 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMonocular Robot Navigation with Self-Supervised Pretrained Vision Transformers
Paper and Code
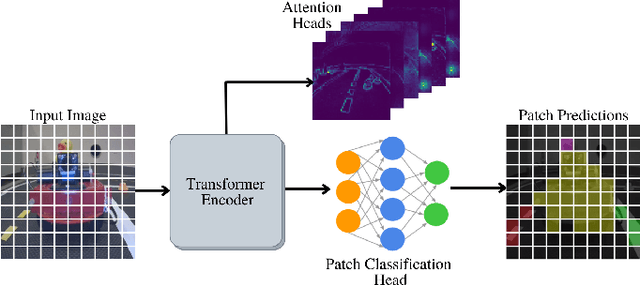

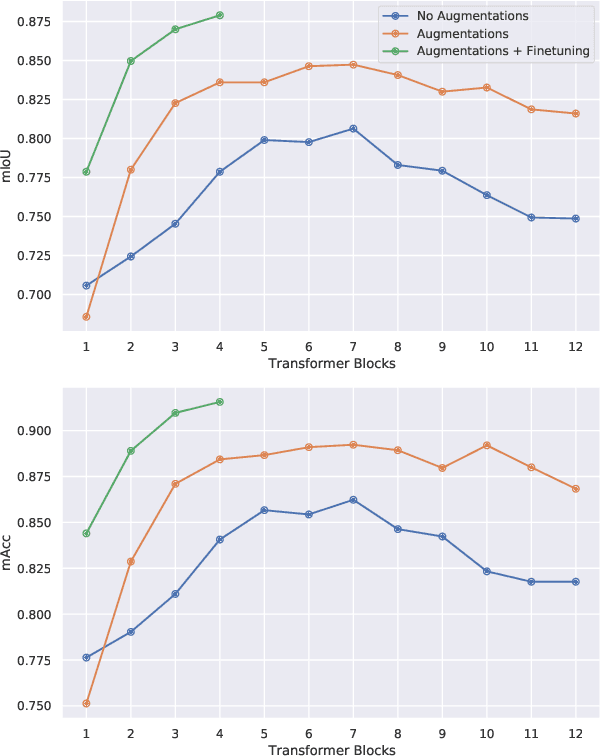

In this work, we consider the problem of learning a perception model for monocular robot navigation using few annotated images. Using a Vision Transformer (ViT) pretrained with a label-free self-supervised method, we successfully train a coarse image segmentation model for the Duckietown environment using 70 training images. Our model performs coarse image segmentation at the 8x8 patch level, and the inference resolution can be adjusted to balance prediction granularity and real-time perception constraints. We study how best to adapt a ViT to our task and environment, and find that some lightweight architectures can yield good single-image segmentations at a usable frame rate, even on CPU. The resulting perception model is used as the backbone for a simple yet robust visual servoing agent, which we deploy on a differential drive mobile robot to perform two tasks: lane following and obstacle avoidance.