 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Effect of Robot Errors on Human Teaching Dynamics
Sep 15, 2024Human-in-the-loop learning is gaining popularity, particularly in the field of robotics, because it leverages human knowledge about real-world tasks to facilitate agent learning. When people instruct robots, they naturally adapt their teaching behavior in response to changes in robot performance. While current research predominantly focuses on integrating human teaching dynamics from an algorithmic perspective, understanding these dynamics from a human-centered standpoint is an under-explored, yet fundamental problem. Addressing this issue will enhance both robot learning and user experience. Therefore, this paper explores one potential factor contributing to the dynamic nature of human teaching: robot errors. We conducted a user study to investigate how the presence and severity of robot errors affect three dimensions of human teaching dynamics: feedback granularity, feedback richness, and teaching time, in both forced-choice and open-ended teaching contexts. The results show that people tend to spend more time teaching robots with errors, provide more detailed feedback over specific segments of a robot's trajectory, and that robot error can influence a teacher's choice of feedback modality. Our findings offer valuable insights for designing effective interfaces for interactive learning and optimizing algorithms to better understand human intentions.
Control-Theoretic Analysis of Shared Control Systems
Aug 22, 2024
Users of shared control systems change their behavior in the presence of assistance, which conflicts with assumpts about user behavior that some assistance methods make. In this paper, we propose an analysis technique to evaluate the user's experience with the assistive systems that bypasses required assumptions: we model the assistance as a dynamical system that can be analyzed using control theory techniques. We analyze the shared autonomy assistance algorithm and make several observations: we identify a problem with runaway goal confidence and propose a system adjustment to mitigate it, we demonstrate that the system inherently limits the possible actions available to the user, and we show that in a simplified setting, the effect of the assistance is to drive the system to the convex hull of the goals and, once there, add a layer of indirection between the user control and the system behavior. We conclude by discussing the possible uses of this analysis for the field.
Towards Interpretable Foundation Models of Robot Behavior: A Task Specific Policy Generation Approach
Jul 10, 2024Foundation models are a promising path toward general-purpose and user-friendly robots. The prevalent approach involves training a generalist policy that, like a reinforcement learning policy, uses observations to output actions. Although this approach has seen much success, several concerns arise when considering deployment and end-user interaction with these systems. In particular, the lack of modularity between tasks means that when model weights are updated (e.g., when a user provides feedback), the behavior in other, unrelated tasks may be affected. This can negatively impact the system's interpretability and usability. We present an alternative approach to the design of robot foundation models, Diffusion for Policy Parameters (DPP), which generates stand-alone, task-specific policies. Since these policies are detached from the foundation model, they are updated only when a user wants, either through feedback or personalization, allowing them to gain a high degree of familiarity with that policy. We demonstrate a proof-of-concept of DPP in simulation then discuss its limitations and the future of interpretable foundation models.
