 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMatter-of-Fact: A Benchmark for Verifying the Feasibility of Literature-Supported Claims in Materials Science
Jun 04, 2025Contemporary approaches to assisted scientific discovery use language models to automatically generate large numbers of potential hypothesis to test, while also automatically generating code-based experiments to test those hypotheses. While hypotheses can be comparatively inexpensive to generate, automated experiments can be costly, particularly when run at scale (i.e. thousands of experiments). Developing the capacity to filter hypotheses based on their feasibility would allow discovery systems to run at scale, while increasing their likelihood of making significant discoveries. In this work we introduce Matter-of-Fact, a challenge dataset for determining the feasibility of hypotheses framed as claims. Matter-of-Fact includes 8.4k claims extracted from scientific articles spanning four high-impact contemporary materials science topics, including superconductors, semiconductors, batteries, and aerospace materials, while including qualitative and quantitative claims from theoretical, experimental, and code/simulation results. We show that strong baselines that include retrieval augmented generation over scientific literature and code generation fail to exceed 72% performance on this task (chance performance is 50%), while domain-expert verification suggests nearly all are solvable -- highlighting both the difficulty of this task for current models, and the potential to accelerate scientific discovery by making near-term progress.
Can Language Models Serve as Text-Based World Simulators?
Jun 10, 2024



Virtual environments play a key role in benchmarking advances in complex planning and decision-making tasks but are expensive and complicated to build by hand. Can current language models themselves serve as world simulators, correctly predicting how actions change different world states, thus bypassing the need for extensive manual coding? Our goal is to answer this question in the context of text-based simulators. Our approach is to build and use a new benchmark, called ByteSized32-State-Prediction, containing a dataset of text game state transitions and accompanying game tasks. We use this to directly quantify, for the first time, how well LLMs can serve as text-based world simulators. We test GPT-4 on this dataset and find that, despite its impressive performance, it is still an unreliable world simulator without further innovations. This work thus contributes both new insights into current LLM's capabilities and weaknesses, as well as a novel benchmark to track future progress as new models appear.
Self-Supervised Behavior Cloned Transformers are Path Crawlers for Text Games
Dec 07, 2023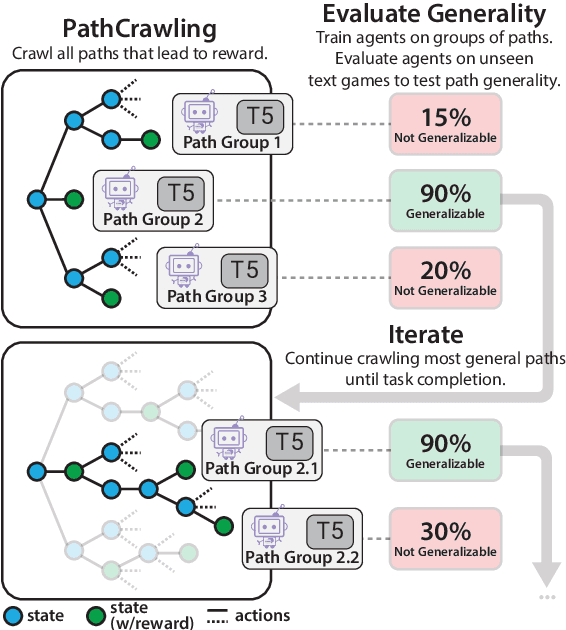
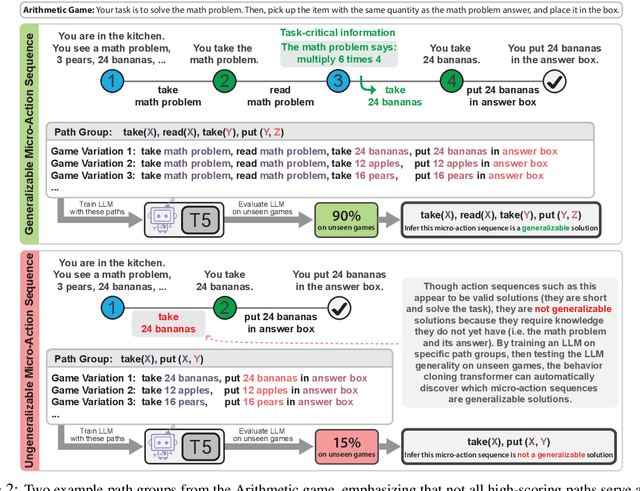

In this work, we introduce a self-supervised behavior cloning transformer for text games, which are challenging benchmarks for multi-step reasoning in virtual environments. Traditionally, Behavior Cloning Transformers excel in such tasks but rely on supervised training data. Our approach auto-generates training data by exploring trajectories (defined by common macro-action sequences) that lead to reward within the games, while determining the generality and utility of these trajectories by rapidly training small models then evaluating their performance on unseen development games. Through empirical analysis, we show our method consistently uncovers generalizable training data, achieving about 90\% performance of supervised systems across three benchmark text games.
