 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Users Understand Robot Foundation Model Performance through Task Success Rates and Beyond
Feb 03, 2026Robot Foundation Models (RFMs) represent a promising approach to developing general-purpose home robots. Given the broad capabilities of RFMs, users will inevitably ask an RFM-based robot to perform tasks that the RFM was not trained or evaluated on. In these cases, it is crucial that users understand the risks associated with attempting novel tasks due to the relatively high cost of failure. Furthermore, an informed user who understands an RFM's capabilities will know what situations and tasks the robot can handle. In this paper, we study how non-roboticists interpret performance information from RFM evaluations. These evaluations typically report task success rate (TSR) as the primary performance metric. While TSR is intuitive to experts, it is necessary to validate whether novices also use this information as intended. Toward this end, we conducted a study in which users saw real evaluation data, including TSR, failure case descriptions, and videos from multiple published RFM research projects. The results highlight that non-experts not only use TSR in a manner consistent with expert expectations but also highly value other information types, such as failure cases that are not often reported in RFM evaluations. Furthermore, we find that users want access to both real data from previous evaluations of the RFM and estimates from the robot about how well it will do on a novel task.
Towards Interpretable Foundation Models of Robot Behavior: A Task Specific Policy Generation Approach
Jul 10, 2024Foundation models are a promising path toward general-purpose and user-friendly robots. The prevalent approach involves training a generalist policy that, like a reinforcement learning policy, uses observations to output actions. Although this approach has seen much success, several concerns arise when considering deployment and end-user interaction with these systems. In particular, the lack of modularity between tasks means that when model weights are updated (e.g., when a user provides feedback), the behavior in other, unrelated tasks may be affected. This can negatively impact the system's interpretability and usability. We present an alternative approach to the design of robot foundation models, Diffusion for Policy Parameters (DPP), which generates stand-alone, task-specific policies. Since these policies are detached from the foundation model, they are updated only when a user wants, either through feedback or personalization, allowing them to gain a high degree of familiarity with that policy. We demonstrate a proof-of-concept of DPP in simulation then discuss its limitations and the future of interpretable foundation models.
Modifying RL Policies with Imagined Actions: How Predictable Policies Can Enable Users to Perform Novel Tasks
Dec 10, 2023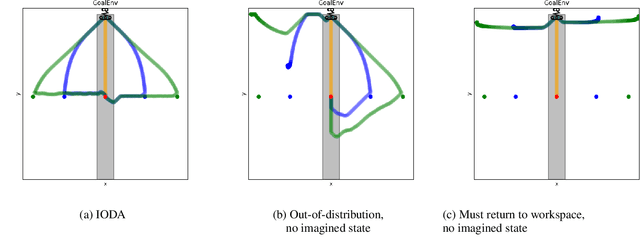
It is crucial that users are empowered to use the functionalities of a robot to creatively solve problems on the fly. A user who has access to a Reinforcement Learning (RL) based robot may want to use the robot's autonomy and their knowledge of its behavior to complete new tasks. One way is for the user to take control of some of the robot's action space through teleoperation while the RL policy simultaneously controls the rest. However, an out-of-the-box RL policy may not readily facilitate this. For example, a user's control may bring the robot into a failure state from the policy's perspective, causing it to act in a way the user is not familiar with, hindering the success of the user's desired task. In this work, we formalize this problem and present Imaginary Out-of-Distribution Actions, IODA, an initial algorithm for addressing that problem and empowering user's to leverage their expectation of a robot's behavior to accomplish new tasks.