How Much Progress Did I Make? An Unexplored Human Feedback Signal for Teaching Robots
Jul 08, 2024

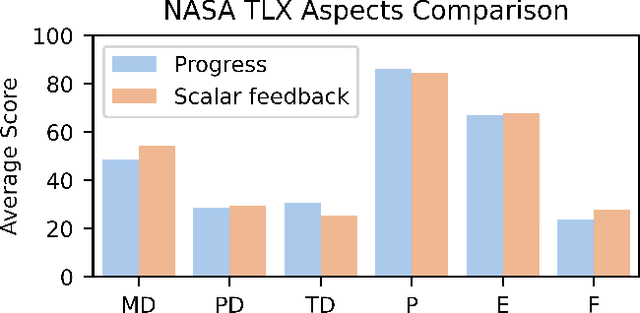
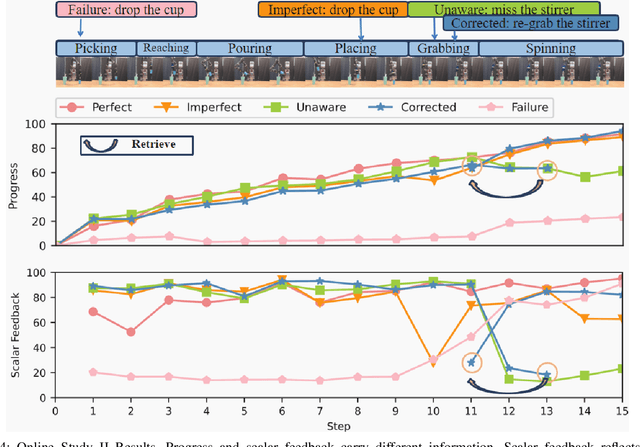
Enhancing the expressiveness of human teaching is vital for both improving robots' learning from humans and the human-teaching-robot experience. In this work, we characterize and test a little-used teaching signal: \textit{progress}, designed to represent the completion percentage of a task. We conducted two online studies with 76 crowd-sourced participants and one public space study with 40 non-expert participants to validate the capability of this progress signal. We find that progress indicates whether the task is successfully performed, reflects the degree of task completion, identifies unproductive but harmless behaviors, and is likely to be more consistent across participants. Furthermore, our results show that giving progress does not require extra workload and time. An additional contribution of our work is a dataset of 40 non-expert demonstrations from the public space study through an ice cream topping-adding task, which we observe to be multi-policy and sub-optimal, with sub-optimality not only from teleoperation errors but also from exploratory actions and attempts. The dataset is available at \url{https://github.com/TeachingwithProgress/Non-Expert\_Demonstrations}.
Imagining In-distribution States: How Predictable Robot Behavior Can Enable User Control Over Learned Policies
Jun 19, 2024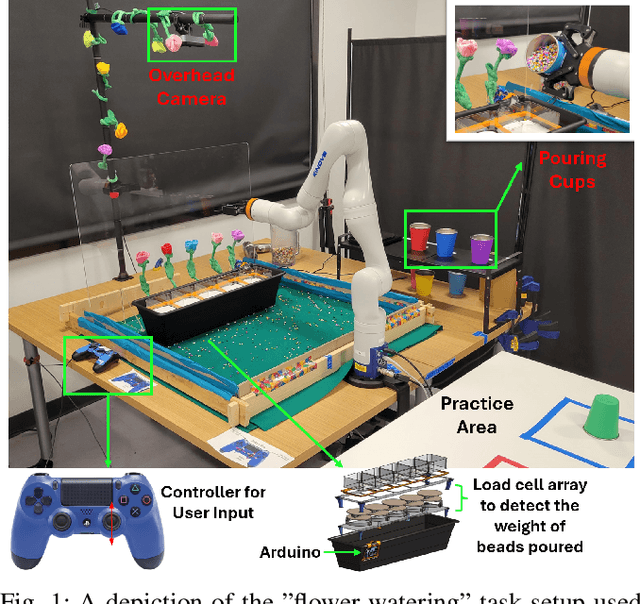
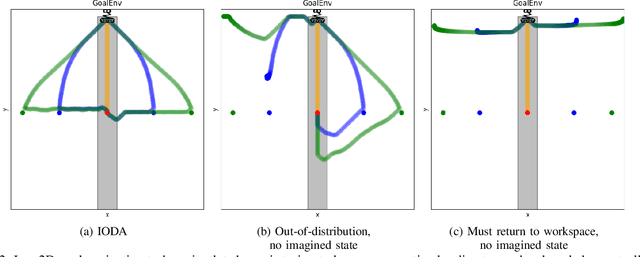
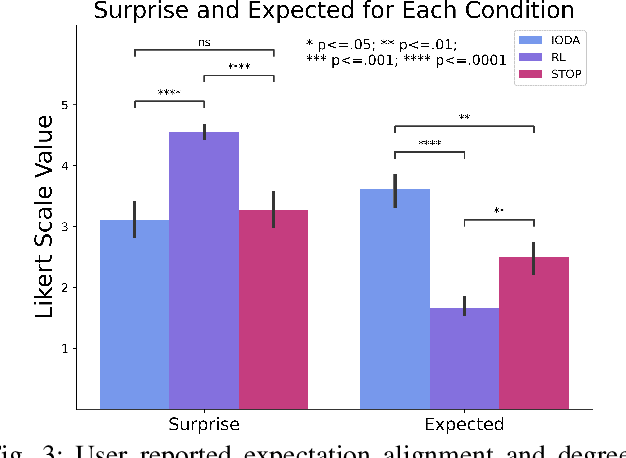
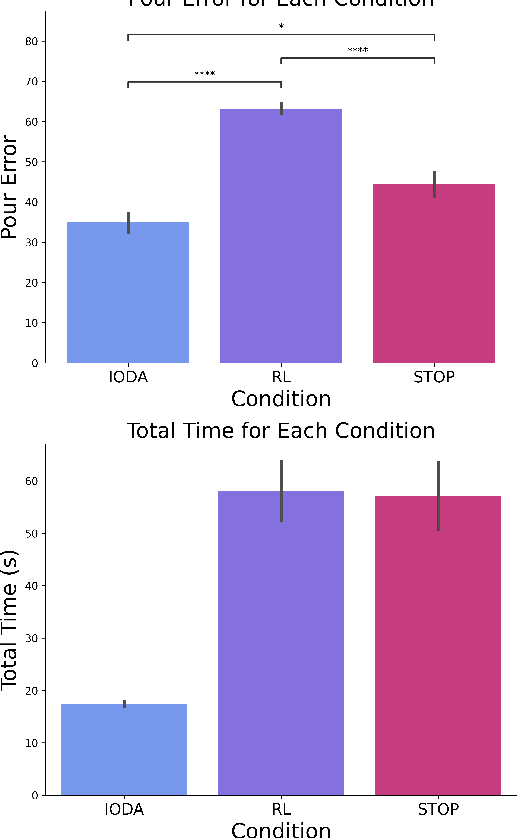
It is crucial that users are empowered to take advantage of the functionality of a robot and use their understanding of that functionality to perform novel and creative tasks. Given a robot trained with Reinforcement Learning (RL), a user may wish to leverage that autonomy along with their familiarity of how they expect the robot to behave to collaborate with the robot. One technique is for the user to take control of some of the robot's action space through teleoperation, allowing the RL policy to simultaneously control the rest. We formalize this type of shared control as Partitioned Control (PC). However, this may not be possible using an out-of-the-box RL policy. For example, a user's control may bring the robot into a failure