 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConstrained Entropic Unlearning: A Primal-Dual Framework for Large Language Models
Jun 05, 2025Large Language Models (LLMs) deployed in real-world settings increasingly face the need to unlearn sensitive, outdated, or proprietary information. Existing unlearning methods typically formulate forgetting and retention as a regularized trade-off, combining both objectives into a single scalarized loss. This often leads to unstable optimization and degraded performance on retained data, especially under aggressive forgetting. We propose a new formulation of LLM unlearning as a constrained optimization problem: forgetting is enforced via a novel logit-margin flattening loss that explicitly drives the output distribution toward uniformity on a designated forget set, while retention is preserved through a hard constraint on a separate retain set. Compared to entropy-based objectives, our loss is softmax-free, numerically stable, and maintains non-vanishing gradients, enabling more efficient and robust optimization. We solve the constrained problem using a scalable primal-dual algorithm that exposes the trade-off between forgetting and retention through the dynamics of the dual variable. Evaluations on the TOFU and MUSE benchmarks across diverse LLM architectures demonstrate that our approach consistently matches or exceeds state-of-the-art baselines, effectively removing targeted information while preserving downstream utility.
Sequential QCQP for Bilevel Optimization with Line Search
May 20, 2025Bilevel optimization involves a hierarchical structure where one problem is nested within another, leading to complex interdependencies between levels. We propose a single-loop, tuning-free algorithm that guarantees anytime feasibility, i.e., approximate satisfaction of the lower-level optimality condition, while ensuring descent of the upper-level objective. At each iteration, a convex quadratically-constrained quadratic program (QCQP) with a closed-form solution yields the search direction, followed by a backtracking line search inspired by control barrier functions to ensure safe, uniformly positive step sizes. The resulting method is scalable, requires no hyperparameter tuning, and converges under mild local regularity assumptions. We establish an O(1/k) ergodic convergence rate and demonstrate the algorithm's effectiveness on representative bilevel tasks.
Safe Gradient Flow for Bilevel Optimization
Jan 27, 2025Bilevel optimization is a key framework in hierarchical decision-making, where one problem is embedded within the constraints of another. In this work, we propose a control-theoretic approach to solving bilevel optimization problems. Our method consists of two components: a gradient flow mechanism to minimize the upper-level objective and a safety filter to enforce the constraints imposed by the lower-level problem. Together, these components form a safe gradient flow that solves the bilevel problem in a single loop. To improve scalability with respect to the lower-level problem's dimensions, we introduce a relaxed formulation and design a compact variant of the safe gradient flow. This variant minimizes the upper-level objective while ensuring the lower-level solution remains within a user-defined distance. Using Lyapunov analysis, we establish convergence guarantees for the dynamics, proving that they converge to a neighborhood of the optimal solution. Numerical experiments further validate the effectiveness of the proposed approaches. Our contributions provide both theoretical insights and practical tools for efficiently solving bilevel optimization problems.
Domain Adaptive Safety Filters via Deep Operator Learning
Oct 18, 2024Learning-based approaches for constructing Control Barrier Functions (CBFs) are increasingly being explored for safety-critical control systems. However, these methods typically require complete retraining when applied to unseen environments, limiting their adaptability. To address this, we propose a self-supervised deep operator learning framework that learns the mapping from environmental parameters to the corresponding CBF, rather than learning the CBF directly. Our approach leverages the residual of a parametric Partial Differential Equation (PDE), where the solution defines a parametric CBF approximating the maximal control invariant set. This framework accommodates complex safety constraints, higher relative degrees, and actuation limits. We demonstrate the effectiveness of the method through numerical experiments on navigation tasks involving dynamic obstacles.
Compositional Curvature Bounds for Deep Neural Networks
Jun 07, 2024A key challenge that threatens the widespread use of neural networks in safety-critical applications is their vulnerability to adversarial attacks. In this paper, we study the second-order behavior of continuously differentiable deep neural networks, focusing on robustness against adversarial perturbations. First, we provide a theoretical analysis of robustness and attack certificates for deep classifiers by leveraging local gradients and upper bounds on the second derivative (curvature constant). Next, we introduce a novel algorithm to analytically compute provable upper bounds on the second derivative of neural networks. This algorithm leverages the compositional structure of the model to propagate the curvature bound layer-by-layer, giving rise to a scalable and modular approach. The proposed bound can serve as a differentiable regularizer to control the curvature of neural networks during training, thereby enhancing robustness. Finally, we demonstrate the efficacy of our method on classification tasks using the MNIST and CIFAR-10 datasets.
