 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Extract Context for Context-Aware LLM Inference
Dec 12, 2025User prompts to large language models (LLMs) are often ambiguous or under-specified, and subtle contextual cues shaped by user intentions, prior knowledge, and risk factors strongly influence what constitutes an appropriate response. Misinterpreting intent or risks may lead to unsafe outputs, while overly cautious interpretations can cause unnecessary refusal of benign requests. In this paper, we question the conventional framework in which LLMs generate immediate responses to requests without considering broader contextual factors. User requests are situated within broader contexts such as intentions, knowledge, and prior experience, which strongly influence what constitutes an appropriate answer. We propose a framework that extracts and leverages such contextual information from the user prompt itself. Specifically, a reinforcement learning based context generator, designed in an autoencoder-like fashion, is trained to infer contextual signals grounded in the prompt and use them to guide response generation. This approach is particularly important for safety tasks, where ambiguous requests may bypass safeguards while benign but confusing requests can trigger unnecessary refusals. Experiments show that our method reduces harmful responses by an average of 5.6% on the SafetyInstruct dataset across multiple foundation models and improves the harmonic mean of attack success rate and compliance on benign prompts by 6.2% on XSTest and WildJailbreak. These results demonstrate the effectiveness of context extraction for safer and more reliable LLM inferences.
Gistify! Codebase-Level Understanding via Runtime Execution
Oct 30, 2025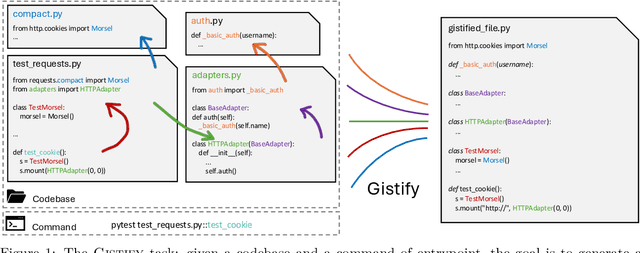
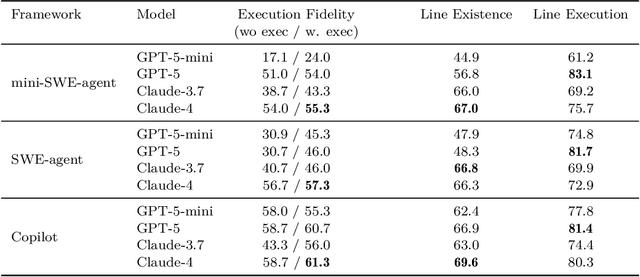

