 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast Approximate Solutions using Reinforcement Learning for Dynamic Capacitated Vehicle Routing with Time Windows
Feb 24, 2021
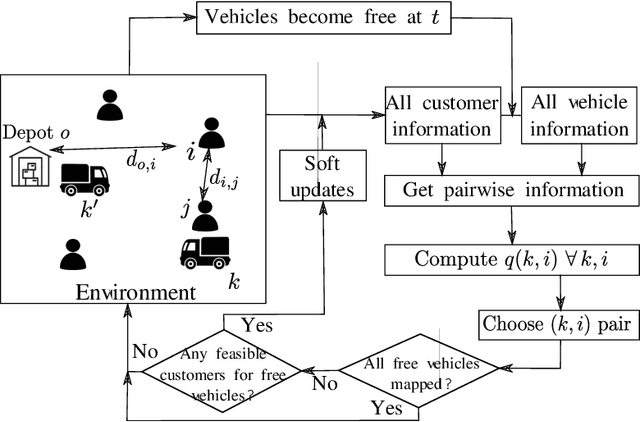
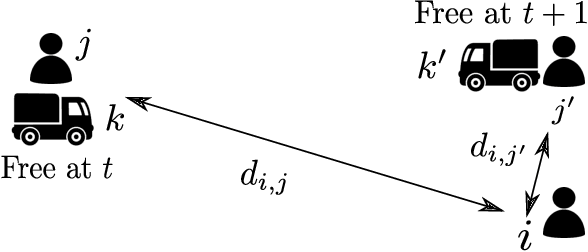

This paper develops an inherently parallelised, fast, approximate learning-based solution to the generic class of Capacitated Vehicle Routing with Time Windows and Dynamic Routing (CVRP-TWDR). Considering vehicles in a fleet as decentralised agents, we postulate that using reinforcement learning (RL) based adaptation is a key enabler for real-time route formation in a dynamic environment. The methodology allows each agent (vehicle) to independently evaluate the value of serving each customer, and uses a centralised allocation heuristic to finalise the allocations based on the generated values. We show that the solutions produced by this method on standard datasets are significantly faster than exact formulations and state-of-the-art meta-heuristics, while being reasonably close to optimal in terms of solution quality. We describe experiments in both the static case (when all customer demands and time windows are known in advance) as well as the dynamic case (where customers can `pop up' at any time during execution). The results with a single trained model on large, out-of-distribution test data demonstrate the scalability and flexibility of the proposed approach.