 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnow Your Boundaries: The Necessity of Explicit Behavioral Cloning in Offline RL
Jun 01, 2022
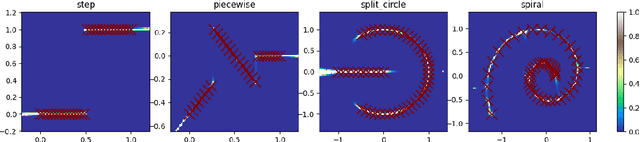
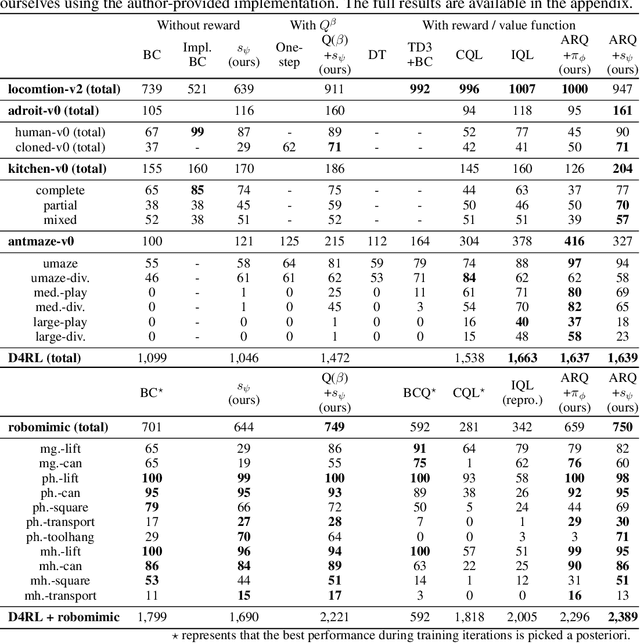

We introduce an offline reinforcement learning (RL) algorithm that explicitly clones a behavior policy to constrain value learning. In offline RL, it is often important to prevent a policy from selecting unobserved actions, since the consequence of these actions cannot be presumed without additional information about the environment. One straightforward way to implement such a constraint is to explicitly model a given data distribution via behavior cloning and directly force a policy not to select uncertain actions. However, many offline RL methods instantiate the constraint indirectly -- for example, pessimistic value estimation -- due to a concern about errors when modeling a potentially complex behavior policy. In this work, we argue that it is not only viable but beneficial to explicitly model the behavior policy for offline RL because the constraint can be realized in a stable way with the trained model. We first suggest a theoretical framework that allows us to incorporate behavior-cloned models into value-based offline RL methods, enjoying the strength of both explicit behavior cloning and value learning. Then, we propose a practical method utilizing a score-based generative model for behavior cloning. With the proposed method, we show state-of-the-art performance on several datasets within the D4RL and Robomimic benchmarks and achieve competitive performance across all datasets tested.
