 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrincipled Fine-tuning of LLMs from User-Edits: A Medley of Preference, Supervision, and Reward
Jan 27, 2026We study how to fine-tune LLMs using user-edit deployment data consisting of a set of context, an agent's response, and user edits. This deployment data is naturally generated by users in applications such as LLMs-based writing assistants and coding agents. The _natural_ origin of user edits makes it a desired source for adapting and personalizing LLMs. In this setup, there emerges a unification of various feedback types namely preferences, supervised labels, and cost that are typically studied separately in the literature. In this paper, we initiate the theoretical investigation of learning from user edits. We first derive bounds for learning algorithms that learn from each of these feedback types. We prove that these algorithms have different trade-offs depending upon the user, data distribution, and model class. We then propose a simple ensembling procedure to jointly learn from these feedback types. On two domains adapted from Gao et al. 2024, we show our ensembling procedure outperforms these methods that learn from individual feedback. Further, we show that our proposed procedure can robustly adapt to different user-edit distributions at test time.
Is Behavior Cloning All You Need? Understanding Horizon in Imitation Learning
Jul 20, 2024



Imitation learning (IL) aims to mimic the behavior of an expert in a sequential decision making task by learning from demonstrations, and has been widely applied to robotics, autonomous driving, and autoregressive text generation. The simplest approach to IL, behavior cloning (BC), is thought to incur sample complexity with unfavorable quadratic dependence on the problem horizon, motivating a variety of different online algorithms that attain improved linear horizon dependence under stronger assumptions on the data and the learner's access to the expert. We revisit the apparent gap between offline and online IL from a learning-theoretic perspective, with a focus on general policy classes up to and including deep neural networks. Through a new analysis of behavior cloning with the logarithmic loss, we show that it is possible to achieve horizon-independent sample complexity in offline IL whenever (i) the range of the cumulative payoffs is controlled, and (ii) an appropriate notion of supervised learning complexity for the policy class is controlled. Specializing our results to deterministic, stationary policies, we show that the gap between offline and online IL is not fundamental: (i) it is possible to achieve linear dependence on horizon in offline IL under dense rewards (matching what was previously only known to be achievable in online IL); and (ii) without further assumptions on the policy class, online IL cannot improve over offline IL with the logarithmic loss, even in benign MDPs. We complement our theoretical results with experiments on standard RL tasks and autoregressive language generation to validate the practical relevance of our findings.
Aligning LLM Agents by Learning Latent Preference from User Edits
Apr 23, 2024
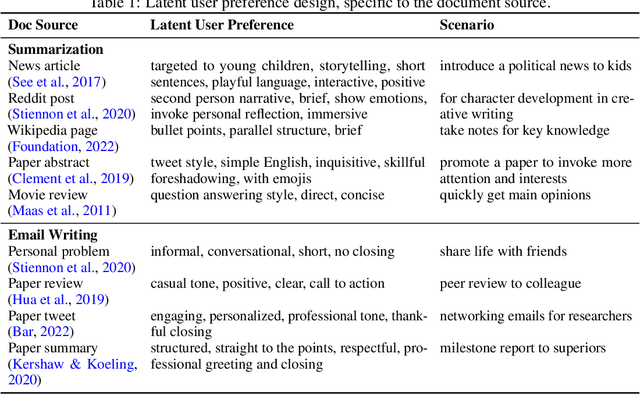


We study interactive learning of language agents based on user edits made to the agent's output. In a typical setting such as writing assistants, the user interacts with a language agent to generate a response given a context, and may optionally edit the agent response to personalize it based on their latent preference, in addition to improving the correctness. The edit feedback is naturally generated, making it a suitable candidate for improving the agent's alignment with the user's preference, and for reducing the cost of user edits over time. We propose a learning framework, PRELUDE that infers a description of the user's latent preference based on historic edit data and using it to define a prompt policy that drives future response generation. This avoids fine-tuning the agent, which is costly, challenging to scale with the number of users, and may even degrade its performance on other tasks. Furthermore, learning descriptive preference improves interpretability, allowing the user to view and modify the learned preference. However, user preference can be complex and vary based on context, making it challenging to learn. To address this, we propose a simple yet effective algorithm named CIPHER that leverages a large language model (LLM) to infer the user preference for a given context based on user edits. In the future, CIPHER retrieves inferred preferences from the k-closest contexts in the history, and forms an aggregate preference for response generation. We introduce two interactive environments -- summarization and email writing, for evaluation using a GPT-4 simulated user. We compare with algorithms that directly retrieve user edits but do not learn descriptive preference, and algorithms that learn context-agnostic preference. On both tasks, CIPHER achieves the lowest edit distance cost and learns preferences that show significant similarity to the ground truth preferences
Dataset Reset Policy Optimization for RLHF
Apr 15, 2024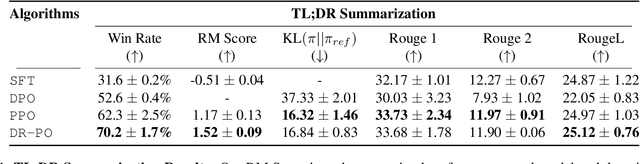
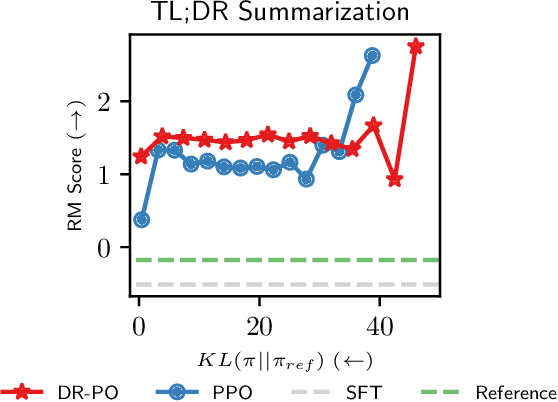


