 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Much is too Much: Exploring the Effect of Verbal Route Description Length on Indoor Navigation
Aug 27, 2024Navigating through a new indoor environment can be stressful. Recently, many places have deployed robots to assist visitors. One of the features of such robots is escorting the visitors to their desired destination within the environment, but this is neither scalable nor necessary for every visitor. Instead, a robot assistant could be deployed at a strategic location to provide wayfinding instructions. This not only increases the user experience but can be helpful in many time-critical scenarios e.g., escorting someone to their boarding gate at an airport. However, delivering route descriptions verbally poses a challenge. If the description is too verbose, people may struggle to recall all the information, while overly brief descriptions may be simply unhelpful. This article focuses on studying the optimal length of verbal route descriptions that are effective for reaching the destination and easy for people to recall. This work proposes a theoretical framework that links route segments to chunks in working memory. Based on this framework, an experiment is designed and conducted to examine the effects of route descriptions of different lengths on navigational performance. The results revealed intriguing patterns suggesting an ideal length of four route segments. This study lays a foundation for future research exploring the relationship between route description lengths, working memory capacity, and navigational performance in indoor environments.
Teledrive: An Embodied AI based Telepresence System
Jun 01, 2024



This article presents Teledrive, a telepresence robotic system with embodied AI features that empowers an operator to navigate the telerobot in any unknown remote place with minimal human intervention. We conceive Teledrive in the context of democratizing remote care-giving for elderly citizens as well as for isolated patients, affected by contagious diseases. In particular, this paper focuses on the problem of navigating to a rough target area (like bedroom or kitchen) rather than pre-specified point destinations. This ushers in a unique AreaGoal based navigation feature, which has not been explored in depth in the contemporary solutions. Further, we describe an edge computing-based software system built on a WebRTC-based communication framework to realize the aforementioned scheme through an easy-to-use speech-based human-robot interaction. Moreover, to enhance the ease of operation for the remote caregiver, we incorporate a person following feature, whereby a robot follows a person on the move in its premises as directed by the operator. Moreover, the system presented is loosely coupled with specific robot hardware, unlike the existing solutions. We have evaluated the efficacy of the proposed system through baseline experiments, user study, and real-life deployment.
* Accepted in Journal of Intelligent Robotic System
tagE: Enabling an Embodied Agent to Understand Human Instructions
Oct 24, 2023Natural language serves as the primary mode of communication when an intelligent agent with a physical presence engages with human beings. While a plethora of research focuses on natural language understanding (NLU), encompassing endeavors such as sentiment analysis, intent prediction, question answering, and summarization, the scope of NLU directed at situations necessitating tangible actions by an embodied agent remains limited. The inherent ambiguity and incompleteness inherent in natural language present challenges for intelligent agents striving to decipher human intention. To tackle this predicament head-on, we introduce a novel system known as task and argument grounding for Embodied agents (tagE). At its core, our system employs an inventive neural network model designed to extract a series of tasks from complex task instructions expressed in natural language. Our proposed model adopts an encoder-decoder framework enriched with nested decoding to effectively extract tasks and their corresponding arguments from these intricate instructions. These extracted tasks are then mapped (or grounded) to the robot's established collection of skills, while the arguments find grounding in objects present within the environment. To facilitate the training and evaluation of our system, we have curated a dataset featuring complex instructions. The results of our experiments underscore the prowess of our approach, as it outperforms robust baseline models.
