 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImagining In-distribution States: How Predictable Robot Behavior Can Enable User Control Over Learned Policies
Paper and Code
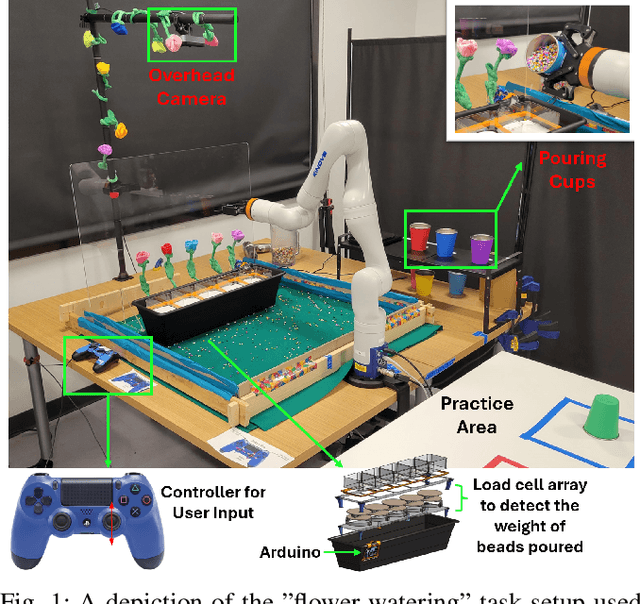
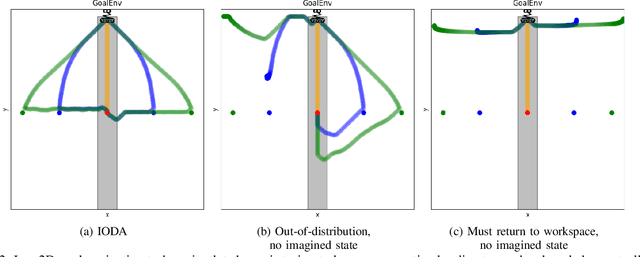
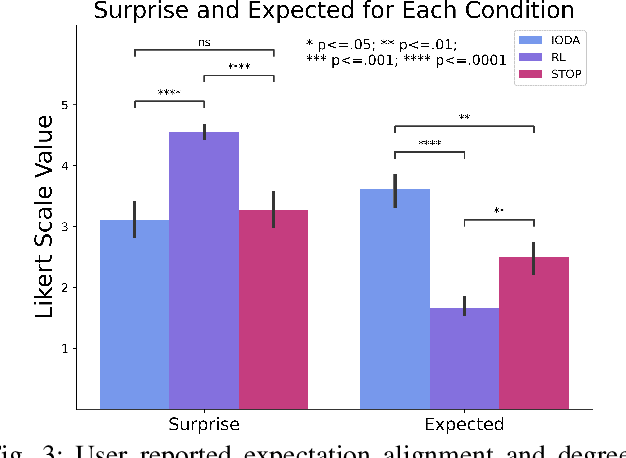
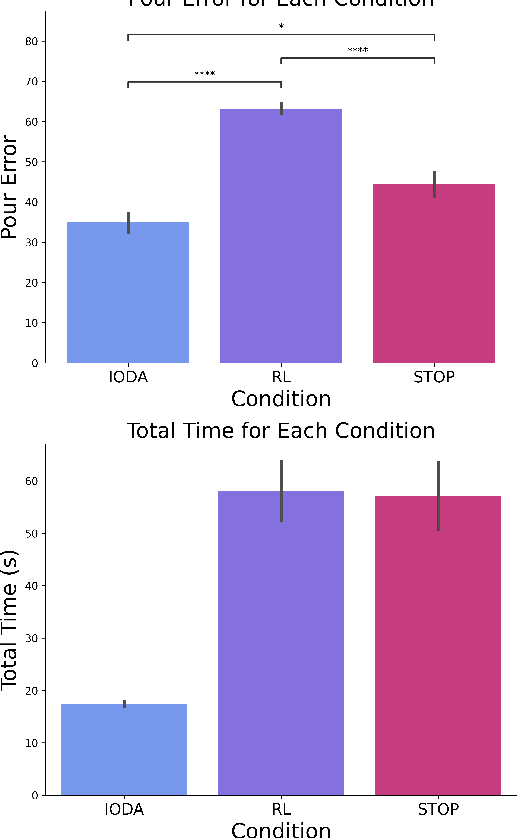
It is crucial that users are empowered to take advantage of the functionality of a robot and use their understanding of that functionality to perform novel and creative tasks. Given a robot trained with Reinforcement Learning (RL), a user may wish to leverage that autonomy along with their familiarity of how they expect the robot to behave to collaborate with the robot. One technique is for the user to take control of some of the robot's action space through teleoperation, allowing the RL policy to simultaneously control the rest. We formalize this type of shared control as Partitioned Control (PC). However, this may not be possible using an out-of-the-box RL policy. For example, a user's control may bring the robot into a failure state from the policy's perspective, causing it to act unexpectedly and hindering the success of the user's desired task. In this work, we formalize this problem and present Imaginary Out-of-Distribution Actions, IODA, an initial algorithm which empowers users to leverage their expectations of a robot's behavior to accomplish new tasks. We deploy IODA in a user study with a real robot and find that IODA leads to both better task performance and a higher degree of alignment between robot behavior and user expectation. We also show that in PC, there is a strong and significant correlation between task performance and the robot's ability to meet user expectations, highlighting the need for approaches like IODA. Code is available at https://github.com/AABL-Lab/ioda_roman_2024