 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProvable Interactive Learning with Hindsight Instruction Feedback
Apr 14, 2024



We study interactive learning in a setting where the agent has to generate a response (e.g., an action or trajectory) given a context and an instruction. In contrast, to typical approaches that train the system using reward or expert supervision on response, we study learning with hindsight instruction where a teacher provides an instruction that is most suitable for the agent's generated response. This hindsight labeling of instruction is often easier to provide than providing expert supervision of the optimal response which may require expert knowledge or can be impractical to elicit. We initiate the theoretical analysis of interactive learning with hindsight labeling. We first provide a lower bound showing that in general, the regret of any algorithm must scale with the size of the agent's response space. We then study a specialized setting where the underlying instruction-response distribution can be decomposed as a low-rank matrix. We introduce an algorithm called LORIL for this setting and show that its regret scales as $\sqrt{T}$ where $T$ is the number of rounds and depends on the intrinsic rank but does not depend on the size of the agent's response space. We provide experiments in two domains showing that LORIL outperforms baselines even when the low-rank assumption is violated.
Provably Sample-Efficient RL with Side Information about Latent Dynamics
May 27, 2022
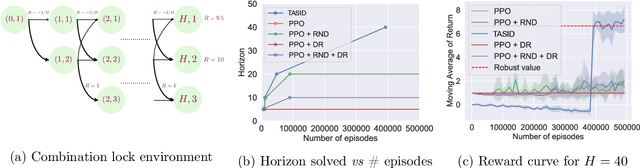