Consensus-based Fast and Energy-Efficient Multi-Robot Task Allocation
Sep 21, 2022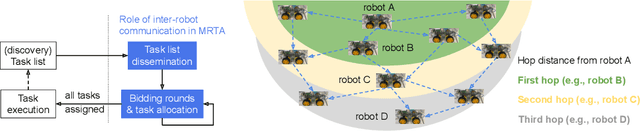
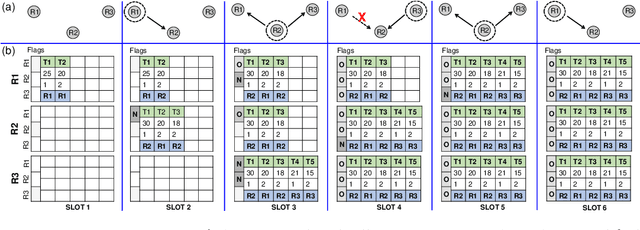
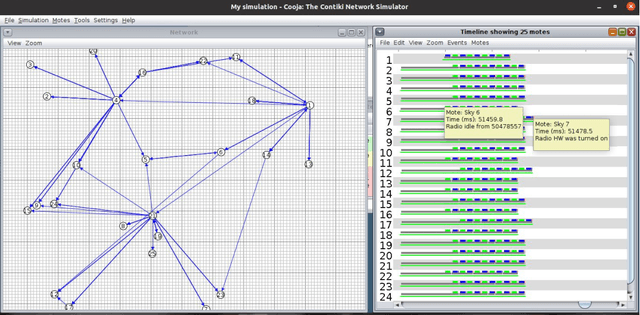
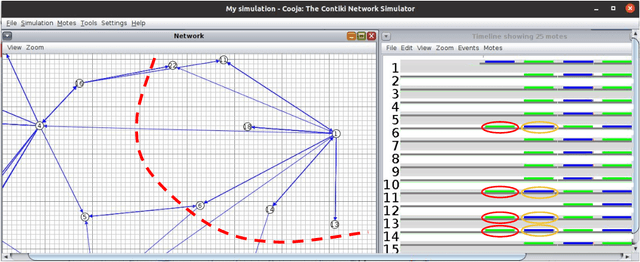
In a multi-robot system, the appropriate allocation of the tasks to the individual robots is a very significant component. The availability of a centralized infrastructure can guarantee an optimal allocation of the tasks. However, in many important scenarios such as search and rescue, exploration, disaster-management, war-field, etc., on-the-fly allocation of the dynamic tasks to the robots in a decentralized fashion is the only possible option. Efficient communication among the robots plays a crucial role in any such decentralized setting. Existing works on distributed Multi-Robot Task Allocation (MRTA) either assume that the network is available or a naive communication paradigm is used. On the contrary, in most of these scenarios, the network infrastructure is either unstable or unavailable and ad-hoc networking is the only resort. Recent developments in synchronous-transmission (ST) based wireless communication protocols are shown to be more efficient than the traditional asynchronous transmission-based protocols in ad hoc networks such as Wireless Sensor Network (WSN)/Internet of Things (IoT) applications. The current work is the first effort that utilizes ST for MRTA. Specifically, we propose an algorithm that efficiently adapts ST-based many-to-many interaction and minimizes the information exchange to reach a consensus for task allocation. We showcase the efficacy of the proposed algorithm through an extensive simulation-based study of its latency and energy-efficiency under different settings.
DoRO: Disambiguation of referred object for embodied agents
Jul 28, 2022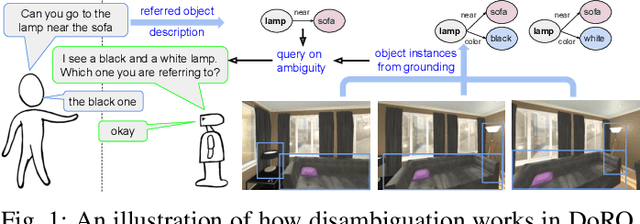
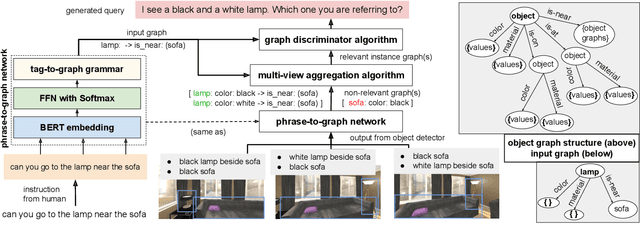
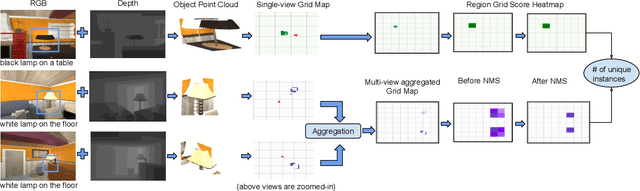
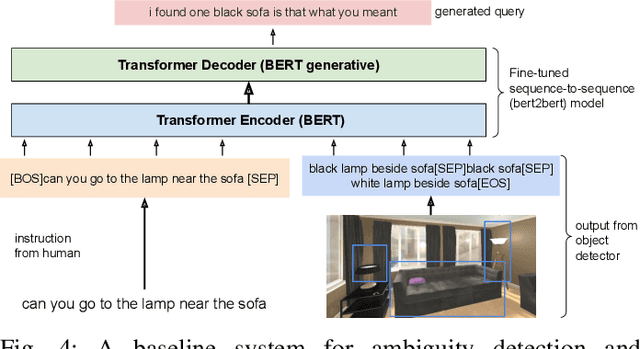
