 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiLO: Disentangled Latent Optimization for Learning Shape and Deformation in Grouped Deforming 3D Objects
Nov 08, 2025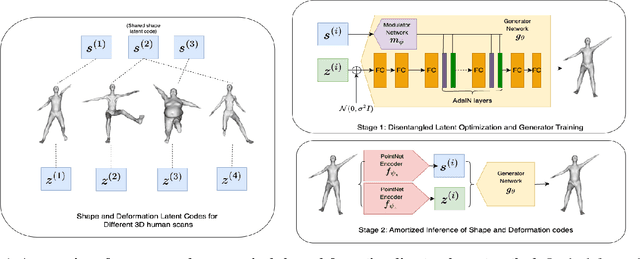
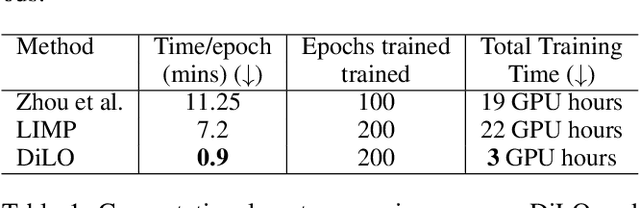

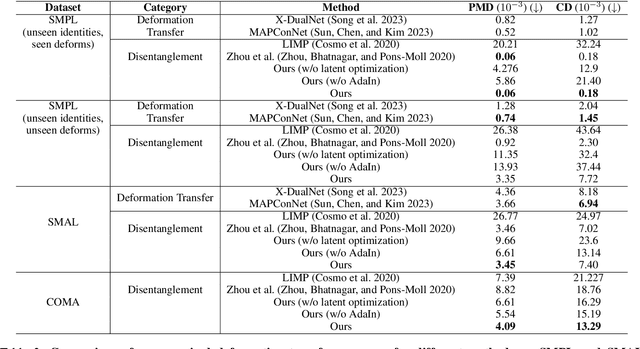
In this work, we propose a disentangled latent optimization-based method for parameterizing grouped deforming 3D objects into shape and deformation factors in an unsupervised manner. Our approach involves the joint optimization of a generator network along with the shape and deformation factors, supported by specific regularization techniques. For efficient amortized inference of disentangled shape and deformation codes, we train two order-invariant PoinNet-based encoder networks in the second stage of our method. We demonstrate several significant downstream applications of our method, including unsupervised deformation transfer, deformation classification, and explainability analysis. Extensive experiments conducted on 3D human, animal, and facial expression datasets demonstrate that our simple approach is highly effective in these downstream tasks, comparable or superior to existing methods with much higher complexity.
Reinforcement Learning for Sequence Design Leveraging Protein Language Models
Jul 03, 2024



Protein sequence design, determined by amino acid sequences, are essential to protein engineering problems in drug discovery. Prior approaches have resorted to evolutionary strategies or Monte-Carlo methods for protein design, but often fail to exploit the structure of the combinatorial search space, to generalize to unseen sequences. In the context of discrete black box optimization over large search spaces, learning a mutation policy to generate novel sequences with reinforcement learning is appealing. Recent advances in protein language models (PLMs) trained on large corpora of protein sequences offer a potential solution to this problem by scoring proteins according to their biological plausibility (such as the TM-score). In this work, we propose to use PLMs as a reward function to generate new sequences. Yet the PLM can be computationally expensive to query due to its large size. To this end, we propose an alternative paradigm where optimization can be performed on scores from a smaller proxy model that is periodically finetuned, jointly while learning the mutation policy. We perform extensive experiments on various sequence lengths to benchmark RL-based approaches, and provide comprehensive evaluations along biological plausibility and diversity of the protein. Our experimental results include favorable evaluations of the proposed sequences, along with high diversity scores, demonstrating that RL is a strong candidate for biological sequence design. Finally, we provide a modular open source implementation can be easily integrated in most RL training loops, with support for replacing the reward model with other PLMs, to spur further research in this domain. The code for all experiments is provided in the supplementary material.