vocabulary graph-structured representation for 3D scenes. ConceptGraphs is built by leveraging 2D foundation models and fusing their output to 3D by multi-view association. The resulting representations generalize to novel semantic classes, without the need to collect large 3D datasets or finetune models. We demonstrate the utility of this representation through a number of downstream planning tasks that are specified through abstract (language) prompts and require complex reasoning over spatial and semantic concepts. (Project page: https://concept-graphs.github.io/ Explainer video: https://youtu.be/mRhNkQwRYnc )
StepMix: A Python Package for Pseudo-Likelihood Estimation of Generalized Mixture Models with External Variables
Apr 11, 2023StepMix is an open-source software package for the pseudo-likelihood estimation (one-, two- and three-step approaches) of generalized finite mixture models (latent profile and latent class analysis) with external variables (covariates and distal outcomes). In many applications in social sciences, the main objective is not only to cluster individuals into latent classes, but also to use these classes to develop more complex statistical models. These models generally divide into a measurement model that relates the latent classes to observed indicators, and a structural model that relates covariates and outcome variables to the latent classes. The measurement and structural models can be estimated jointly using the so-called one-step approach or sequentially using stepwise methods, which present significant advantages for practitioners regarding the interpretability of the estimated latent classes. In addition to the one-step approach, StepMix implements the most important stepwise estimation methods from the literature, including the bias-adjusted three-step methods with BCH and ML corrections and the more recent two-step approach. These pseudo-likelihood estimators are presented in this paper under a unified framework as specific expectation-maximization subroutines. To facilitate and promote their adoption among the data science community, StepMix follows the object-oriented design of the scikit-learn library and provides interfaces in both Python and R.
One-4-All: Neural Potential Fields for Embodied Navigation
Mar 07, 2023A fundamental task in robotics is to navigate between two locations. In particular, real-world navigation can require long-horizon planning using high-dimensional RGB images, which poses a substantial challenge for end-to-end learning-based approaches. Current semi-parametric methods instead achieve long-horizon navigation by combining learned modules with a topological memory of the environment, often represented as a graph over previously collected images. However, using these graphs in practice typically involves tuning a number of pruning heuristics to avoid spurious edges, limit runtime memory usage and allow reasonably fast graph queries. In this work, we present One-4-All (O4A), a method leveraging self-supervised and manifold learning to obtain a graph-free, end-to-end navigation pipeline in which the goal is specified as an image. Navigation is achieved by greedily minimizing a potential function defined continuously over the O4A latent space. Our system is trained offline on non-expert exploration sequences of RGB data and controls, and does not require any depth or pose measurements. We show that O4A can reach long-range goals in 8 simulated Gibson indoor environments, and further demonstrate successful real-world navigation using a Jackal UGV platform.
Monocular Robot Navigation with Self-Supervised Pretrained Vision Transformers
Mar 07, 2022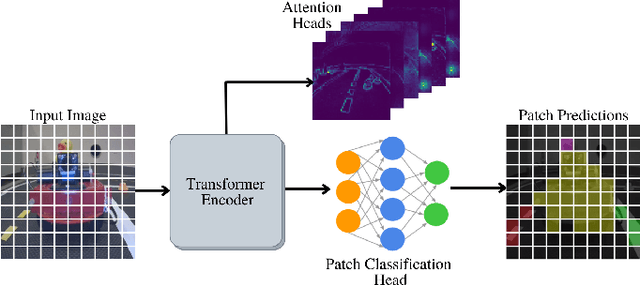

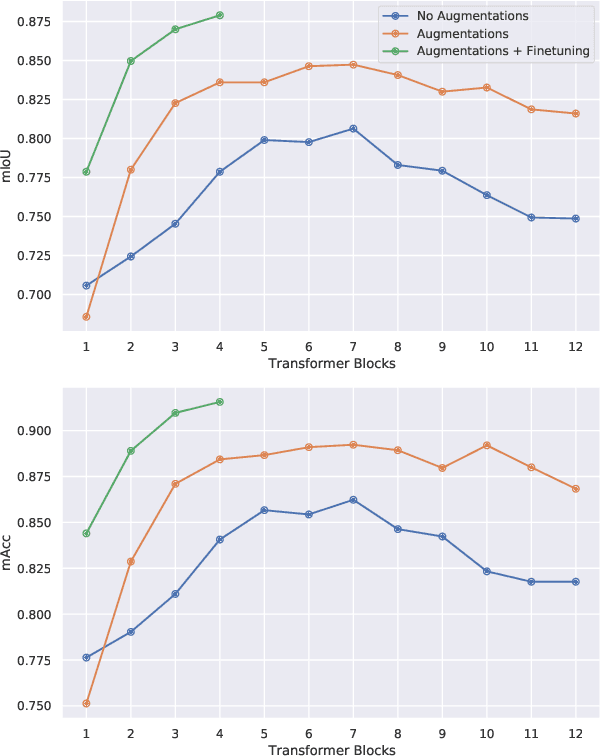

In this work, we consider the problem of learning a perception model for monocular robot navigation using few annotated images. Using a Vision Transformer (ViT) pretrained with a label-free self-supervised method, we successfully train a coarse image segmentation model for the Duckietown environment using 70 training images. Our model performs coarse image segmentation at the 8x8 patch level, and the inference resolution can be adjusted to balance prediction granularity and real-time perception constraints. We study how best to adapt a ViT to our task and environment, and find that some lightweight architectures can yield good single-image segmentations at a usable frame rate, even on CPU. The resulting perception model is used as the backbone for a simple yet robust visual servoing agent, which we deploy on a differential drive mobile robot to perform two tasks: lane following and obstacle avoidance.