state from the policy's perspective, causing it to act unexpectedly and hindering the success of the user's desired task. In this work, we formalize this problem and present Imaginary Out-of-Distribution Actions, IODA, an initial algorithm which empowers users to leverage their expectations of a robot's behavior to accomplish new tasks. We deploy IODA in a user study with a real robot and find that IODA leads to both better task performance and a higher degree of alignment between robot behavior and user expectation. We also show that in PC, there is a strong and significant correlation between task performance and the robot's ability to meet user expectations, highlighting the need for approaches like IODA. Code is available at https://github.com/AABL-Lab/ioda_roman_2024
From "Thumbs Up" to "10 out of 10": Reconsidering Scalar Feedback in Interactive Reinforcement Learning
Nov 17, 2023



Learning from human feedback is an effective way to improve robotic learning in exploration-heavy tasks. Compared to the wide application of binary human feedback, scalar human feedback has been used less because it is believed to be noisy and unstable. In this paper, we compare scalar and binary feedback, and demonstrate that scalar feedback benefits learning when properly handled. We collected binary or scalar feedback respectively from two groups of crowdworkers on a robot task. We found that when considering how consistently a participant labeled the same data, scalar feedback led to less consistency than binary feedback; however, the difference vanishes if small mismatches are allowed. Additionally, scalar and binary feedback show no significant differences in their correlations with key Reinforcement Learning targets. We then introduce Stabilizing TEacher Assessment DYnamics (STEADY) to improve learning from scalar feedback. Based on the idea that scalar feedback is muti-distributional, STEADY re-constructs underlying positive and negative feedback distributions and re-scales scalar feedback based on feedback statistics. We show that models trained with \textit{scalar feedback + STEADY } outperform baselines, including binary feedback and raw scalar feedback, in a robot reaching task with non-expert human feedback. Our results show that both binary feedback and scalar feedback are dynamic, and scalar feedback is a promising signal for use in interactive Reinforcement Learning.
