 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast Approximate Solutions using Reinforcement Learning for Dynamic Capacitated Vehicle Routing with Time Windows
Feb 24, 2021
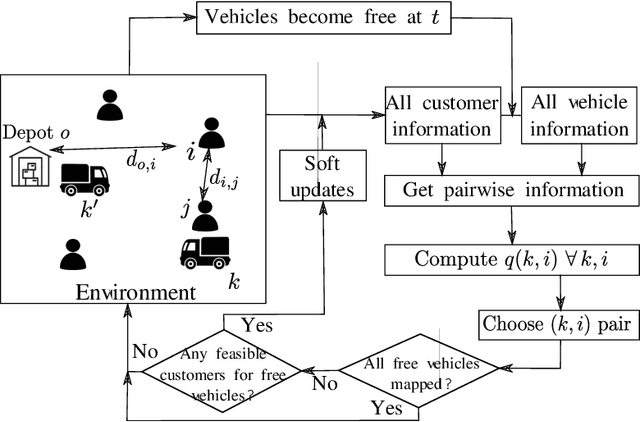
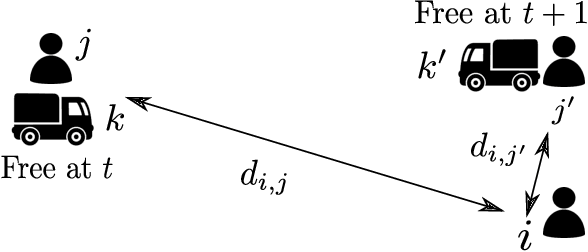

This paper develops an inherently parallelised, fast, approximate learning-based solution to the generic class of Capacitated Vehicle Routing with Time Windows and Dynamic Routing (CVRP-TWDR). Considering vehicles in a fleet as decentralised agents, we postulate that using reinforcement learning (RL) based adaptation is a key enabler for real-time route formation in a dynamic environment. The methodology allows each agent (vehicle) to independently evaluate the value of serving each customer, and uses a centralised allocation heuristic to finalise the allocations based on the generated values. We show that the solutions produced by this method on standard datasets are significantly faster than exact formulations and state-of-the-art meta-heuristics, while being reasonably close to optimal in terms of solution quality. We describe experiments in both the static case (when all customer demands and time windows are known in advance) as well as the dynamic case (where customers can `pop up' at any time during execution). The results with a single trained model on large, out-of-distribution test data demonstrate the scalability and flexibility of the proposed approach.
Reinforcement Learning for Multi-Product Multi-Node Inventory Management in Supply Chains
Jun 07, 2020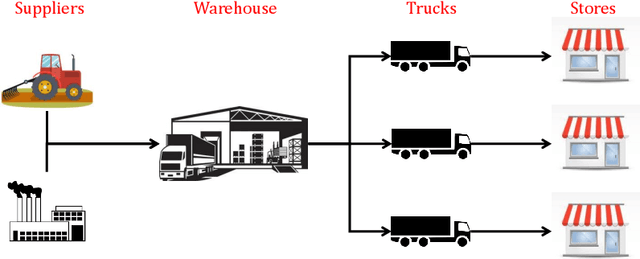

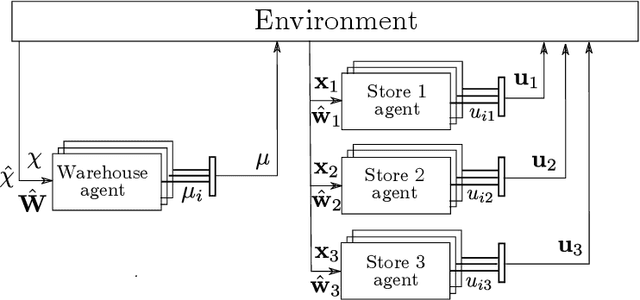
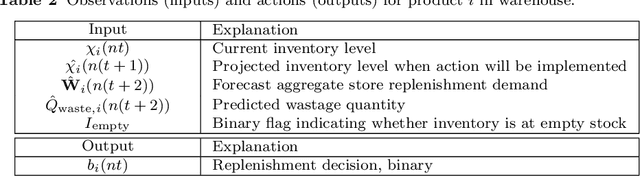
This paper describes the application of reinforcement learning (RL) to multi-product inventory management in supply chains. The problem description and solution are both adapted from a real-world business solution. The novelty of this problem with respect to supply chain literature is (i) we consider concurrent inventory management of a large number (50 to 1000) of products with shared capacity, (ii) we consider a multi-node supply chain consisting of a warehouse which supplies three stores, (iii) the warehouse, stores, and transportation from warehouse to stores have finite capacities, (iv) warehouse and store replenishment happen at different time scales and with realistic time lags, and (v) demand for products at the stores is stochastic. We describe a novel formulation in a multi-agent (hierarchical) reinforcement learning framework that can be used for parallelised decision-making, and use the advantage actor critic (A2C) algorithm with quantised action spaces to solve the problem. Experiments show that the proposed approach is able to handle a multi-objective reward comprised of maximising product sales and minimising wastage of perishable products.
Reinforcement Learning for Multi-Objective Optimization of Online Decisions in High-Dimensional Systems
Oct 01, 2019

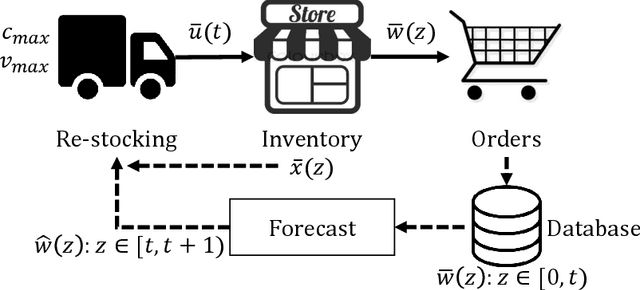

This paper describes a purely data-driven solution to a class of sequential decision-making problems with a large number of concurrent online decisions, with applications to computing systems and operations research. We assume that while the micro-level behaviour of the system can be broadly captured by analytical expressions or simulation, the macro-level or emergent behaviour is complicated by non-linearity, constraints, and stochasticity. If we represent the set of concurrent decisions to be computed as a vector, each element of the vector is assumed to be a continuous variable, and the number of such elements is arbitrarily large and variable from one problem instance to another. We first formulate the decision-making problem as a canonical reinforcement learning (RL) problem, which can be solved using purely data-driven techniques. We modify a standard approach known as advantage actor critic (A2C) to ensure its suitability to the problem at hand, and compare its performance to that of baseline approaches on the specific instance of a multi-product inventory management task. The key modifications include a parallelised formulation of the decision-making task, and a training procedure that explicitly recognises the quantitative relationship between different decisions. We also present experimental results probing the learned policies, and their robustness to variations in the data.