 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement Learning for Multi-Objective Optimization of Online Decisions in High-Dimensional Systems
Paper and Code
Oct 01, 2019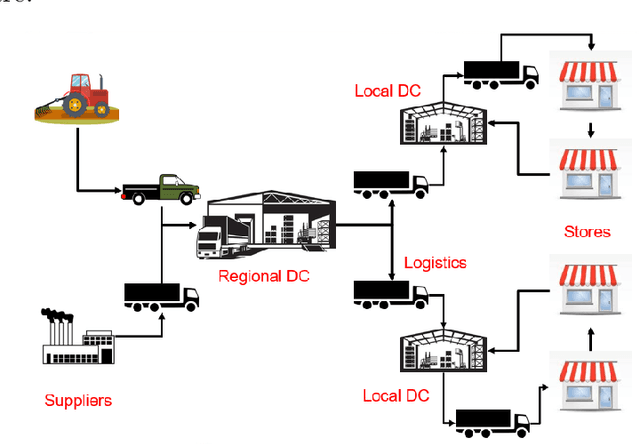

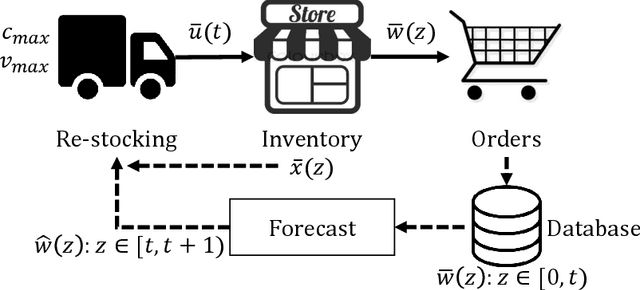

This paper describes a purely data-driven solution to a class of sequential decision-making problems with a large number of concurrent online decisions, with applications to computing systems and operations research. We assume that while the micro-level behaviour of the system can be broadly captured by analytical expressions or simulation, the macro-level or emergent behaviour is complicated by non-linearity, constraints, and stochasticity. If we represent the set of concurrent decisions to be computed as a vector, each element of the vector is assumed to be a continuous variable, and the number of such elements is arbitrarily large and variable from one problem instance to another. We first formulate the decision-making problem as a canonical reinforcement learning (RL) problem, which can be solved using purely data-driven techniques. We modify a standard approach known as advantage actor critic (A2C) to ensure its suitability to the problem at hand, and compare its performance to that of baseline approaches on the specific instance of a multi-product inventory management task. The key modifications include a parallelised formulation of the decision-making task, and a training procedure that explicitly recognises the quantitative relationship between different decisions. We also present experimental results probing the learned policies, and their robustness to variations in the data.