Reinforcement Learning (RL) from Human Preference-based feedback is a popular paradigm for fine-tuning generative models, which has produced impressive models such as GPT-4 and Claude3 Opus. This framework often consists of two steps: learning a reward model from an offline preference dataset followed by running online RL to optimize the learned reward model. In this work, leveraging the idea of reset, we propose a new RLHF algorithm with provable guarantees. Motivated by the fact that offline preference dataset provides informative states (i.e., data that is preferred by the labelers), our new algorithm, Dataset Reset Policy Optimization (DR-PO), integrates the existing offline preference dataset into the online policy training procedure via dataset reset: it directly resets the policy optimizer to the states in the offline dataset, instead of always starting from the initial state distribution. In theory, we show that DR-PO learns to perform at least as good as any policy that is covered by the offline dataset under general function approximation with finite sample complexity. In experiments, we demonstrate that on both the TL;DR summarization and the Anthropic Helpful Harmful (HH) dataset, the generation from DR-PO is better than that from Proximal Policy Optimization (PPO) and Direction Preference Optimization (DPO), under the metric of GPT4 win-rate. Code for this work can be found at https://github.com/Cornell-RL/drpo.
Provable Interactive Learning with Hindsight Instruction Feedback
Apr 14, 2024



We study interactive learning in a setting where the agent has to generate a response (e.g., an action or trajectory) given a context and an instruction. In contrast, to typical approaches that train the system using reward or expert supervision on response, we study learning with hindsight instruction where a teacher provides an instruction that is most suitable for the agent's generated response. This hindsight labeling of instruction is often easier to provide than providing expert supervision of the optimal response which may require expert knowledge or can be impractical to elicit. We initiate the theoretical analysis of interactive learning with hindsight labeling. We first provide a lower bound showing that in general, the regret of any algorithm must scale with the size of the agent's response space. We then study a specialized setting where the underlying instruction-response distribution can be decomposed as a low-rank matrix. We introduce an algorithm called LORIL for this setting and show that its regret scales as $\sqrt{T}$ where $T$ is the number of rounds and depends on the intrinsic rank but does not depend on the size of the agent's response space. We provide experiments in two domains showing that LORIL outperforms baselines even when the low-rank assumption is violated.
Towards Principled Representation Learning from Videos for Reinforcement Learning
Mar 20, 2024



We study pre-training representations for decision-making using video data, which is abundantly available for tasks such as game agents and software testing. Even though significant empirical advances have been made on this problem, a theoretical understanding remains absent. We initiate the theoretical investigation into principled approaches for representation learning and focus on learning the latent state representations of the underlying MDP using video data. We study two types of settings: one where there is iid noise in the observation, and a more challenging setting where there is also the presence of exogenous noise, which is non-iid noise that is temporally correlated, such as the motion of people or cars in the background. We study three commonly used approaches: autoencoding, temporal contrastive learning, and forward modeling. We prove upper bounds for temporal contrastive learning and forward modeling in the presence of only iid noise. We show that these approaches can learn the latent state and use it to do efficient downstream RL with polynomial sample complexity. When exogenous noise is also present, we establish a lower bound result showing that the sample complexity of learning from video data can be exponentially worse than learning from action-labeled trajectory data. This partially explains why reinforcement learning with video pre-training is hard. We evaluate these representational learning methods in two visual domains, yielding results that are consistent with our theoretical findings.
Policy Improvement using Language Feedback Models
Feb 25, 2024