Robotic task instructions often involve a referred object that the robot must locate (ground) within the environment. While task intent understanding is an essential part of natural language understanding, less effort is made to resolve ambiguity that may arise while grounding the task. Existing works use vision-based task grounding and ambiguity detection, suitable for a fixed view and a static robot. However, the problem magnifies for a mobile robot, where the ideal view is not known beforehand. Moreover, a single view may not be sufficient to locate all the object instances in the given area, which leads to inaccurate ambiguity detection. Human intervention is helpful only if the robot can convey the kind of ambiguity it is facing. In this article, we present DoRO (Disambiguation of Referred Object), a system that can help an embodied agent to disambiguate the referred object by raising a suitable query whenever required. Given an area where the intended object is, DoRO finds all the instances of the object by aggregating observations from multiple views while exploring & scanning the area. It then raises a suitable query using the information from the grounded object instances. Experiments conducted with the AI2Thor simulator show that DoRO not only detects the ambiguity more accurately but also raises verbose queries with more accurate information from the visual-language grounding.
Concurrent Transmission for Multi-Robot Coordination
Dec 01, 2021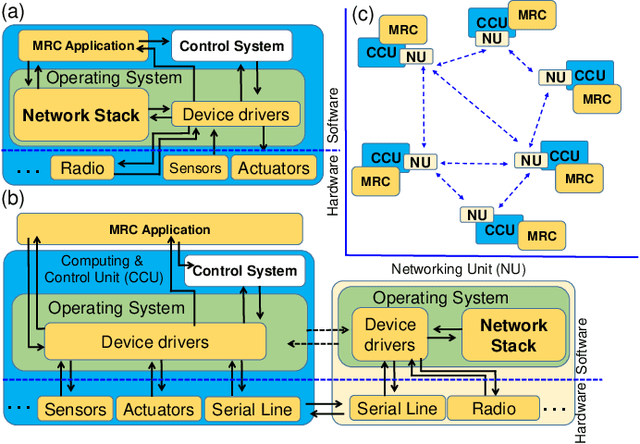
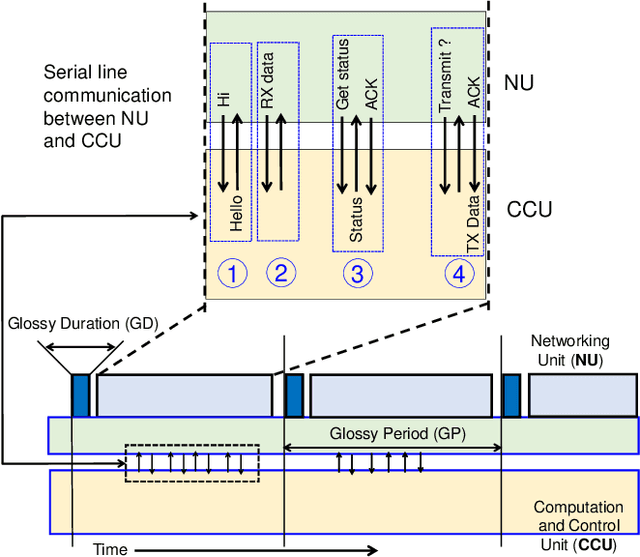

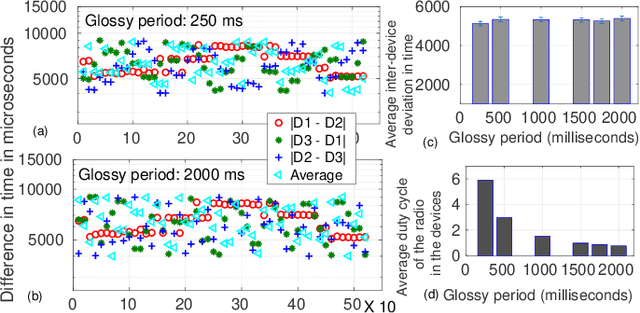
An efficient communication mechanism forms the backbone for any multi-robot system to achieve fruitful collaboration and coordination. Limitation in the existing asynchronous transmission based strategies in fast dissemination and aggregation compels the designers to prune down such requirements as much as possible. This also restricts the possible application areas of mobile multi-robot systems. In this work, we introduce concurrent transmission based strategy as an alternative. Despite the commonly found difficulties in concurrent transmission such as microsecond level time synchronization, hardware heterogeneity, etc., we demonstrate how it can be exploited for multi-robot systems. We propose a split architecture where the two major activities - communication and computation