 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Behavior Cloned Transformers are Path Crawlers for Text Games
Paper and Code
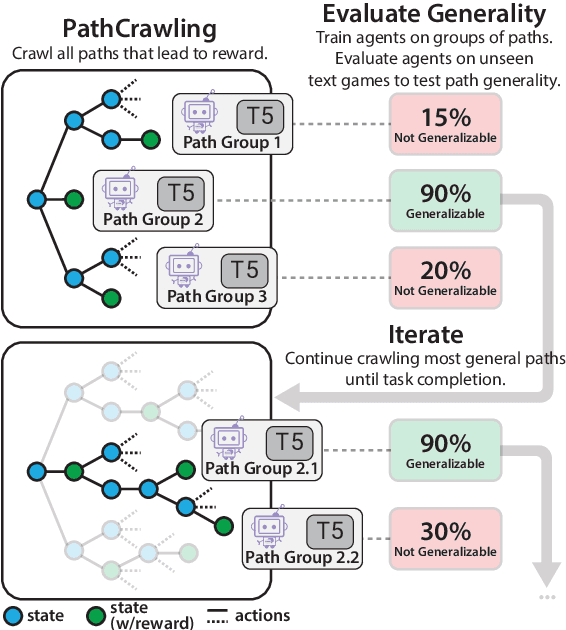
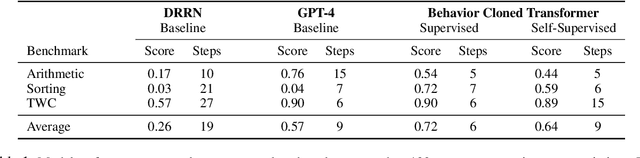
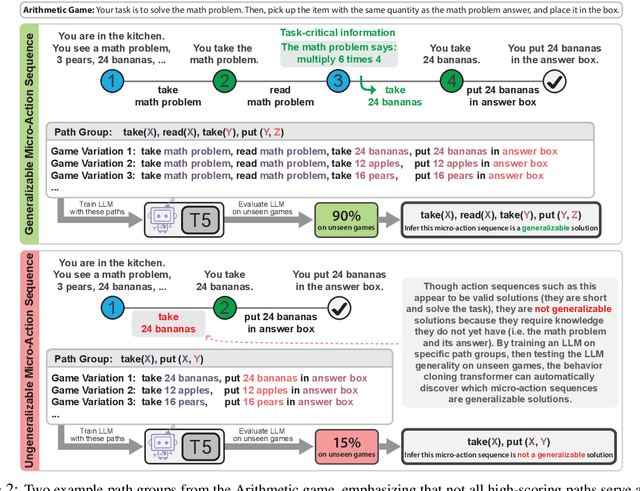

In this work, we introduce a self-supervised behavior cloning transformer for text games, which are challenging benchmarks for multi-step reasoning in virtual environments. Traditionally, Behavior Cloning Transformers excel in such tasks but rely on supervised training data. Our approach auto-generates training data by exploring trajectories (defined by common macro-action sequences) that lead to reward within the games, while determining the generality and utility of these trajectories by rapidly training small models then evaluating their performance on unseen development games. Through empirical analysis, we show our method consistently uncovers generalizable training data, achieving about 90\% performance of supervised systems across three benchmark text games.