SPRITE: Stewart Platform Robot for Interactive Tabletop Engagement
Nov 11, 2020

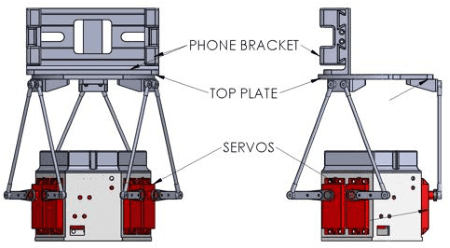

We present the design of the Stewart Platform Robot for Interactive Tabletop Engagement (SPRITE). This robot is designed for use in socially assistive robotics, a field focusing on non-contact social interaction to help people achieve goals relating to health, wellness, and education. We describe a series of design goals for a tabletop, socially assistive robot, including expressive movement, affective communication, a friendly, nonthreatening, and customizable appearance, and a safe, robust, and easily-repaired mechanical design.
Efficiently Guiding Imitation Learning Algorithms with Human Gaze
Mar 05, 2020
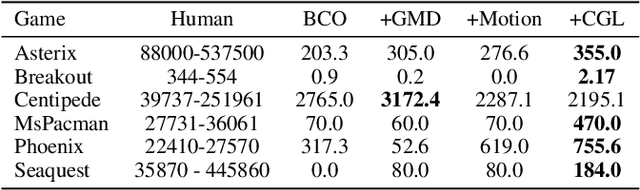
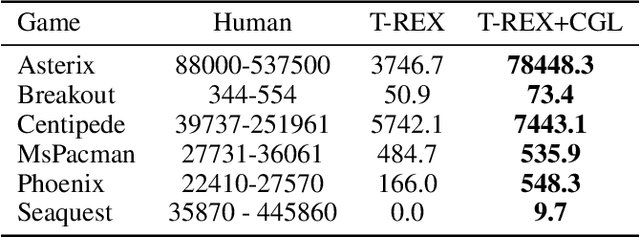
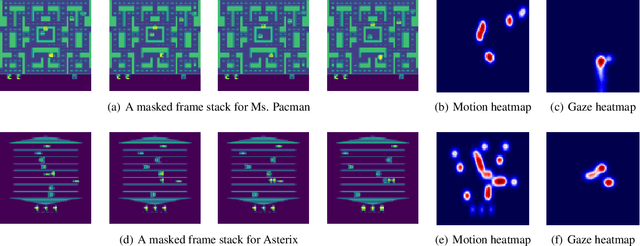
Human gaze is known to be an intention-revealing signal in human demonstrations of tasks. In this work, we use gaze cues from human demonstrators to enhance the performance of state-of-the-art inverse reinforcement learning (IRL) and behavioral cloning (BC) algorithms. We propose a novel approach for utilizing gaze data in a computationally efficient manner --- encoding the human's attention as part of an auxiliary loss function, without adding any additional learnable parameters to those models and without requiring gaze data at test time. The auxiliary loss encourages a network to have convolutional activations in regions where the human's gaze fixated. We show how to augment any existing convolutional architecture with our auxiliary gaze loss (coverage-based gaze loss or CGL) that can guide learning toward a better reward function or policy. We show that our proposed approach improves performance of both BC and IRL methods on a variety of Atari games. We also compare against two baseline methods for utilizing gaze data with imitation learning methods. Our approach outperforms a baseline method, called gaze-modulated dropout (GMD), and is comparable to another method (AGIL) which uses gaze as input to the network and thus increases the amount of learnable parameters.