We introduce Language Feedback Models (LFMs) that identify desirable behaviour - actions that help achieve tasks specified in the instruction - for imitation learning in instruction following. To train LFMs, we obtain feedback from Large Language Models (LLMs) on visual trajectories verbalized to language descriptions. First, by using LFMs to identify desirable behaviour to imitate, we improve in task-completion rate over strong behavioural cloning baselines on three distinct language grounding environments (Touchdown, ScienceWorld, and ALFWorld). Second, LFMs outperform using LLMs as experts to directly predict actions, when controlling for the number of LLM output tokens. Third, LFMs generalize to unseen environments, improving task-completion rate by 3.5-12.0% through one round of adaptation. Finally, LFM can be modified to provide human-interpretable feedback without performance loss, allowing human verification of desirable behaviour for imitation learning.
The Truth is in There: Improving Reasoning in Language Models with Layer-Selective Rank Reduction
Dec 21, 2023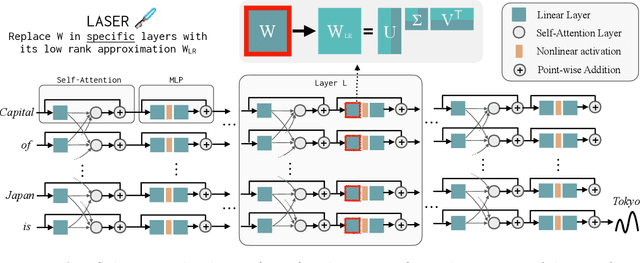



Transformer-based Large Language Models (LLMs) have become a fixture in modern machine learning. Correspondingly, significant resources are allocated towards research that aims to further advance this technology, typically resulting in models of increasing size that are trained on increasing amounts of data. This work, however, demonstrates the surprising result that it is often possible to significantly improve the performance of LLMs by selectively removing higher-order components of their weight matrices. This simple intervention, which we call LAyer-SElective Rank reduction (LASER), can be done on a model after training has completed, and requires no additional parameters or data. We show extensive experiments demonstrating the generality of this finding across language models and datasets, and provide in-depth analyses offering insights into both when LASER is effective and the mechanism by which it operates.
LLF-Bench: Benchmark for Interactive Learning from Language Feedback
Dec 13, 2023We introduce a new benchmark, LLF-Bench (Learning from Language Feedback Benchmark; pronounced as "elf-bench"), to evaluate the ability of AI agents to interactively learn from natural language feedback and instructions. Learning from language feedback (LLF) is essential for people, largely because the rich information this feedback provides can help a learner avoid much of trial and error and thereby speed up the learning process. Large Language Models (LLMs) have recently enabled AI agents to comprehend natural language -- and hence AI agents can potentially benefit from language feedback during learning like humans do. But existing interactive benchmarks do not assess this crucial capability: they either use numeric reward feedback or require no learning at all (only planning or information retrieval). LLF-Bench is designed to fill this omission. LLF-Bench is a diverse collection of sequential decision-making tasks that includes user recommendation, poem writing, navigation, and robot control. The objective of an agent is to interactively solve these tasks based on their natural-language instructions and the feedback received after taking actions. Crucially, to ensure that the agent actually "learns" from the feedback, LLF-Bench implements several randomization techniques (such as paraphrasing and environment randomization) to ensure that the task isn't familiar to the agent and that the agent is robust to various verbalizations. In addition, LLF-Bench provides a unified OpenAI Gym interface for all its tasks and allows the users to easily configure the information the feedback conveys (among suggestion, explanation, and instantaneous performance) to study how agents respond to different types of feedback. Together, these features make LLF-Bench a unique research platform for developing and testing LLF agents.
Learning to Generate Better Than Your LLM
Jun 20, 2023Reinforcement learning (RL) has emerged as a powerful paradigm for fine-tuning Large Language Models (LLMs) for conditional text generation. In particular, recent LLMs such as ChatGPT and GPT-4 can engage in fluent conversations with users by incorporating RL and feedback from humans. Inspired by learning-to-search algorithms and capitalizing on key properties of text generation, we seek to investigate reinforcement learning algorithms beyond general purpose algorithms such as Proximal policy optimization (PPO). In particular, we extend RL algorithms to allow them to interact with a dynamic black-box guide LLM such as GPT-3 and propose RL with guided feedback (RLGF), a suite of RL algorithms for LLM fine-tuning. We experiment on the IMDB positive review and CommonGen text generation task from the GRUE benchmark. We show that our RL algorithms achieve higher performance than supervised learning (SL) and default PPO baselines, demonstrating the benefit of interaction with the guide LLM. On CommonGen, we not only outperform our SL baselines but also improve beyond PPO across a variety of lexical and semantic metrics beyond the one we optimized for. Notably, on the IMDB dataset, we show that our GPT-2 based policy outperforms the zero-shot GPT-3 oracle, indicating that our algorithms can learn from a powerful, black-box GPT-3 oracle with a simpler, cheaper, and publicly available GPT-2 model while gaining performance.