 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProvably Sample-Efficient RL with Side Information about Latent Dynamics
May 27, 2022
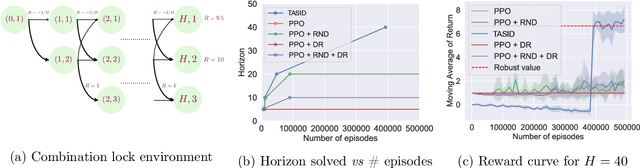

We study reinforcement learning (RL) in settings where observations are high-dimensional, but where an RL agent has access to abstract knowledge about the structure of the state space, as is the case, for example, when a robot is tasked to go to a specific room in a building using observations from its own camera, while having access to the floor plan. We formalize this setting as transfer reinforcement learning from an abstract simulator, which we assume is deterministic (such as a simple model of moving around the floor plan), but which is only required to capture the target domain's latent-state dynamics approximately up to unknown (bounded) perturbations (to account for environment stochasticity). Crucially, we assume no prior knowledge about the structure of observations in the target domain except that they can be used to identify the latent states (but the decoding map is unknown). Under these assumptions, we present an algorithm, called TASID, that learns a robust policy in the target domain, with sample complexity that is polynomial in the horizon, and independent of the number of states, which is not possible without access to some prior knowledge. In synthetic experiments, we verify various properties of our algorithm and show that it empirically outperforms transfer RL algorithms that require access to "full simulators" (i.e., those that also simulate observations).
Interactive Learning from Activity Description
Feb 13, 2021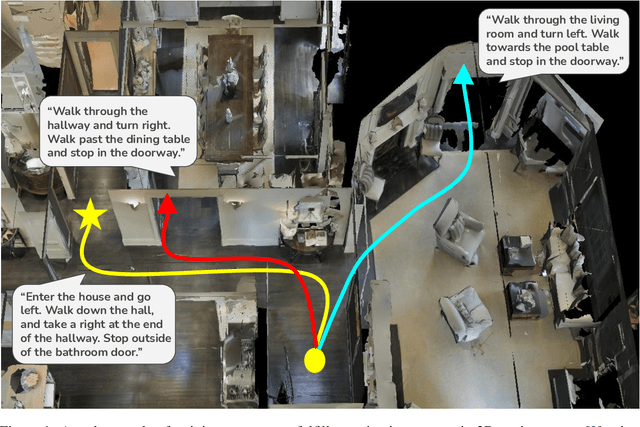

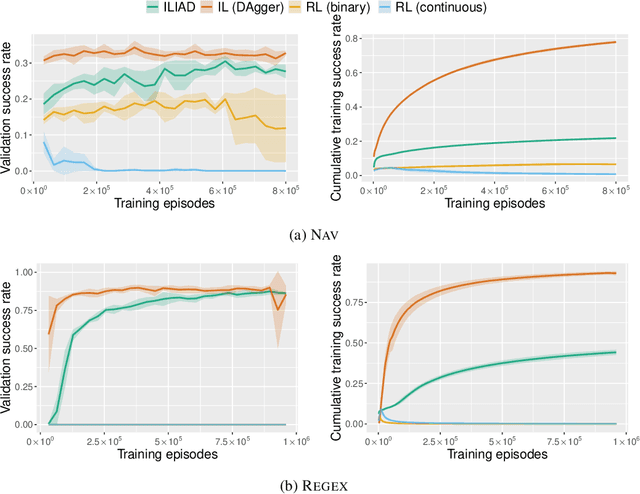
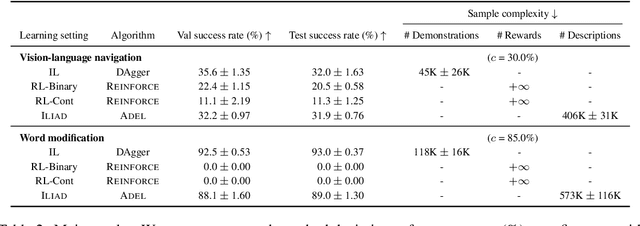
We present a novel interactive learning protocol that enables training request-fulfilling agents by verbally describing their activities. Our protocol gives rise to a new family of interactive learning algorithms that offer complementary advantages against traditional algorithms like imitation learning (IL) and reinforcement learning (RL). We develop an algorithm that practically implements this protocol and employ it to train agents in two challenging request-fulfilling problems using purely language-description feedback. Empirical results demonstrate the strengths of our algorithm: compared to RL baselines, it is more sample-efficient; compared to IL baselines, it achieves competitive success rates while not requiring feedback providers to have agent-specific expertise. We also provide theoretical guarantees of the algorithm under certain assumptions on the teacher and the environment.
Improving fairness in machine learning systems: What do industry practitioners need?
Jan 07, 2019
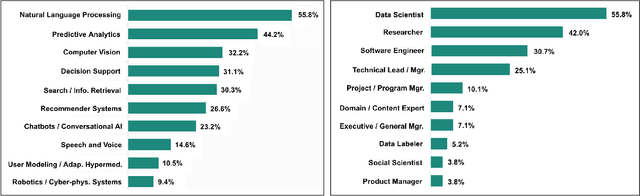
The potential for machine learning (ML) systems to amplify social inequities and unfairness is receiving increasing popular and academic attention. A surge of recent work has focused on the development of algorithmic tools to assess and mitigate such unfairness. If these tools are to have a positive impact on industry practice, however, it is crucial that their design be informed by an understanding of real-world needs. Through 35 semi-structured interviews and an anonymous survey of 267 ML practitioners, we conduct the first systematic investigation of commercial product teams' challenges and needs for support in developing fairer ML systems. We identify areas of alignment and disconnect between the challenges faced by industry practitioners and solutions proposed in the fair ML research literature. Based on these findings, we highlight directions for future ML and HCI research that will better address industry practitioners' needs.