 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIn-Context Learning in Large Language Models: A Neuroscience-inspired Analysis of Representations
Oct 18, 2023



Large language models (LLMs) exhibit remarkable performance improvement through in-context learning (ICL) by leveraging task-specific examples in the input. However, the mechanisms behind this improvement remain elusive. In this work, we investigate embeddings and attention representations in Llama-2 70B and Vicuna 13B. Specifically, we study how embeddings and attention change after in-context-learning, and how these changes mediate improvement in behavior. We employ neuroscience-inspired techniques, such as representational similarity analysis (RSA), and propose novel methods for parameterized probing and attention ratio analysis (ARA, measuring the ratio of attention to relevant vs. irrelevant information). We designed three tasks with a priori relationships among their conditions: reading comprehension, linear regression, and adversarial prompt injection. We formed hypotheses about expected similarities in task representations to investigate latent changes in embeddings and attention. Our analyses revealed a meaningful correlation between changes in both embeddings and attention representations with improvements in behavioral performance after ICL. This empirical framework empowers a nuanced understanding of how latent representations affect LLM behavior with and without ICL, offering valuable tools and insights for future research and practical applications.
ALLURE: Auditing and Improving LLM-based Evaluation of Text using Iterative In-Context-Learning
Sep 27, 2023



From grading papers to summarizing medical documents, large language models (LLMs) are evermore used for evaluation of text generated by humans and AI alike. However, despite their extensive utility, LLMs exhibit distinct failure modes, necessitating a thorough audit and improvement of their text evaluation capabilities. Here we introduce ALLURE, a systematic approach to Auditing Large Language Models Understanding and Reasoning Errors. ALLURE involves comparing LLM-generated evaluations with annotated data, and iteratively incorporating instances of significant deviation into the evaluator, which leverages in-context learning (ICL) to enhance and improve robust evaluation of text by LLMs. Through this iterative process, we refine the performance of the evaluator LLM, ultimately reducing reliance on human annotators in the evaluation process. We anticipate ALLURE to serve diverse applications of LLMs in various domains related to evaluation of textual data, such as medical summarization, education, and and productivity.
Discovering Distribution Shifts using Latent Space Representations
Feb 17, 2022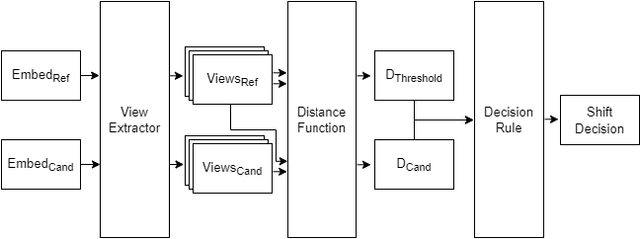

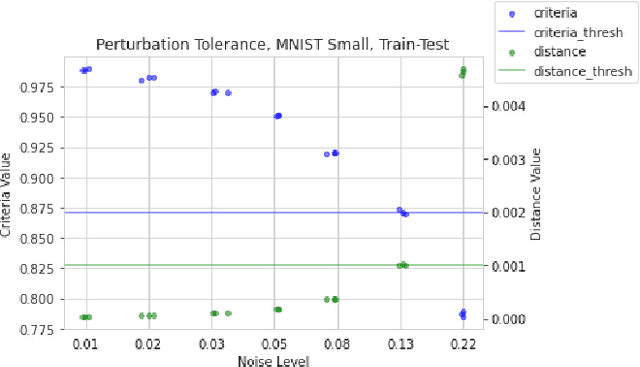
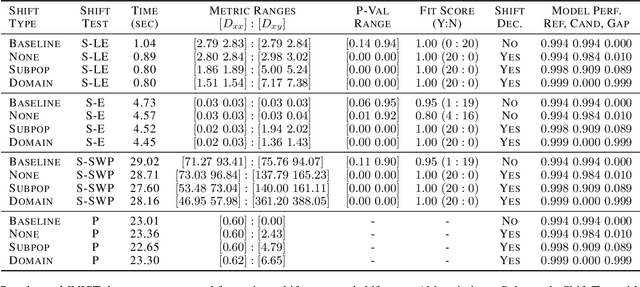
Rapid progress in representation learning has led to a proliferation of embedding models, and to associated challenges of model selection and practical application. It is non-trivial to assess a model's generalizability to new, candidate datasets and failure to generalize may lead to poor performance on downstream tasks. Distribution shifts are one cause of reduced generalizability, and are often difficult to detect in practice. In this paper, we use the embedding space geometry to propose a non-parametric framework for detecting distribution shifts, and specify two tests. The first test detects shifts by establishing a robustness boundary, determined by an intelligible performance criterion, for comparing reference and candidate datasets. The second test detects shifts by featurizing and classifying multiple subsamples of two datasets as in-distribution and out-of-distribution. In evaluation, both tests detect model-impacting distribution shifts, in various shift scenarios, for both synthetic and real-world datasets.