 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePOTATR: A Lightweight Image-to-Graph Model for Page-Level Table Extraction
Jun 08, 2026Large-scale document processing requires contextually aware table extraction (TE) that is both accurate and efficient. Yet current approaches require billions of parameters, hundreds of autoregressive steps, or costly API inference. Motivated by this, we introduce the Page-Object Table Transformer (POTATR), a lightweight 29M parameter image-to-graph model that extends the Table Transformer (TATR) for contextualized page-level TE. POTATR outperforms all models tested on the PubTables-v2 Single Pages benchmark -- including frontier MLLMs -- achieving $\textrm{GriTS}_\textrm{Con}$ of 0.964 while running over 130$\times$ faster at roughly 300$\times$ lower cost. Further, POTATR's output is spatially grounded: every recognized element has a bounding box, enabling visual verification and geometric text assignment. As a result, POTATR performs unified page-level TE while composing with other models, enabling extension to scanned documents via external OCR and to full-document TE via techniques like cross-page merging. Code and models will be released.
On Finding Inconsistencies in Documents
Dec 21, 2025Professionals in academia, law, and finance audit their documents because inconsistencies can result in monetary, reputational, and scientific costs. Language models (LMs) have the potential to dramatically speed up this auditing process. To understand their abilities, we introduce a benchmark, FIND (Finding INconsistencies in Documents), where each example is a document with an inconsistency inserted manually by a domain expert. Despite the documents being long, technical, and complex, the best-performing model (gpt-5) recovered 64% of the inserted inconsistencies. Surprisingly, gpt-5 also found undiscovered inconsistencies present in the original documents. For example, on 50 arXiv papers, we judged 136 out of 196 of the model's suggestions to be legitimate inconsistencies missed by the original authors. However, despite these findings, even the best models miss almost half of the inconsistencies in FIND, demonstrating that inconsistency detection is still a challenging task.
PubTables-v2: A new large-scale dataset for full-page and multi-page table extraction
Dec 11, 2025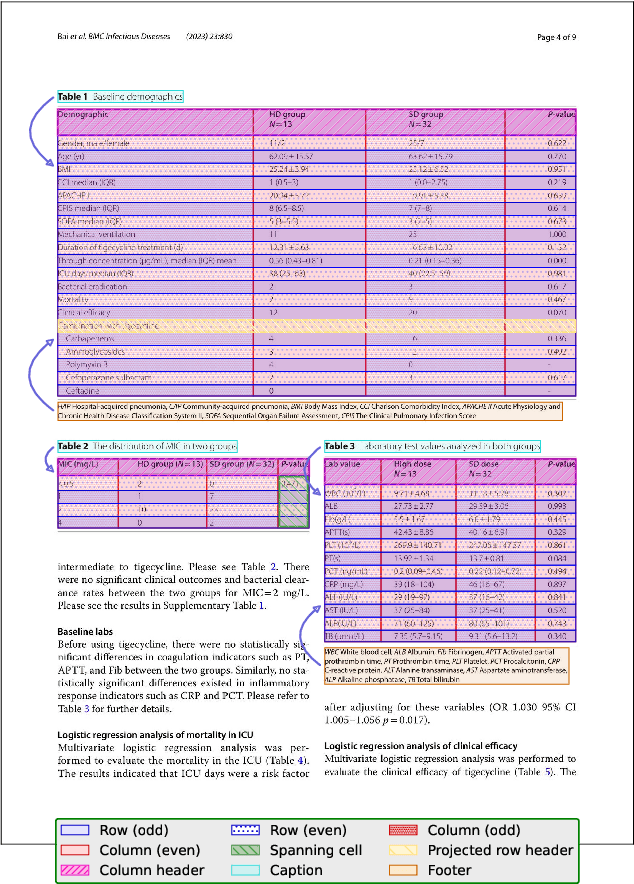
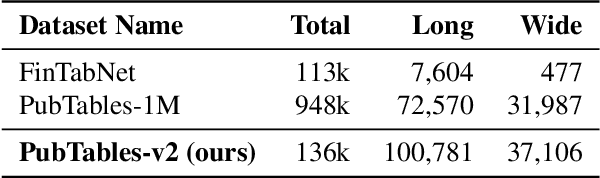


Table extraction (TE) is a key challenge in visual document understanding. Traditional approaches detect tables first, then recognize their structure. Recently, interest has surged in developing methods, such as vision-language models (VLMs), that can extract tables directly in their full page or document context. However, progress has been difficult to demonstrate due to a lack of annotated data. To address this, we create a new large-scale dataset, PubTables-v2. PubTables-v2 supports a number of current challenging table extraction tasks. Notably, it is the first large-scale benchmark for multi-page table structure recognition. We demonstrate its usefulness by evaluating domain-specialized VLMs on these tasks and highlighting current progress. Finally, we use PubTables-v2 to create the Page-Object Table Transformer (POTATR), an image-to-graph extension of the Table Transformer to comprehensive page-level TE. Data, code, and trained models will be released.