ByteSized32: A Corpus and Challenge Task for Generating Task-Specific World Models Expressed as Text Games
May 24, 2023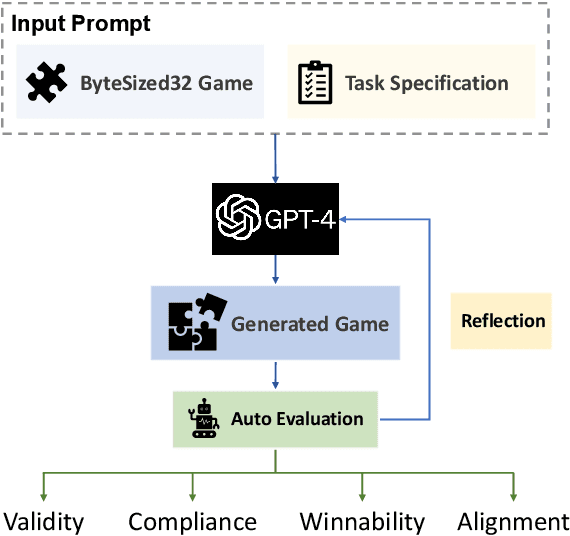
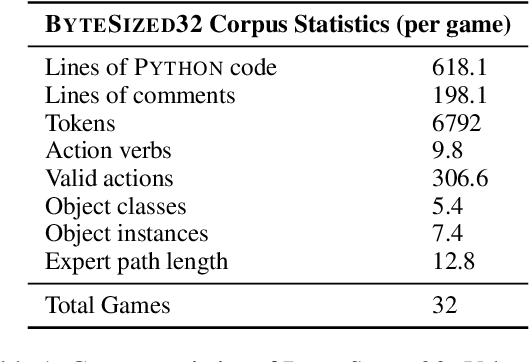

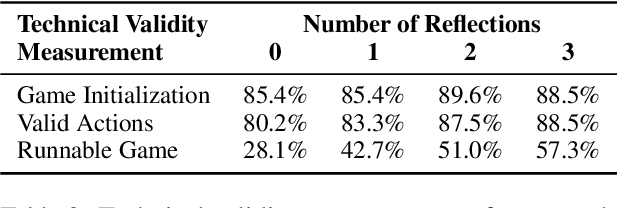
In this work we examine the ability of language models to generate explicit world models of scientific and common-sense reasoning tasks by framing this as a problem of generating text-based games. To support this, we introduce ByteSized32, a corpus of 32 highly-templated text games written in Python totaling 24k lines of code, each centered around a particular task, and paired with a set of 16 unseen text game specifications for evaluation. We propose a suite of automatic and manual metrics for assessing simulation validity, compliance with task specifications, playability, winnability, and alignment with the physical world. In a single-shot evaluation of GPT-4 on this simulation-as-code-generation task, we find it capable of producing runnable games in 27% of cases, highlighting the difficulty of this challenge task. We discuss areas of future improvement, including GPT-4's apparent capacity to perform well at simulating near canonical task solutions, with performance dropping off as simulations include distractors or deviate from canonical solutions in the action space.
