 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAligning benchmark datasets for table structure recognition
Mar 01, 2023Benchmark datasets for table structure recognition (TSR) must be carefully processed to ensure they are annotated consistently. However, even if a dataset's annotations are self-consistent, there may be significant inconsistency across datasets, which can harm the performance of models trained and evaluated on them. In this work, we show that aligning these benchmarks$\unicode{x2014}$removing both errors and inconsistency between them$\unicode{x2014}$improves model performance significantly. We demonstrate this through a data-centric approach where we adopt a single model architecture, the Table Transformer (TATR), that we hold fixed throughout. Baseline exact match accuracy for TATR evaluated on the ICDAR-2013 benchmark is 65% when trained on PubTables-1M, 42% when trained on FinTabNet, and 69% combined. After reducing annotation mistakes and inter-dataset inconsistency, performance of TATR evaluated on ICDAR-2013 increases substantially to 75% when trained on PubTables-1M, 65% when trained on FinTabNet, and 81% combined. We show through ablations over the modification steps that canonicalization of the table annotations has a significantly positive effect on performance, while other choices balance necessary trade-offs that arise when deciding a benchmark dataset's final composition. Overall we believe our work has significant implications for benchmark design for TSR and potentially other tasks as well. All dataset processing and training code will be released.
GriTS: Grid table similarity metric for table structure recognition
Mar 23, 2022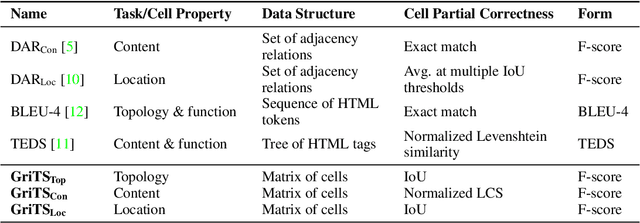
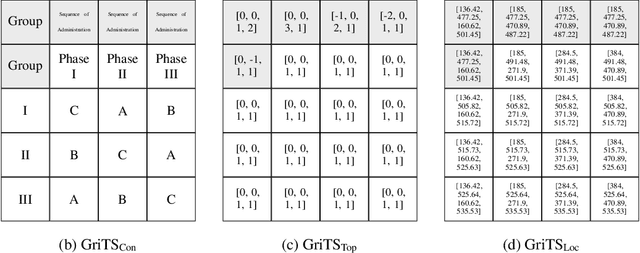
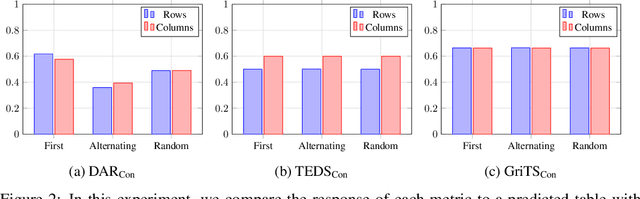
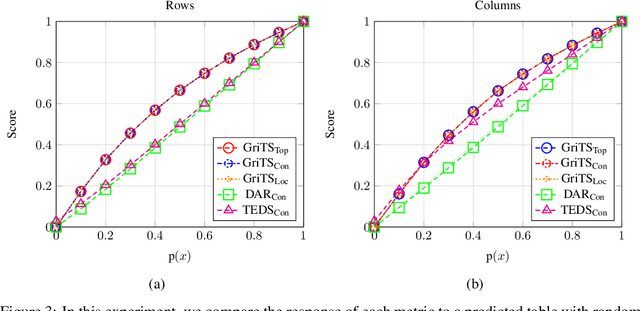
In this paper, we propose a new class of evaluation metric for table structure recognition, grid table similarity (GriTS). Unlike prior metrics, GriTS evaluates the correctness of a predicted table directly in its natural form as a matrix. To create a similarity measure between matrices, we generalize the two-dimensional largest common substructure (2D-LCS) problem, which is NP-hard, to the 2D most similar substructures (2D-MSS) problem and propose a polynomial-time heuristic for solving it. We validate empirically using the PubTables-1M dataset that comparison between matrices exhibits more desirable behavior than alternatives for table structure recognition evaluation. GriTS also unifies all three subtasks of cell topology recognition, cell location recognition, and cell content recognition within the same framework, which simplifies the evaluation and enables more meaningful comparisons across different types of structure recognition approaches. Code will be released at https://github.com/microsoft/table-transformer.
