 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Acoustic Patterns of Human Teachers Demonstrating Manipulation Tasks to Robots
Nov 01, 2022



Humans use audio signals in the form of spoken language or verbal reactions effectively when teaching new skills or tasks to other humans. While demonstrations allow humans to teach robots in a natural way, learning from trajectories alone does not leverage other available modalities including audio from human teachers. To effectively utilize audio cues accompanying human demonstrations, first it is important to understand what kind of information is present and conveyed by such cues. This work characterizes audio from human teachers demonstrating multi-step manipulation tasks to a situated Sawyer robot using three feature types: (1) duration of speech used, (2) expressiveness in speech or prosody, and (3) semantic content of speech. We analyze these features along four dimensions and find that teachers convey similar semantic concepts via spoken words for different conditions of (1) demonstration types, (2) audio usage instructions, (3) subtasks, and (4) errors during demonstrations. However, differentiating properties of speech in terms of duration and expressiveness are present along the four dimensions, highlighting that human audio carries rich information, potentially beneficial for technological advancement of robot learning from demonstration methods.
Understanding Teacher Gaze Patterns for Robot Learning
Jul 16, 2019
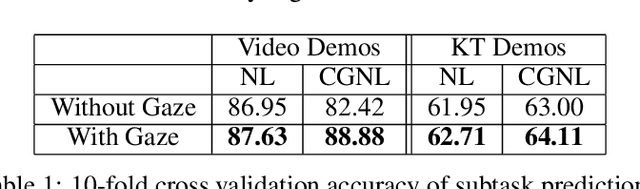

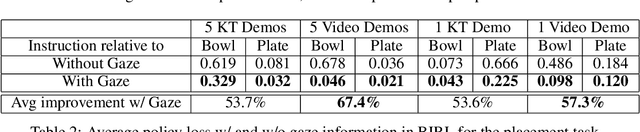
Human gaze is known to be a strong indicator of underlying human intentions and goals during manipulation tasks. This work studies gaze patterns of human teachers demonstrating tasks to robots and proposes ways in which such patterns can be used to enhance robot learning. Using both kinesthetic teaching and video demonstrations, we identify novel intention-revealing gaze behaviors during teaching. These prove to be informative in a variety of problems ranging from reference frame inference to segmentation of multi-step tasks. Based on our findings, we propose two proof-of-concept algorithms which show that gaze data can enhance subtask classification for a multi-step task up to 6% and reward inference and policy learning for a single-step task up to 67%. Our findings provide a foundation for a model of natural human gaze in robot learning from demonstration settings and present open problems for utilizing human gaze to enhance robot learning.