Behavior Cloned Transformers are Neurosymbolic Reasoners
Oct 13, 2022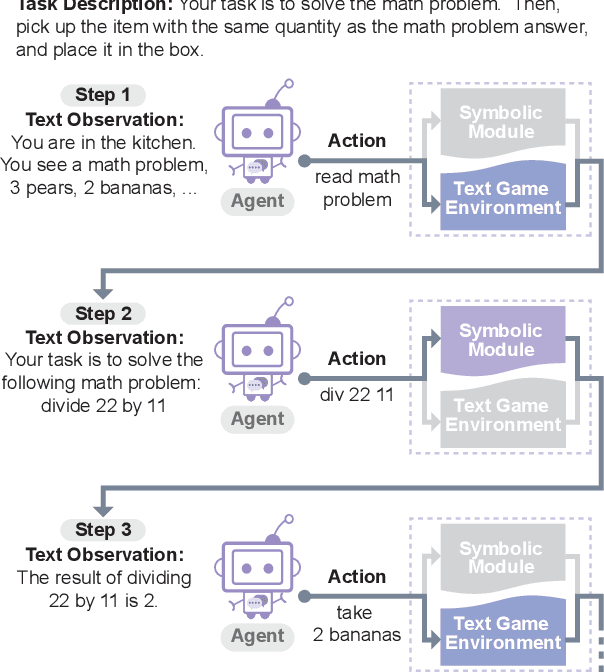

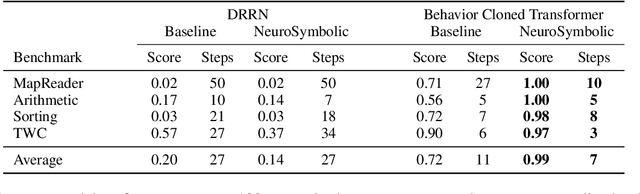
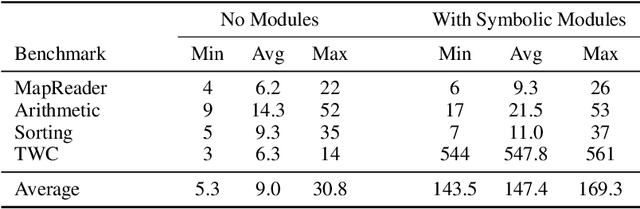
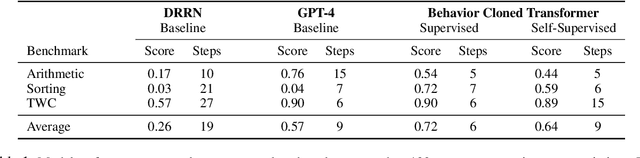
In this work, we explore techniques for augmenting interactive agents with information from symbolic modules, much like humans use tools like calculators and GPS systems to assist with arithmetic and navigation. We test our agent's abilities in text games -- challenging benchmarks for evaluating the multi-step reasoning abilities of game agents in grounded, language-based environments. Our experimental study indicates that injecting the actions from these symbolic modules into the action space of a behavior cloned transformer agent increases performance on four text game benchmarks that test arithmetic, navigation, sorting, and common sense reasoning by an average of 22%, allowing an agent to reach the highest possible performance on unseen games. This action injection technique is easily extended to new agents, environments, and symbolic modules.
ScienceWorld: Is your Agent Smarter than a 5th Grader?
Mar 14, 2022
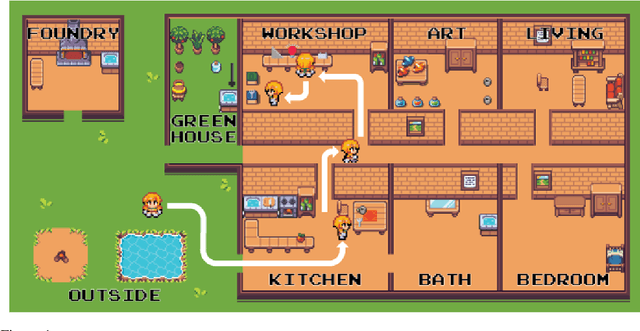

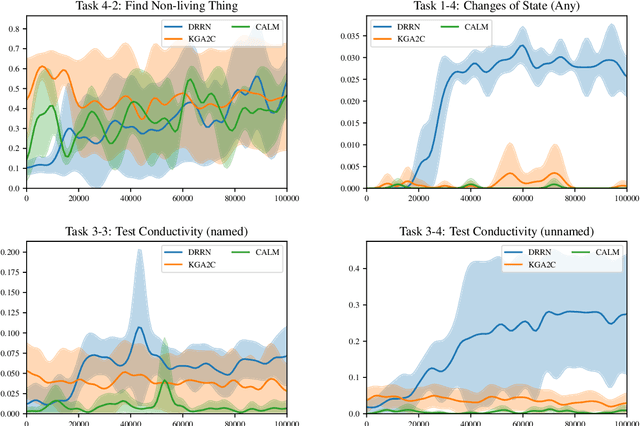
This paper presents a new benchmark, ScienceWorld, to test agents' scientific reasoning abilities in a new interactive text environment at the level of a standard elementary school science curriculum. Despite the recent transformer-based progress seen in adjacent fields such as question-answering, scientific text processing, and the wider area of natural language processing, we find that current state-of-the-art models are unable to reason about or explain learned science concepts in novel contexts. For instance, models can easily answer what the conductivity of a previously seen material is but struggle when asked how they would conduct an experiment in a grounded, interactive environment to find the conductivity of an unknown material. This begs the question of whether current models are simply retrieving answers by way of seeing a large number of similar input examples or if they have learned to reason about concepts in a reusable manner. We hypothesize that agents need to be grounded in interactive environments to achieve such reasoning capabilities. Our experiments provide empirical evidence supporting this hypothesis -- showing that a 1.5 million parameter agent trained interactively for 100k steps outperforms a 11 billion parameter model statically trained for scientific question-answering and reasoning via millions of expert demonstrations.