Discovering Distribution Shifts using Latent Space Representations
Feb 17, 2022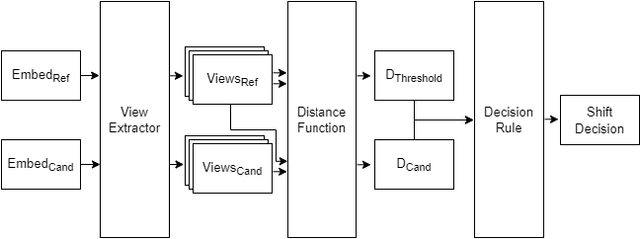

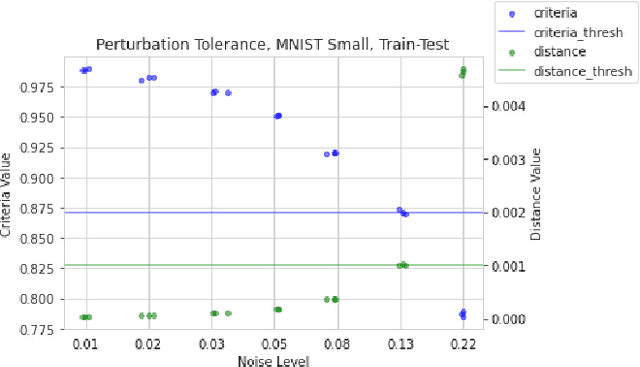
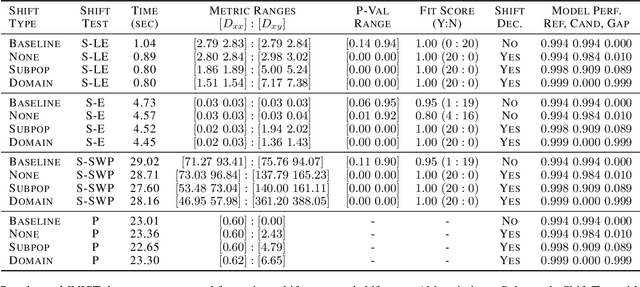
Rapid progress in representation learning has led to a proliferation of embedding models, and to associated challenges of model selection and practical application. It is non-trivial to assess a model's generalizability to new, candidate datasets and failure to generalize may lead to poor performance on downstream tasks. Distribution shifts are one cause of reduced generalizability, and are often difficult to detect in practice. In this paper, we use the embedding space geometry to propose a non-parametric framework for detecting distribution shifts, and specify two tests. The first test detects shifts by establishing a robustness boundary, determined by an intelligible performance criterion, for comparing reference and candidate datasets. The second test detects shifts by featurizing and classifying multiple subsamples of two datasets as in-distribution and out-of-distribution. In evaluation, both tests detect model-impacting distribution shifts, in various shift scenarios, for both synthetic and real-world datasets.
PubTables-1M: Towards a universal dataset and metrics for training and evaluating table extraction models
Oct 12, 2021


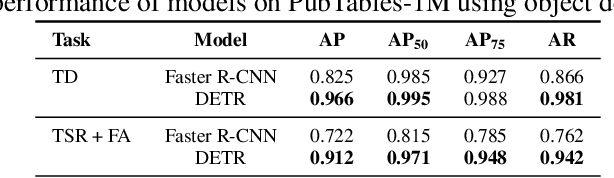
Recently, interest has grown in applying machine learning to the problem of table structure inference and extraction from unstructured documents. However, progress in this area has been challenging both to make and to measure, due to several issues that arise in training and evaluating models from labeled data. This includes challenges as fundamental as the lack of a single definitive ground truth output for each input sample and the lack of an ideal metric for measuring partial correctness for this task. To address these issues we propose a new dataset, PubMed Tables One Million (PubTables-1M), and a new class of metric, grid table similarity (GriTS). PubTables-1M is nearly twice as large as the previous largest comparable dataset, contains highly-detailed structure annotations, and can be used for models across multiple architectures and modalities. Further, it addresses issues such as ambiguity and lack of consistency in the annotations via a novel canonicalization and quality control procedure. We apply DETR to table extraction for the first time and show that object detection models trained on PubTables-1M produce excellent results out-of-the-box for all three tasks of detection, structure recognition, and functional analysis. It is our hope that PubTables-1M and GriTS can further progress in this area by creating data and metrics suitable for training and evaluating a wide variety of models for table extraction. Data and code will be released at https://github.com/microsoft/table-transformer.