 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficiently Guiding Imitation Learning Algorithms with Human Gaze
Paper and Code

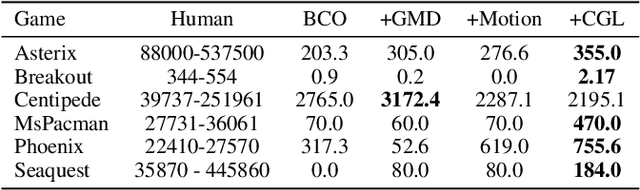
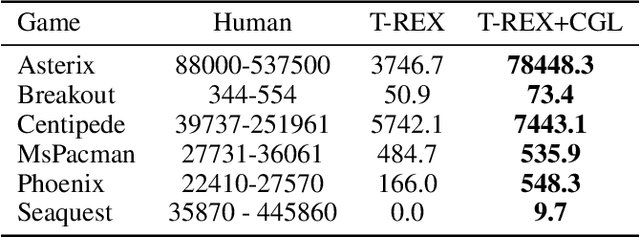
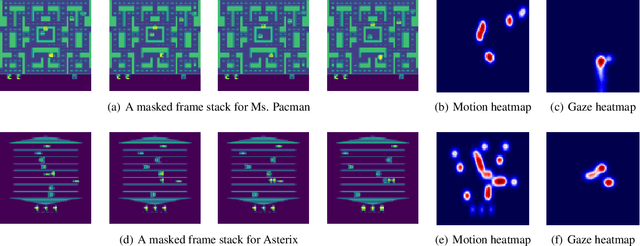
Human gaze is known to be an intention-revealing signal in human demonstrations of tasks. In this work, we use gaze cues from human demonstrators to enhance the performance of state-of-the-art inverse reinforcement learning (IRL) and behavioral cloning (BC) algorithms. We propose a novel approach for utilizing gaze data in a computationally efficient manner --- encoding the human's attention as part of an auxiliary loss function, without adding any additional learnable parameters to those models and without requiring gaze data at test time. The auxiliary loss encourages a network to have convolutional activations in regions where the human's gaze fixated. We show how to augment any existing convolutional architecture with our auxiliary gaze loss (coverage-based gaze loss or CGL) that can guide learning toward a better reward function or policy. We show that our proposed approach improves performance of both BC and IRL methods on a variety of Atari games. We also compare against two baseline methods for utilizing gaze data with imitation learning methods. Our approach outperforms a baseline method, called gaze-modulated dropout (GMD), and is comparable to another method (AGIL) which uses gaze as input to the network and thus increases the amount of learnable parameters.