A Ranking Game for Imitation Learning
Feb 07, 2022
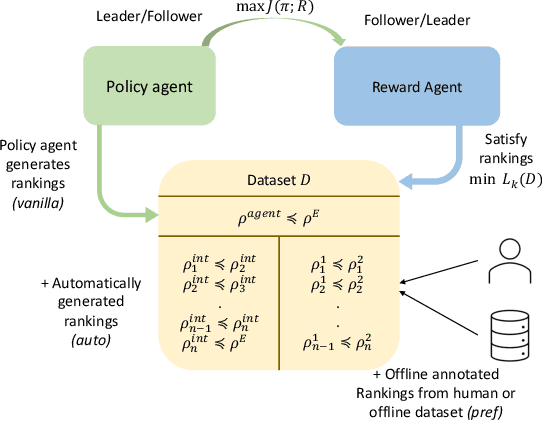
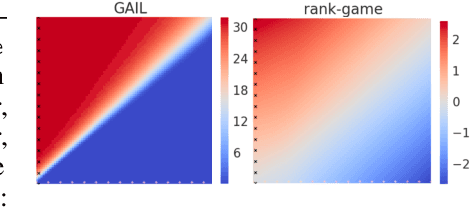
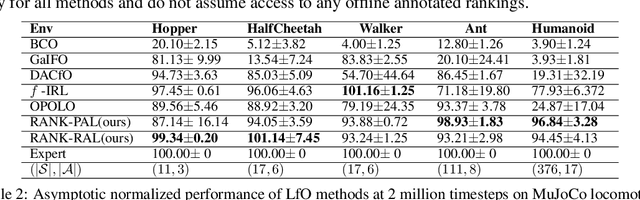
We propose a new framework for imitation learning - treating imitation as a two-player ranking-based Stackelberg game between a $\textit{policy}$ and a $\textit{reward}$ function. In this game, the reward agent learns to satisfy pairwise performance rankings within a set of policies, while the policy agent learns to maximize this reward. This game encompasses a large subset of both inverse reinforcement learning (IRL) methods and methods which learn from offline preferences. The Stackelberg game formulation allows us to use optimization methods that take the game structure into account, leading to more sample efficient and stable learning dynamics compared to existing IRL methods. We theoretically analyze the requirements of the loss function used for ranking policy performances to facilitate near-optimal imitation learning at equilibrium. We use insights from this analysis to further increase sample efficiency of the ranking game by using automatically generated rankings or with offline annotated rankings. Our experiments show that the proposed method achieves state-of-the-art sample efficiency and is able to solve previously unsolvable tasks in the Learning from Observation (LfO) setting.
You Only Evaluate Once: a Simple Baseline Algorithm for Offline RL
Oct 05, 2021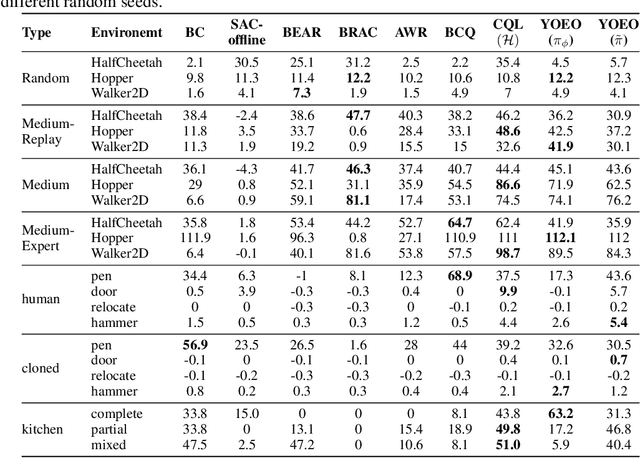

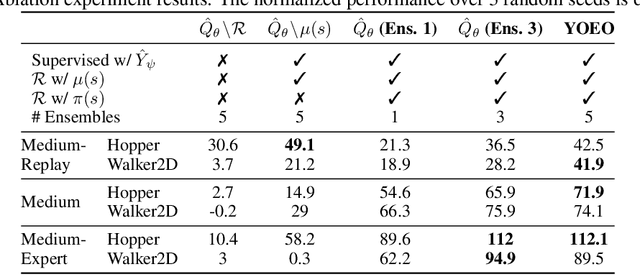
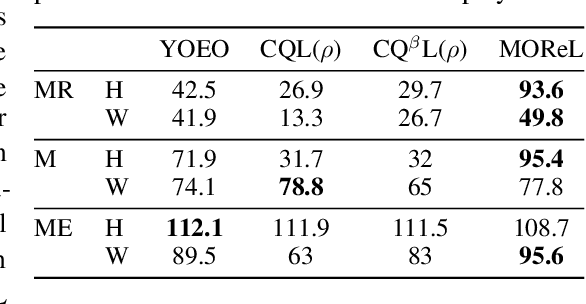
The goal of offline reinforcement learning (RL) is to find an optimal policy given prerecorded trajectories. Many current approaches customize existing off-policy RL algorithms, especially actor-critic algorithms in which policy evaluation and improvement are iterated. However, the convergence of such approaches is not guaranteed due to the use of complex non-linear function approximation and an intertwined optimization process. By contrast, we propose a simple baseline algorithm for offline RL that only performs the policy evaluation step once so that the algorithm does not require complex stabilization schemes. Since the proposed algorithm is not likely to converge to an optimal policy, it is an appropriate baseline for actor-critic algorithms that ought to be outperformed if there is indeed value in iterative optimization in the offline setting. Surprisingly, we empirically find that the proposed algorithm exhibits competitive and sometimes even state-of-the-art performance in a subset of the D4RL offline RL benchmark. This result suggests that future work is needed to fully exploit the potential advantages of iterative optimization in order to justify the reduced stability of such methods.