Fill-in-the-blank as a Challenging Video Understanding Evaluation Framework
Apr 09, 2021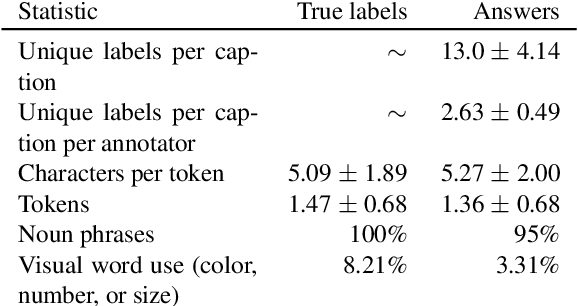
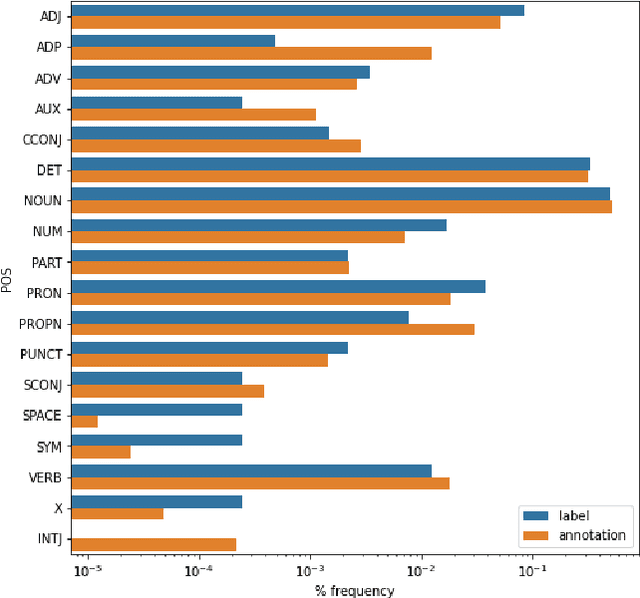
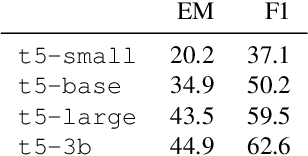
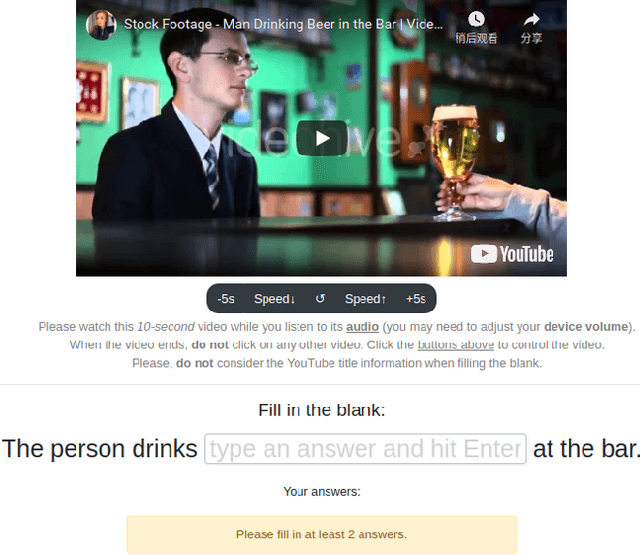
Work to date on language-informed video understanding has primarily addressed two tasks: (1) video question answering using multiple-choice questions, where models perform relatively well because they exploit the fact that candidate answers are readily available; and (2) video captioning, which relies on an open-ended evaluation framework that is often inaccurate because system answers may be perceived as incorrect if they differ in form from the ground truth. In this paper, we propose fill-in-the-blanks as a video understanding evaluation framework that addresses these previous evaluation drawbacks, and more closely reflects real-life settings where no multiple choices are given. The task tests a system understanding of a video by requiring the model to predict a masked noun phrase in the caption of the video, given the video and the surrounding text. We introduce a novel dataset consisting of 28,000 videos and fill-in-the-blank tests. We show that both a multimodal model and a strong language model have a large gap with human performance, thus suggesting that the task is more challenging than current video understanding benchmarks.