Aligning benchmark datasets for table structure recognition
Mar 01, 2023Benchmark datasets for table structure recognition (TSR) must be carefully processed to ensure they are annotated consistently. However, even if a dataset's annotations are self-consistent, there may be significant inconsistency across datasets, which can harm the performance of models trained and evaluated on them. In this work, we show that aligning these benchmarks$\unicode{x2014}$removing both errors and inconsistency between them$\unicode{x2014}$improves model performance significantly. We demonstrate this through a data-centric approach where we adopt a single model architecture, the Table Transformer (TATR), that we hold fixed throughout. Baseline exact match accuracy for TATR evaluated on the ICDAR-2013 benchmark is 65% when trained on PubTables-1M, 42% when trained on FinTabNet, and 69% combined. After reducing annotation mistakes and inter-dataset inconsistency, performance of TATR evaluated on ICDAR-2013 increases substantially to 75% when trained on PubTables-1M, 65% when trained on FinTabNet, and 81% combined. We show through ablations over the modification steps that canonicalization of the table annotations has a significantly positive effect on performance, while other choices balance necessary trade-offs that arise when deciding a benchmark dataset's final composition. Overall we believe our work has significant implications for benchmark design for TSR and potentially other tasks as well. All dataset processing and training code will be released.
GriTS: Grid table similarity metric for table structure recognition
Mar 23, 2022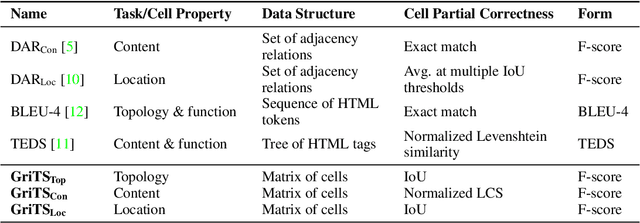
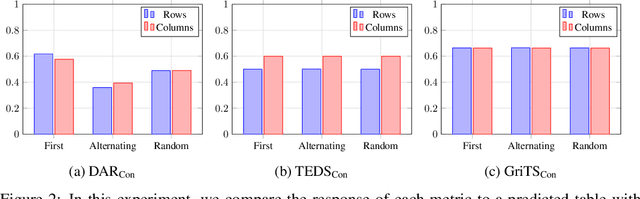
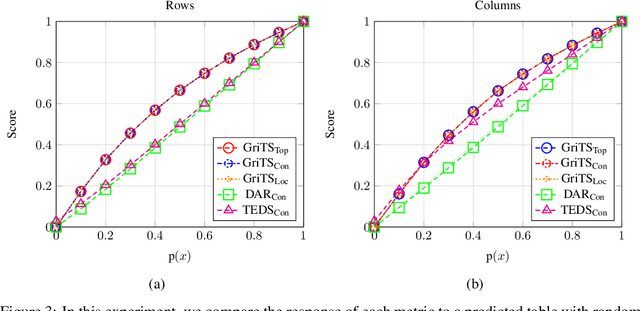
In this paper, we propose a new class of evaluation metric for table structure recognition, grid table similarity (GriTS). Unlike prior metrics, GriTS evaluates the correctness of a predicted table directly in its natural form as a matrix. To create a similarity measure between matrices, we generalize the two-dimensional largest common substructure (2D-LCS) problem, which is NP-hard, to the 2D most similar substructures (2D-MSS) problem and propose a polynomial-time heuristic for solving it. We validate empirically using the PubTables-1M dataset that comparison between matrices exhibits more desirable behavior than alternatives for table structure recognition evaluation. GriTS also unifies all three subtasks of cell topology recognition, cell location recognition, and cell content recognition within the same framework, which simplifies the evaluation and enables more meaningful comparisons across different types of structure recognition approaches. Code will be released at https://github.com/microsoft/table-transformer.
PubTables-1M: Towards a universal dataset and metrics for training and evaluating table extraction models
Oct 12, 2021


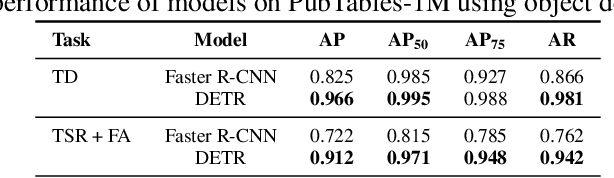
Recently, interest has grown in applying machine learning to the problem of table structure inference and extraction from unstructured documents. However, progress in this area has been challenging both to make and to measure, due to several issues that arise in training and evaluating models from labeled data. This includes challenges as fundamental as the lack of a single definitive ground truth output for each input sample and the lack of an ideal metric for measuring partial correctness for this task. To address these issues we propose a new dataset, PubMed Tables One Million (PubTables-1M), and a new class of metric, grid table similarity (GriTS). PubTables-1M is nearly twice as large as the previous largest comparable dataset, contains highly-detailed structure annotations, and can be used for models across multiple architectures and modalities. Further, it addresses issues such as ambiguity and lack of consistency in the annotations via a novel canonicalization and quality control procedure. We apply DETR to table extraction for the first time and show that object detection models trained on PubTables-1M produce excellent results out-of-the-box for all three tasks of detection, structure recognition, and functional analysis. It is our hope that PubTables-1M and GriTS can further progress in this area by creating data and metrics suitable for training and evaluating a wide variety of models for table extraction. Data and code will be released at https://github.com/microsoft/table-transformer.