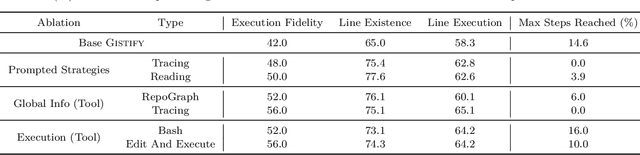
As coding agents are increasingly deployed in large codebases, the need to automatically design challenging, codebase-level evaluation is central. We propose Gistify, a task where a coding LLM must create a single, minimal, self-contained file that can reproduce a specific functionality of a codebase. The coding LLM is given full access to a codebase along with a specific entrypoint (e.g., a python command), and the generated file must replicate the output of the same command ran under the full codebase, while containing only the essential components necessary to execute the provided command. Success on Gistify requires both structural understanding of the codebase, accurate modeling of its execution flow as well as the ability to produce potentially large code patches. Our findings show that current state-of-the-art models struggle to reliably solve Gistify tasks, especially ones with long executions traces.
TALES: Text Adventure Learning Environment Suite
Apr 22, 2025Reasoning is an essential skill to enable Large Language Models (LLMs) to interact with the world. As tasks become more complex, they demand increasingly sophisticated and diverse reasoning capabilities for sequential decision-making, requiring structured reasoning over the context history to determine the next best action. We introduce TALES, a diverse collection of synthetic and human-written text-adventure games designed to challenge and evaluate diverse reasoning capabilities. We present results over a range of LLMs, open- and closed-weights, performing a qualitative analysis on the top performing models. Despite an impressive showing on synthetic games, even the top LLM-driven agents fail to achieve 15% on games designed for human enjoyment. Code and visualization of the experiments can be found at https://microsoft.github.io/tales.
debug-gym: A Text-Based Environment for Interactive Debugging
Mar 27, 2025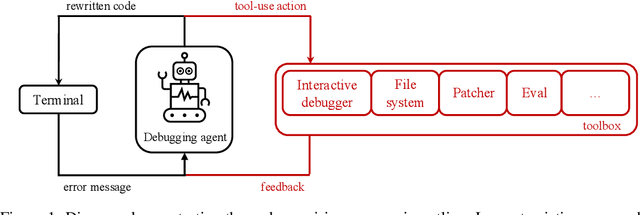
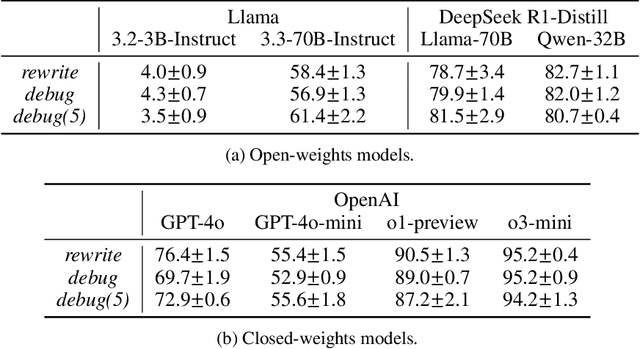
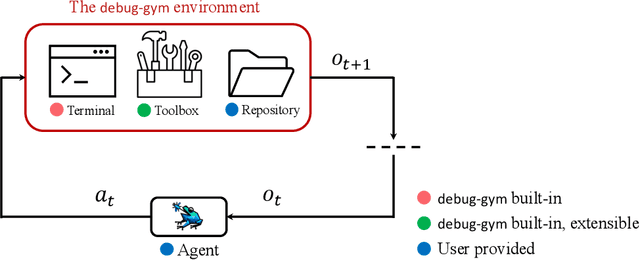
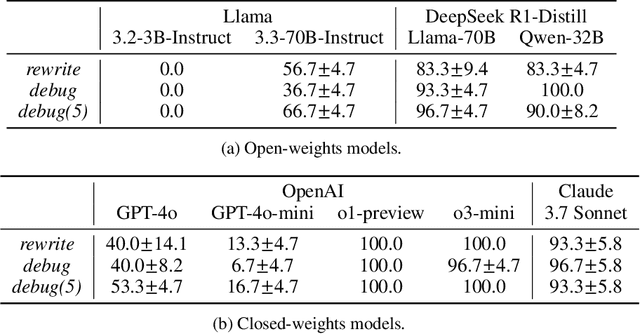
Large Language Models (LLMs) are increasingly relied upon for coding tasks, yet in most scenarios it is assumed that all relevant information can be either accessed in context or matches their training data. We posit that LLMs can benefit from the ability to interactively explore a codebase to gather the information relevant to their task. To achieve this, we present a textual environment, namely debug-gym, for developing LLM-based agents in an interactive coding setting. Our environment is lightweight and provides a preset of useful tools, such as a Python debugger (pdb), designed to facilitate an LLM-based agent's interactive debugging. Beyond coding and debugging tasks, this approach can be generalized to other tasks that would benefit from information-seeking behavior by an LLM agent.
Enhancing Agent Learning through World Dynamics Modeling
Jul 25, 2024While large language models (LLMs) have been increasingly deployed across tasks in language understanding and interactive decision-making, their impressive performance is largely due to the comprehensive and in-depth domain knowledge embedded within them. However, the extent of this knowledge can vary across different domains. Existing methods often assume that LLMs already possess such comprehensive and in-depth knowledge of their environment, overlooking potential gaps in their understanding of actual world dynamics. To address this gap, we introduce Discover, Verify, and Evolve (DiVE), a framework that discovers world dynamics from a small number of demonstrations, verifies the correctness of these dynamics, and evolves new, advanced dynamics tailored to the current situation. Through extensive evaluations, we analyze the impact of each component on performance and compare the automatically generated dynamics from DiVE with human-annotated world dynamics. Our results demonstrate that LLMs guided by DiVE can make better decisions, achieving rewards comparable to human players in the Crafter environment.
IDAT: A Multi-Modal Dataset and Toolkit for Building and Evaluating Interactive Task-Solving Agents
Jul 12, 2024