TuneNet: One-Shot Residual Tuning for System Identification and Sim-to-Real Robot Task Transfer
Jul 25, 2019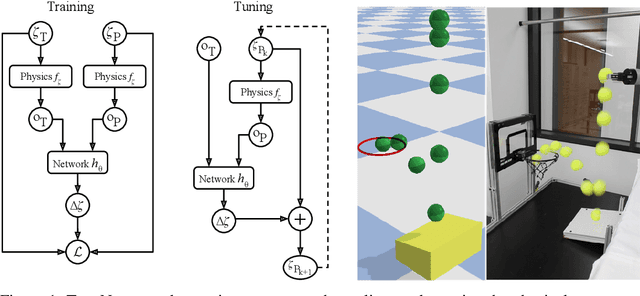

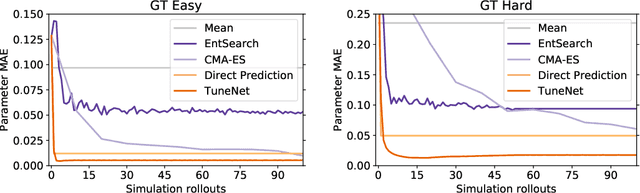
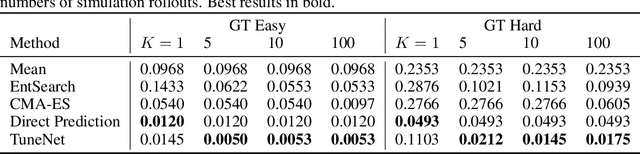
As researchers teach robots to perform more and more complex tasks, the need for realistic simulation environments is growing. Existing techniques for closing the reality gap by approximating real-world physics often require extensive real world data and/or thousands of simulation samples. This paper presents TuneNet, a new machine learning-based method to directly tune the parameters of one model to match another using an $\textit{iterative residual tuning}$ technique. TuneNet estimates the parameter difference between two models using a single observation from the target and minimal simulation, allowing rapid, accurate and sample-efficient parameter estimation. The system can be trained via supervised learning over an auto-generated simulated dataset. We show that TuneNet can perform system identification, even when the true parameter values lie well outside the distribution seen during training, and demonstrate that simulators tuned with TuneNet outperform existing techniques for predicting rigid body motion. Finally, we show that our method can estimate real-world parameter values, allowing a robot to perform sim-to-real task transfer on a dynamic manipulation task unseen during training. We are also making a baseline implementation of our code available online.
Understanding Teacher Gaze Patterns for Robot Learning
Jul 16, 2019
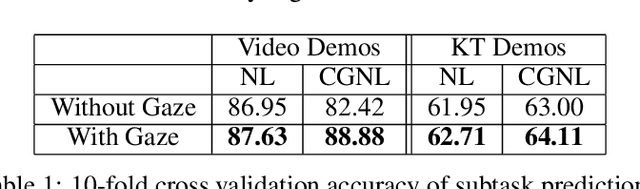

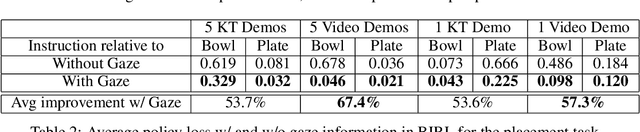
Human gaze is known to be a strong indicator of underlying human intentions and goals during manipulation tasks. This work studies gaze patterns of human teachers demonstrating tasks to robots and proposes ways in which such patterns can be used to enhance robot learning. Using both kinesthetic teaching and video demonstrations, we identify novel intention-revealing gaze behaviors during teaching. These prove to be informative in a variety of problems ranging from reference frame inference to segmentation of multi-step tasks. Based on our findings, we propose two proof-of-concept algorithms which show that gaze data can enhance subtask classification for a multi-step task up to 6% and reward inference and policy learning for a single-step task up to 67%. Our findings provide a foundation for a model of natural human gaze in robot learning from demonstration settings and present open problems for utilizing human gaze to enhance robot learning.