are carried out independently and coordinate through periodic interactions. The proposed split architecture is applied on a custom build full networked control system consisting of five two-wheel differential drive mobile robots having heterogeneous architecture. We use the proposed design in a leader-follower setting for coordinated dynamic speed variation as well as the independent formation of various shapes. Experiments show a centimeter-level spatial and millisecond-level temporal accuracy while spending very low radio duty-cycling over multi-hop communication under a wide testing area.
Talk-to-Resolve: Combining scene understanding and spatial dialogue to resolve granular task ambiguity for a collocated robot
Nov 22, 2021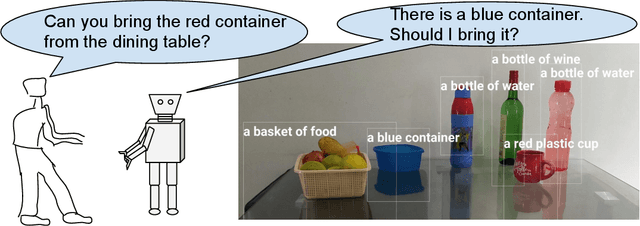
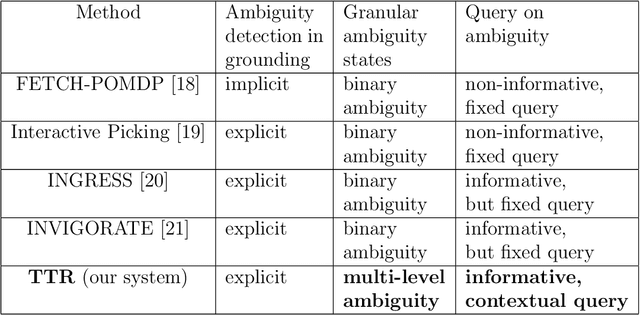
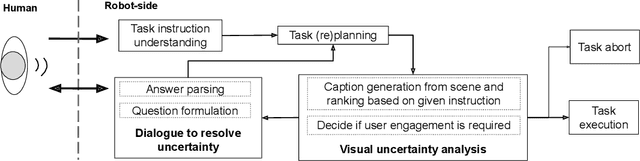

The utility of collocating robots largely depends on the easy and intuitive interaction mechanism with the human. If a robot accepts task instruction in natural language, first, it has to understand the user's intention by decoding the instruction. However, while executing the task, the robot may face unforeseeable circumstances due to the variations in the observed scene and therefore requires further user intervention. In this article, we present a system called Talk-to-Resolve (TTR) that enables a robot to initiate a coherent dialogue exchange with the instructor by observing the scene visually to resolve the impasse. Through dialogue, it either finds a cue to move forward in the original plan, an acceptable alternative to the original plan, or affirmation to abort the task altogether. To realize the possible stalemate, we utilize the dense captions of the observed scene and the given instruction jointly to compute the robot's next action. We evaluate our system based on a data set of initial instruction and situational scene pairs. Our system can identify the stalemate and resolve them with appropriate dialogue exchange with 82% accuracy. Additionally, a user study reveals that the questions from our systems are more natural (4.02 on average on a scale of 1 to 5) as compared to a state-of-the-art (3.08 on average).