Seamless interaction between AI agents and humans using natural language remains a key goal in AI research. This paper addresses the challenges of developing interactive agents capable of understanding and executing grounded natural language instructions through the IGLU competition at NeurIPS. Despite advancements, challenges such as a scarcity of appropriate datasets and the need for effective evaluation platforms persist. We introduce a scalable data collection tool for gathering interactive grounded language instructions within a Minecraft-like environment, resulting in a Multi-Modal dataset with around 9,000 utterances and over 1,000 clarification questions. Additionally, we present a Human-in-the-Loop interactive evaluation platform for qualitative analysis and comparison of agent performance through multi-turn communication with human annotators. We offer to the community these assets referred to as IDAT (IGLU Dataset And Toolkit) which aim to advance the development of intelligent, interactive AI agents and provide essential resources for further research.
DISCOVERYWORLD: A Virtual Environment for Developing and Evaluating Automated Scientific Discovery Agents
Jun 10, 2024



Automated scientific discovery promises to accelerate progress across scientific domains. However, developing and evaluating an AI agent's capacity for end-to-end scientific reasoning is challenging as running real-world experiments is often prohibitively expensive or infeasible. In this work we introduce DISCOVERYWORLD, the first virtual environment for developing and benchmarking an agent's ability to perform complete cycles of novel scientific discovery. DISCOVERYWORLD contains a variety of different challenges, covering topics as diverse as radioisotope dating, rocket science, and proteomics, to encourage development of general discovery skills rather than task-specific solutions. DISCOVERYWORLD itself is an inexpensive, simulated, text-based environment (with optional 2D visual overlay). It includes 120 different challenge tasks, spanning eight topics each with three levels of difficulty and several parametric variations. Each task requires an agent to form hypotheses, design and run experiments, analyze results, and act on conclusions. DISCOVERYWORLD further provides three automatic metrics for evaluating performance, based on (a) task completion, (b) task-relevant actions taken, and (c) the discovered explanatory knowledge. We find that strong baseline agents, that perform well in prior published environments, struggle on most DISCOVERYWORLD tasks, suggesting that DISCOVERYWORLD captures some of the novel challenges of discovery, and thus that DISCOVERYWORLD may help accelerate near-term development and assessment of scientific discovery competency in agents. Code available at: www.github.com/allenai/discoveryworld
Can Language Models Serve as Text-Based World Simulators?
Jun 10, 2024



Virtual environments play a key role in benchmarking advances in complex planning and decision-making tasks but are expensive and complicated to build by hand. Can current language models themselves serve as world simulators, correctly predicting how actions change different world states, thus bypassing the need for extensive manual coding? Our goal is to answer this question in the context of text-based simulators. Our approach is to build and use a new benchmark, called ByteSized32-State-Prediction, containing a dataset of text game state transitions and accompanying game tasks. We use this to directly quantify, for the first time, how well LLMs can serve as text-based world simulators. We test GPT-4 on this dataset and find that, despite its impressive performance, it is still an unreliable world simulator without further innovations. This work thus contributes both new insights into current LLM's capabilities and weaknesses, as well as a novel benchmark to track future progress as new models appear.
OPEx: A Component-Wise Analysis of LLM-Centric Agents in Embodied Instruction Following
Mar 05, 2024



Embodied Instruction Following (EIF) is a crucial task in embodied learning, requiring agents to interact with their environment through egocentric observations to fulfill natural language instructions. Recent advancements have seen a surge in employing large language models (LLMs) within a framework-centric approach to enhance performance in embodied learning tasks, including EIF. Despite these efforts, there exists a lack of a unified understanding regarding the impact of various components-ranging from visual perception to action execution-on task performance. To address this gap, we introduce OPEx, a comprehensive framework that delineates the core components essential for solving embodied learning tasks: Observer, Planner, and Executor. Through extensive evaluations, we provide a deep analysis of how each component influences EIF task performance. Furthermore, we innovate within this space by deploying a multi-agent dialogue strategy on a TextWorld counterpart, further enhancing task performance. Our findings reveal that LLM-centric design markedly improves EIF outcomes, identify visual perception and low-level action execution as critical bottlenecks, and demonstrate that augmenting LLMs with a multi-agent framework further elevates performance.
Language-guided Skill Learning with Temporal Variational Inference
Feb 26, 2024



We present an algorithm for skill discovery from expert demonstrations. The algorithm first utilizes Large Language Models (LLMs) to propose an initial segmentation of the trajectories. Following that, a hierarchical variational inference framework incorporates the LLM-generated segmentation information to discover reusable skills by merging trajectory segments. To further control the trade-off between compression and reusability, we introduce a novel auxiliary objective based on the Minimum Description Length principle that helps guide this skill discovery process. Our results demonstrate that agents equipped with our method are able to discover skills that help accelerate learning and outperform baseline skill learning approaches on new long-horizon tasks in BabyAI, a grid world navigation environment, as well as ALFRED, a household simulation environment.