Self-Supervised Online Reward Shaping in Sparse-Reward Environments
Mar 08, 2021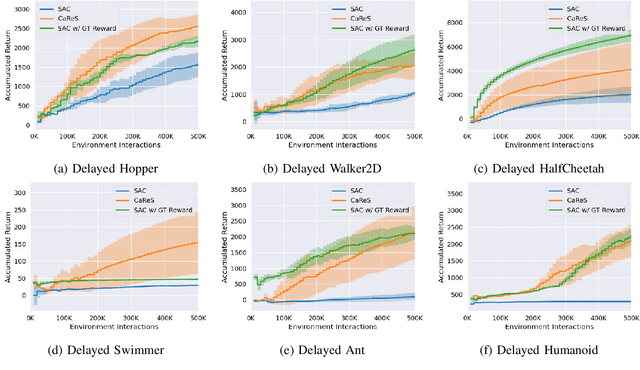
We propose a novel reinforcement learning framework that performs self-supervised online reward shaping, yielding faster, sample efficient performance in sparse reward environments. The proposed framework alternates between updating a policy and inferring a reward function. While the policy update is done with the inferred, potentially dense reward function, the original sparse reward is used to provide a self-supervisory signal for the reward update by serving as an ordering over the observed trajectories. The proposed framework is based on the theory that altering the reward function does not affect the optimal policy of the original MDP as long as we maintain certain relations between the altered and the original reward. We name the proposed framework \textit{ClAssification-based REward Shaping} (CaReS), since we learn the altered reward in a self-supervised manner using classifier based reward inference. Experimental results on several sparse-reward environments demonstrate that the proposed algorithm is not only significantly more sample efficient than the state-of-the-art baseline, but also achieves a similar sample efficiency to MDPs that use hand-designed dense reward functions.
Local Nonparametric Meta-Learning
Feb 09, 2020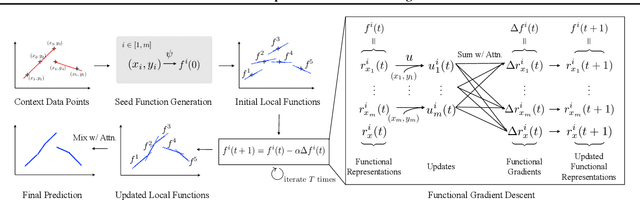