A generalized algorithm and framework for online 3-dimensional bin packing in an automated sorting center
Nov 01, 2021
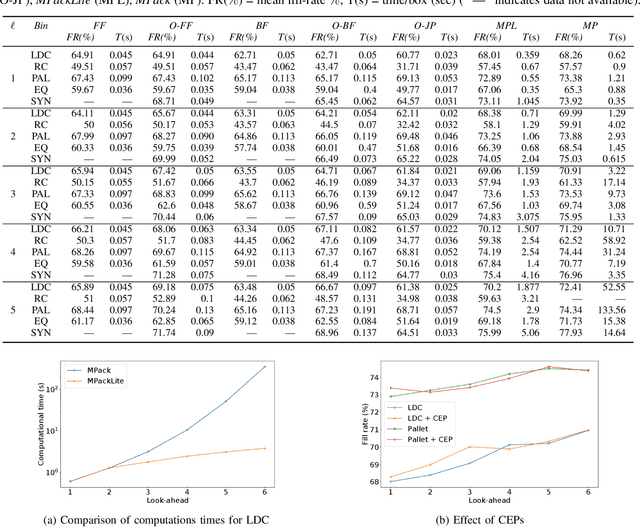
Online 3-dimensional bin packing problem (O3D-BPP) is getting renewed prominence due to the industrial automation brought by Industry 4.0. However, due to limited attention in the past and its challenging nature, a good approximate algorithm is in scarcity as compared to 1D or 2D problems. This paper considers real-time O$3$D-BPP of cuboidal boxes with partial information (look-ahead) in an automated robotic sorting center. We present two rolling-horizon mixed-integer linear programming (MILP) cum-heuristic based algorithms: MPack (for bench-marking) and MPackLite (for real-time deployment). Additionally, we present a framework OPack that adapts and improves the performance of BP heuristics by utilizing information in an online setting with a look-ahead. We then perform a comparative analysis of BP heuristics (with and without OPack), MPack, and MPackLite on synthetic and industry provided data with increasing look-ahead. MPackLite and the baseline heuristics perform within bounds of robot operations and thus, can be used in real-time.
Detecting socially interacting groups using f-formation: A survey of taxonomy, methods, datasets, applications, challenges, and future research directions
Aug 13, 2021
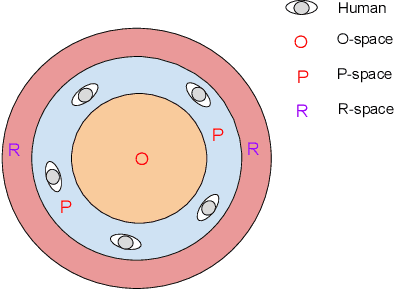
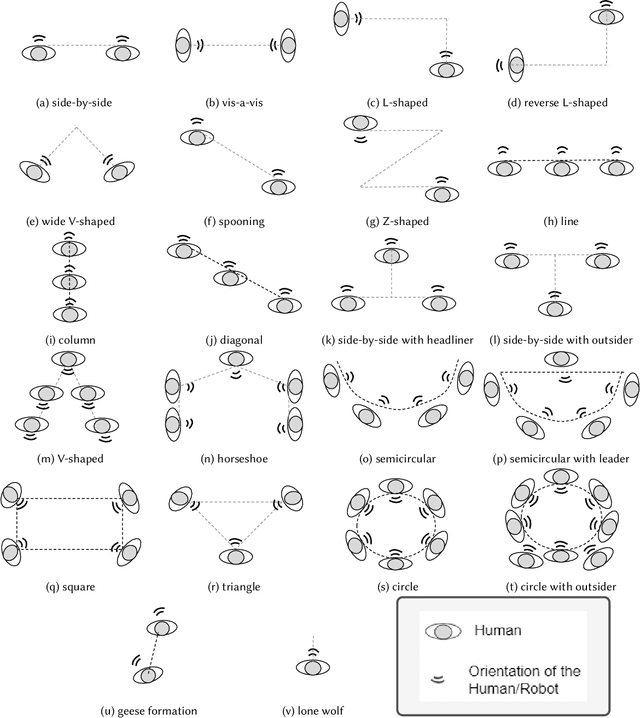
Robots in our daily surroundings are increasing day by day. Their usability and acceptability largely depend on their explicit and implicit interaction capability with fellow human beings. As a result, social behavior is one of the most sought-after qualities that a robot can possess. However, there is no specific aspect and/or feature that defines socially acceptable behavior and it largely depends on the situation, application, and society. In this article, we investigate one such social behavior for collocated robots. Imagine a group of people is interacting with each other and we want to join the group. We as human beings do it in a socially acceptable manner, i.e., within the group, we do position ourselves in such a way that we can participate in the group activity without disturbing/obstructing anybody. To possess such a quality, first, a robot needs to determine the formation of the group and then determine a position for itself, which we humans do implicitly. The theory of f-formation can be utilized for this purpose. As the types of formations can be very diverse, detecting the social groups is not a trivial task. In this article, we provide a comprehensive survey of the existing work on social interaction and group detection using f-formation for robotics and other applications. We also put forward a novel holistic survey framework combining all the possible concerns and modules relevant to this problem. We define taxonomies based on methods, camera views, datasets, detection capabilities and scale, evaluation approaches, and application areas. We discuss certain open challenges and limitations in current literature along with possible future research directions based on this framework. In particular, we discuss the existing methods/techniques and their relative merits and demerits, applications, and provide a set of unsolved but relevant problems in this domain.