Provable Bounds on the Hessian of Neural Networks: Derivative-Preserving Reachability Analysis
Jun 06, 2024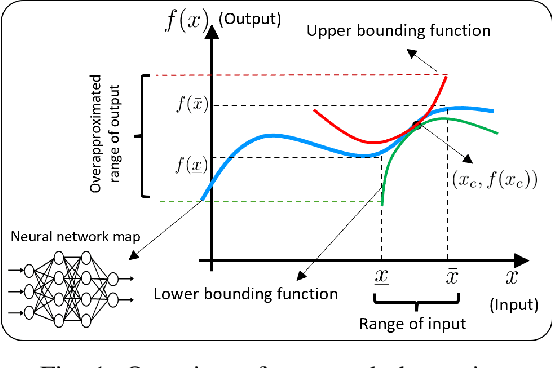
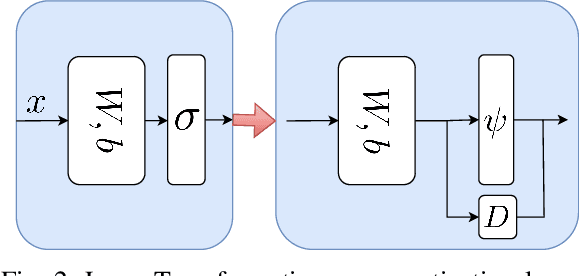

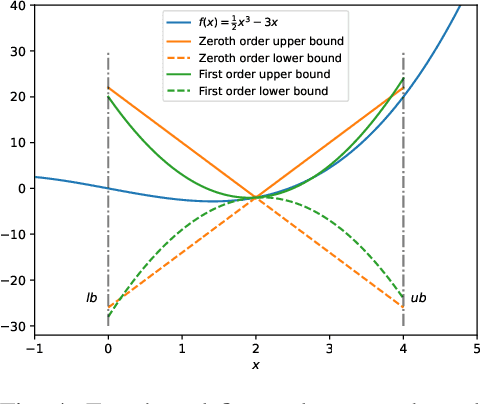
We propose a novel reachability analysis method tailored for neural networks with differentiable activations. Our idea hinges on a sound abstraction of the neural network map based on first-order Taylor expansion and bounding the remainder. To this end, we propose a method to compute analytical bounds on the network's first derivative (gradient) and second derivative (Hessian). A key aspect of our method is loop transformation on the activation functions to exploit their monotonicity effectively. The resulting end-to-end abstraction locally preserves the derivative information, yielding accurate bounds on small input sets. Finally, we employ a branch and bound framework for larger input sets to refine the abstraction recursively. We evaluate our method numerically via different examples and compare the results with relevant state-of-the-art methods.
Gradient-Regularized Out-of-Distribution Detection
Apr 18, 2024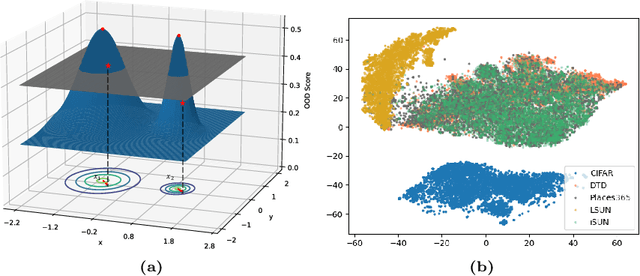
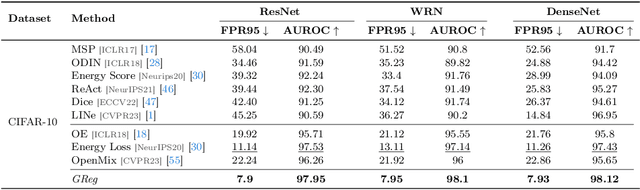
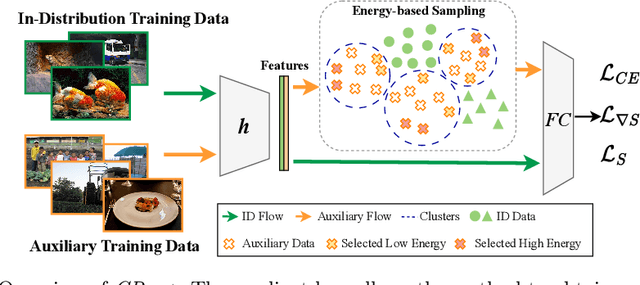
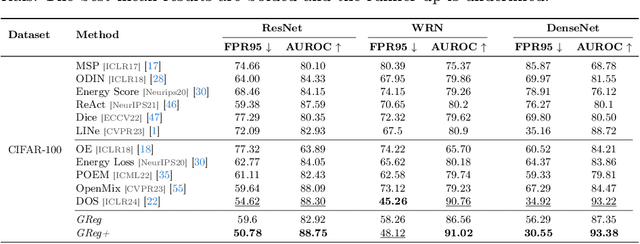
One of the challenges for neural networks in real-life applications is the overconfident errors these models make when the data is not from the original training distribution. Addressing this issue is known as Out-of-Distribution (OOD) detection. Many state-of-the-art OOD methods employ an auxiliary dataset as a surrogate for OOD data during training to achieve improved performance. However, these methods fail to fully exploit the local information embedded in the auxiliary dataset. In this work, we propose the idea of leveraging the information embedded in the gradient of the loss function during training to enable the network to not only learn a desired OOD score for each sample but also to exhibit similar behavior in a local neighborhood around each sample. We also develop a novel energy-based sampling method to allow the network to be exposed to more informative OOD samples during the training phase. This is especially important when the auxiliary dataset is large. We demonstrate the effectiveness of our method through extensive experiments on several OOD benchmarks, improving the existing state-of-the-art FPR95 by 4% on our ImageNet experiment. We further provide a theoretical analysis through the lens of certified robustness and Lipschitz analysis to showcase the theoretical foundation of our work. We will publicly release our code after the review process.
Actor-Critic Physics-informed Neural Lyapunov Control
Mar 13, 2024



Designing control policies for stabilization tasks with provable guarantees is a long-standing problem in nonlinear control. A crucial performance metric is the size of the resulting region of attraction, which essentially serves as a robustness "margin" of the closed-loop system against uncertainties. In this paper, we propose a new method to train a stabilizing neural network controller along with its corresponding Lyapunov certificate, aiming to maximize the resulting region of attraction while respecting the actuation constraints. Crucial to our approach is