We study reinforcement learning (RL) in settings where observations are high-dimensional, but where an RL agent has access to abstract knowledge about the structure of the state space, as is the case, for example, when a robot is tasked to go to a specific room in a building using observations from its own camera, while having access to the floor plan. We formalize this setting as transfer reinforcement learning from an abstract simulator, which we assume is deterministic (such as a simple model of moving around the floor plan), but which is only required to capture the target domain's latent-state dynamics approximately up to unknown (bounded) perturbations (to account for environment stochasticity). Crucially, we assume no prior knowledge about the structure of observations in the target domain except that they can be used to identify the latent states (but the decoding map is unknown). Under these assumptions, we present an algorithm, called TASID, that learns a robust policy in the target domain, with sample complexity that is polynomial in the horizon, and independent of the number of states, which is not possible without access to some prior knowledge. In synthetic experiments, we verify various properties of our algorithm and show that it empirically outperforms transfer RL algorithms that require access to "full simulators" (i.e., those that also simulate observations).
Convex Analysis at Infinity: An Introduction to Astral Space
May 06, 2022Not all convex functions on $\mathbb{R}^n$ have finite minimizers; some can only be minimized by a sequence as it heads to infinity. In this work, we aim to develop a theory for understanding such minimizers at infinity. We study astral space, a compact extension of $\mathbb{R}^n$ to which such points at infinity have been added. Astral space is constructed to be as small as possible while still ensuring that all linear functions can be continuously extended to the new space. Although astral space includes all of $\mathbb{R}^n$, it is not a vector space, nor even a metric space. However, it is sufficiently well-structured to allow useful and meaningful extensions of concepts of convexity, conjugacy, and subdifferentials. We develop these concepts and analyze various properties of convex functions on astral space, including the detailed structure of their minimizers, exact characterizations of continuity, and convergence of descent algorithms.
Bayesian decision-making under misspecified priors with applications to meta-learning
Jul 03, 2021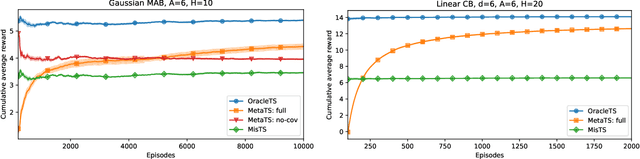
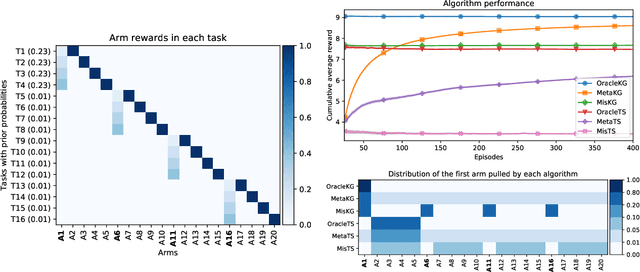
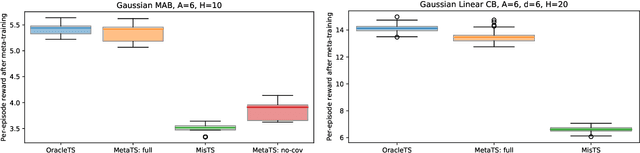
Thompson sampling and other Bayesian sequential decision-making algorithms are among the most popular approaches to tackle explore/exploit trade-offs in (contextual) bandits. The choice of prior in these algorithms offers flexibility to encode domain knowledge but can also lead to poor performance when misspecified. In this paper, we demonstrate that performance degrades gracefully with misspecification. We prove that the expected reward accrued by Thompson sampling (TS) with a misspecified prior differs by at most $\tilde{\mathcal{O}}(H^2 \epsilon)$ from TS with a well specified prior, where $\epsilon$ is the total-variation distance between priors and $H$ is the learning horizon. Our bound does not require the prior to have any parametric form. For priors with bounded support, our bound is independent of the cardinality or structure of the action space, and we show that it is tight up to universal constants in the worst case. Building on our sensitivity analysis, we establish generic PAC guarantees for algorithms in the recently studied Bayesian meta-learning setting and derive corollaries for various families of priors. Our results generalize along two axes: (1) they apply to a broader family of Bayesian decision-making algorithms, including a Monte-Carlo implementation of the knowledge gradient algorithm (KG), and (2) they apply to Bayesian POMDPs, the most general Bayesian decision-making setting, encompassing contextual bandits as a special case. Through numerical simulations, we illustrate how prior misspecification and the deployment of one-step look-ahead (as in KG) can impact the convergence of meta-learning in multi-armed and contextual bandits with structured and correlated priors.
Gradient descent follows the regularization path for general losses
Jun 19, 2020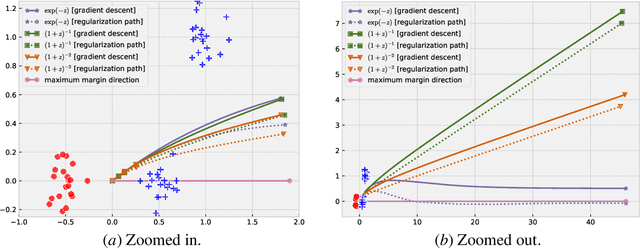
Recent work across many machine learning disciplines has highlighted that standard descent methods, even without explicit regularization, do not merely minimize the training error, but also exhibit an implicit bias. This bias is typically towards a certain regularized solution, and relies upon the details of the learning process, for instance the use of the cross-entropy loss. In this work, we show that for empirical risk minimization over linear predictors with arbitrary convex, strictly decreasing losses, if the risk does not attain its infimum, then the gradient-descent path and the algorithm-independent regularization path converge to the same direction (whenever either converges to a direction). Using this result, we provide a justification for the widely-used exponentially-tailed losses (such as the exponential loss or the logistic loss): while this convergence to a direction for exponentially-tailed losses is necessarily to the maximum-margin direction, other losses such as polynomially-tailed losses may induce convergence to a direction with a poor margin.
On Oracle-Efficient PAC RL with Rich Observations
Oct 31, 2018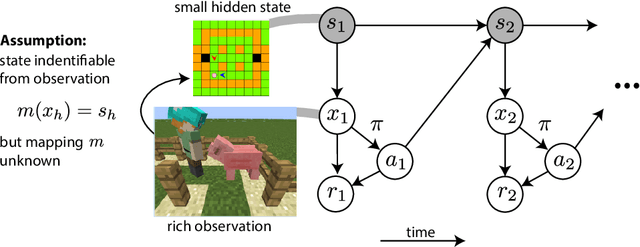
We study the computational tractability of PAC reinforcement learning with rich observations. We present new provably sample-efficient algorithms for environments with deterministic hidden state dynamics and stochastic rich observations. These methods operate in an oracle model of computation -- accessing policy and value function classes exclusively through standard optimization primitives -- and therefore represent computationally efficient alternatives to prior algorithms that require enumeration. With stochastic hidden state dynamics, we prove that the only known sample-efficient algorithm, OLIVE, cannot be implemented in the oracle model. We also present several examples that illustrate fundamental challenges of tractable PAC reinforcement learning in such general settings.
Practical Contextual Bandits with Regression Oracles
Mar 03, 2018


