 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Reinforcement Learning Approach for Electric Vehicle Routing Problem with Vehicle-to-Grid Supply
Apr 12, 2022



The use of electric vehicles (EV) in the last mile is appealing from both sustainability and operational cost perspectives. In addition to the inherent cost efficiency of EVs, selling energy back to the grid during peak grid demand, is a potential source of additional revenue to a fleet operator. To achieve this, EVs have to be at specific locations (discharge points) during specific points in time (peak period), even while meeting their core purpose of delivering goods to customers. In this work, we consider the problem of EV routing with constraints on loading capacity; time window; vehicle-to-grid energy supply (CEVRPTW-D); which not only satisfy multiple system objectives, but also scale efficiently to large problem sizes involving hundreds of customers and discharge stations. We present QuikRouteFinder that uses reinforcement learning (RL) for EV routing to overcome these challenges. Using Solomon datasets, results from RL are compared against exact formulations based on mixed-integer linear program (MILP) and genetic algorithm (GA) metaheuristics. On an average, the results show that RL is 24 times faster than MILP and GA, while being close in quality (within 20%) to the optimal.
A generalized algorithm and framework for online 3-dimensional bin packing in an automated sorting center
Nov 01, 2021
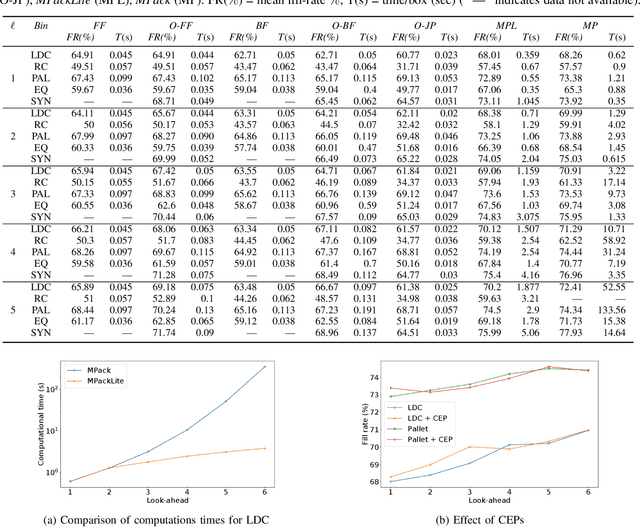
Online 3-dimensional bin packing problem (O3D-BPP) is getting renewed prominence due to the industrial automation brought by Industry 4.0. However, due to limited attention in the past and its challenging nature, a good approximate algorithm is in scarcity as compared to 1D or 2D problems. This paper considers real-time O$3$D-BPP of cuboidal boxes with partial information (look-ahead) in an automated robotic sorting center. We present two rolling-horizon mixed-integer linear programming (MILP) cum-heuristic based algorithms: MPack (for bench-marking) and MPackLite (for real-time deployment). Additionally, we present a framework OPack that adapts and improves the performance of BP heuristics by utilizing information in an online setting with a look-ahead. We then perform a comparative analysis of BP heuristics (with and without OPack), MPack, and MPackLite on synthetic and industry provided data with increasing look-ahead. MPackLite and the baseline heuristics perform within bounds of robot operations and thus, can be used in real-time.
Fast Approximate Solutions using Reinforcement Learning for Dynamic Capacitated Vehicle Routing with Time Windows
Feb 24, 2021
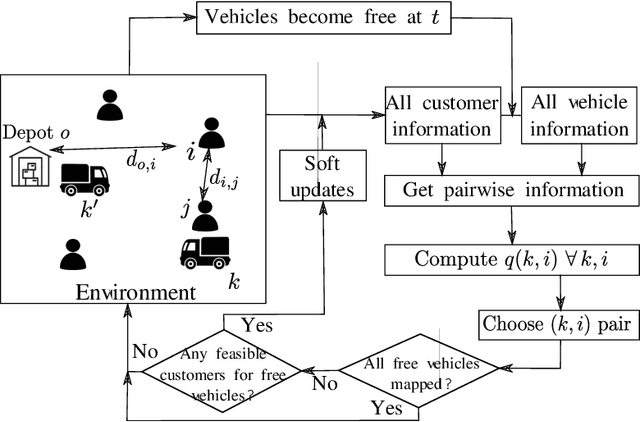
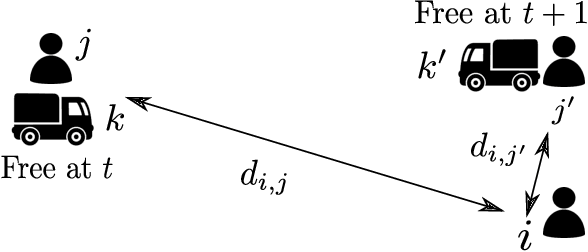

This paper develops an inherently parallelised, fast, approximate learning-based solution to the generic class of Capacitated Vehicle Routing with Time Windows and Dynamic Routing (CVRP-TWDR). Considering vehicles in a fleet as decentralised agents, we postulate that using reinforcement learning (RL) based adaptation is a key enabler for real-time route formation in a dynamic environment. The methodology allows each agent (vehicle) to independently evaluate the value of serving each customer, and uses a centralised allocation heuristic to finalise the allocations based on the generated values. We show that the solutions produced by this method on standard datasets are significantly faster than exact formulations and state-of-the-art meta-heuristics, while being reasonably close to optimal in terms of solution quality. We describe experiments in both the static case (when all customer demands and time windows are known in advance) as well as the dynamic case (where customers can `pop up' at any time during execution). The results with a single trained model on large, out-of-distribution test data demonstrate the scalability and flexibility of the proposed approach.