the use of Zubov's Partial Differential Equation (PDE), which precisely characterizes the true region of attraction of a given control policy. Our framework follows an actor-critic pattern where we alternate between improving the control policy (actor) and learning a Zubov function (critic). Finally, we compute the largest certifiable region of attraction by invoking an SMT solver after the training procedure. Our numerical experiments on several design problems show consistent and significant improvements in the size of the resulting region of attraction.
Verification-Aided Learning of Neural Network Barrier Functions with Termination Guarantees
Mar 12, 2024Barrier functions are a general framework for establishing a safety guarantee for a system. However, there is no general method for finding these functions. To address this shortcoming, recent approaches use self-supervised learning techniques to learn these functions using training data that are periodically generated by a verification procedure, leading to a verification-aided learning framework. Despite its immense potential in automating barrier function synthesis, the verification-aided learning framework does not have termination guarantees and may suffer from a low success rate of finding a valid barrier function in practice. In this paper, we propose a holistic approach to address these drawbacks. With a convex formulation of the barrier function synthesis, we propose to first learn an empirically well-behaved NN basis function and then apply a fine-tuning algorithm that exploits the convexity and counterexamples from the verification failure to find a valid barrier function with finite-step termination guarantees: if there exist valid barrier functions, the fine-tuning algorithm is guaranteed to find one in a finite number of iterations. We demonstrate that our fine-tuning method can significantly boost the performance of the verification-aided learning framework on examples of different scales and using various neural network verifiers.
Learning Performance-Oriented Control Barrier Functions Under Complex Safety Constraints and Limited Actuation
Jan 11, 2024Control Barrier Functions (CBFs) provide an elegant framework for designing safety filters for nonlinear control systems by constraining their trajectories to an invariant subset of a prespecified safe set. However, the task of finding a CBF that concurrently maximizes the volume of the resulting control invariant set while accommodating complex safety constraints, particularly in high relative degree systems with actuation constraints, continues to pose a substantial challenge. In this work, we propose a novel self-supervised learning framework that holistically addresses these hurdles. Given a Boolean composition of multiple state constraints that define the safe set, our approach starts with building a single continuously differentiable function whose 0-superlevel set provides an inner approximation of the safe set. We then use this function together with a smooth neural network to parameterize the CBF candidate. Finally, we design a training loss function based on a Hamilton-Jacobi partial differential equation to train the CBF while enlarging the volume of the induced control invariant set. We demonstrate the effectiveness of our approach via numerical experiments.