A major challenge in contextual bandits is to design general-purpose algorithms that are both practically useful and theoretically well-founded. We present a new technique that has the empirical and computational advantages of realizability-based approaches combined with the flexibility of agnostic methods. Our algorithms leverage the availability of a regression oracle for the value-function class, a more realistic and reasonable oracle than the classification oracles over policies typically assumed by agnostic methods. Our approach generalizes both UCB and LinUCB to far more expressive possible model classes and achieves low regret under certain distributional assumptions. In an extensive empirical evaluation, compared to both realizability-based and agnostic baselines, we find that our approach typically gives comparable or superior results.
Corralling a Band of Bandit Algorithms
Jun 06, 2017
We study the problem of combining multiple bandit algorithms (that is, online learning algorithms with partial feedback) with the goal of creating a master algorithm that performs almost as well as the best base algorithm if it were to be run on its own. The main challenge is that when run with a master, base algorithms unavoidably receive much less feedback and it is thus critical that the master not starve a base algorithm that might perform uncompetitively initially but would eventually outperform others if given enough feedback. We address this difficulty by devising a version of Online Mirror Descent with a special mirror map together with a sophisticated learning rate scheme. We show that this approach manages to achieve a more delicate balance between exploiting and exploring base algorithms than previous works yielding superior regret bounds. Our results are applicable to many settings, such as multi-armed bandits, contextual bandits, and convex bandits. As examples, we present two main applications. The first is to create an algorithm that enjoys worst-case robustness while at the same time performing much better when the environment is relatively easy. The second is to create an algorithm that works simultaneously under different assumptions of the environment, such as different priors or different loss structures.
Oracle-Efficient Online Learning and Auction Design
Apr 13, 2017



We consider the design of computationally efficient online learning algorithms in an adversarial setting in which the learner has access to an offline optimization oracle. We present an algorithm called Generalized Follow-the-Perturbed-Leader and provide conditions under which it is oracle-efficient while achieving vanishing regret. Our results make significant progress on an open problem raised by Hazan and Koren, who showed that oracle-efficient algorithms do not exist in general and asked whether one can identify properties under which oracle-efficient online learning may be possible. Our auction-design framework considers an auctioneer learning an optimal auction for a sequence of adversarially selected valuations with the goal of achieving revenue that is almost as good as the optimal auction in hindsight, among a class of auctions. We give oracle-efficient learning results for: (1) VCG auctions with bidder-specific reserves in single-parameter settings, (2) envy-free item pricing in multi-item auctions, and (3) s-level auctions of Morgenstern and Roughgarden for single-item settings. The last result leads to an approximation of the overall optimal Myerson auction when bidders' valuations are drawn according to a fast-mixing Markov process, extending prior work that only gave such guarantees for the i.i.d. setting. Finally, we derive various extensions, including: (1) oracle-efficient algorithms for the contextual learning setting in which the learner has access to side information (such as bidder demographics), (2) learning with approximate oracles such as those based on Maximal-in-Range algorithms, and (3) no-regret bidding in simultaneous auctions, resolving an open problem of Daskalakis and Syrgkanis.
Unsupervised Domain Adaptation Using Approximate Label Matching
Mar 01, 2017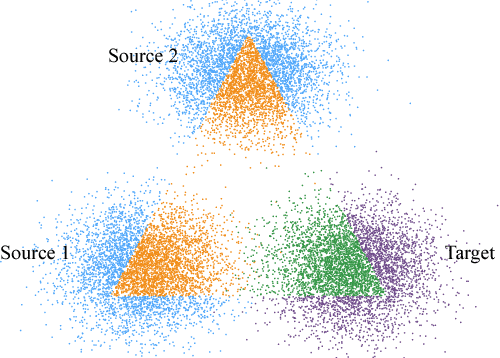

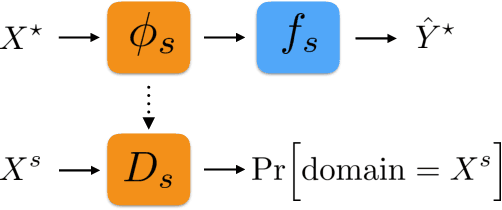
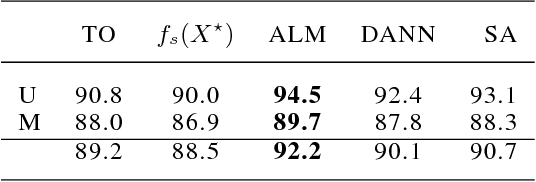
Domain adaptation addresses the problem created when training data is generated by a so-called source distribution, but test data is generated by a significantly different target distribution. In this work, we present approximate label matching (ALM), a new unsupervised domain adaptation technique that creates and leverages a rough labeling on the test samples, then uses these noisy labels to learn a transformation that aligns the source and target samples. We show that the transformation estimated by ALM has favorable properties compared to transformations estimated by other methods, which do not use any kind of target labeling. Our model is regularized by requiring that a classifier trained to discriminate source from transformed target samples cannot distinguish between the two. We experiment with ALM on simulated and real data, and show that it outperforms techniques commonly used in the field.