Enabling human-like task identification from natural conversation
Aug 29, 2020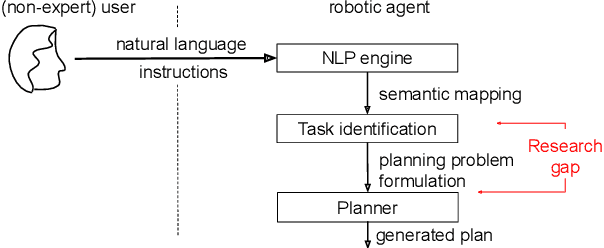
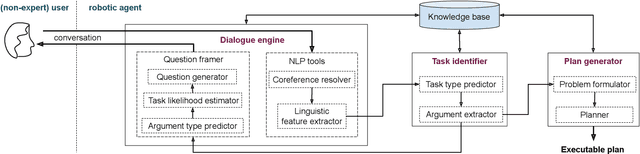
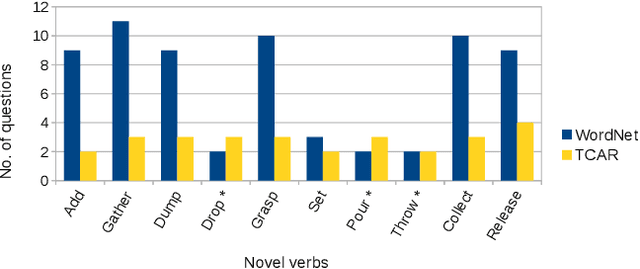
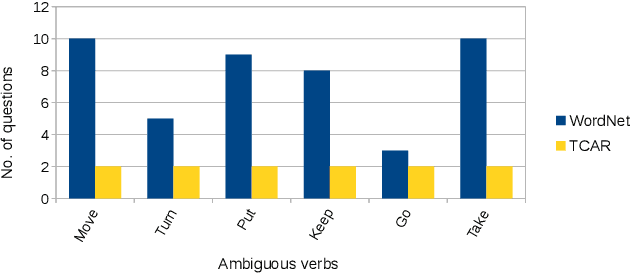
A robot as a coworker or a cohabitant is becoming mainstream day-by-day with the development of low-cost sophisticated hardware. However, an accompanying software stack that can aid the usability of the robotic hardware remains the bottleneck of the process, especially if the robot is not dedicated to a single job. Programming a multi-purpose robot requires an on the fly mission scheduling capability that involves task identification and plan generation. The problem dimension increases if the robot accepts tasks from a human in natural language. Though recent advances in NLP and planner development can solve a variety of complex problems, their amalgamation for a dynamic robotic task handler is used in a limited scope. Specifically, the problem of formulating a planning problem from natural language instructions is not studied in details. In this work, we provide a non-trivial method to combine an NLP engine and a planner such that a robot can successfully identify tasks and all the relevant parameters and generate an accurate plan for the task. Additionally, some mechanism is required to resolve the ambiguity or missing pieces of information in natural language instruction. Thus, we also develop a dialogue strategy that aims to gather additional information with minimal question-answer iterations and only when it is necessary. This work makes a significant stride towards enabling a human-like task understanding capability in a robot.