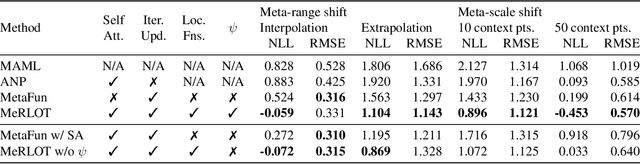
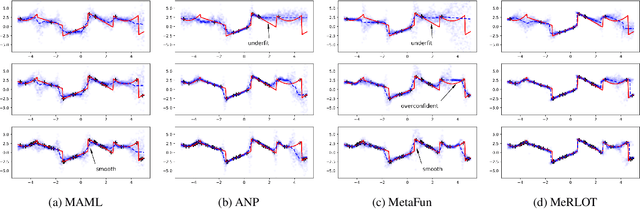
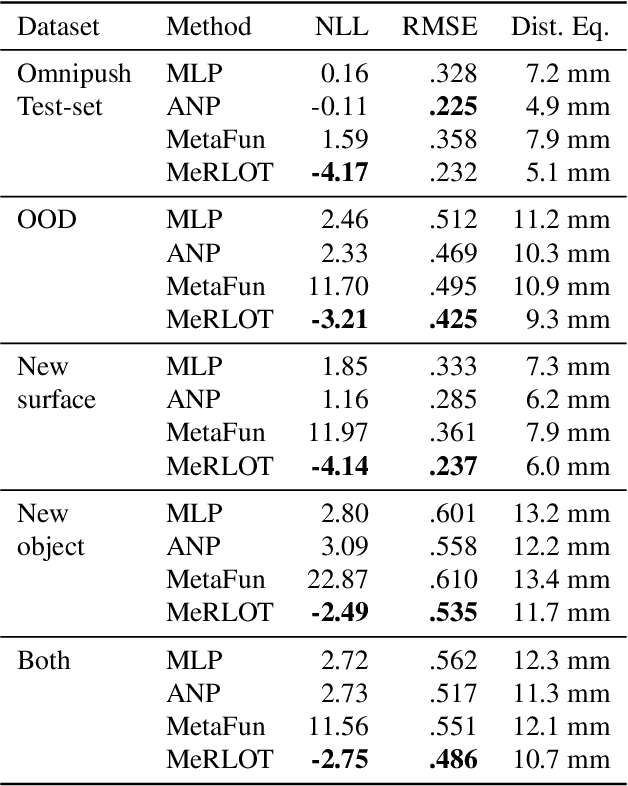
A central goal of meta-learning is to find a learning rule that enables fast adaptation across a set of tasks, by learning the appropriate inductive bias for that set. Most meta-learning algorithms try to find a \textit{global} learning rule that encodes this inductive bias. However, a global learning rule represented by a fixed-size representation is prone to meta-underfitting or -overfitting since the right representational power for a task set is difficult to choose a priori. Even when chosen correctly, we show that global, fixed-size representations often fail when confronted with certain types of out-of-distribution tasks, even when the same inductive bias is appropriate. To address these problems, we propose a novel nonparametric meta-learning algorithm that utilizes a meta-trained local learning rule, building on recent ideas in attention-based and functional gradient-based meta-learning. In several meta-regression problems, we show improved meta-generalization results using our local, nonparametric approach and achieve state-of-the-art results in the robotics benchmark, Omnipush.
Ranking-Based Reward Extrapolation without Rankings
Jul 13, 2019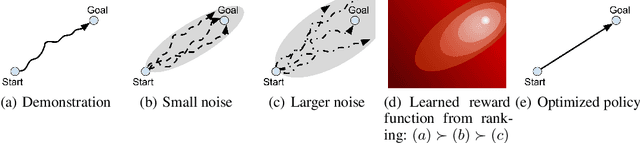
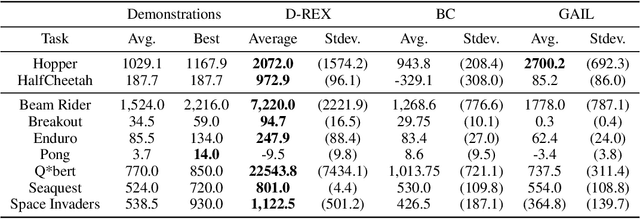
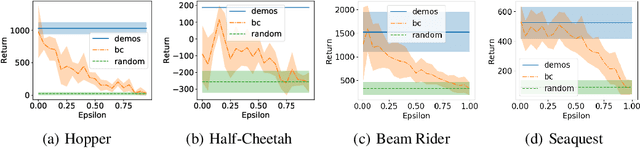
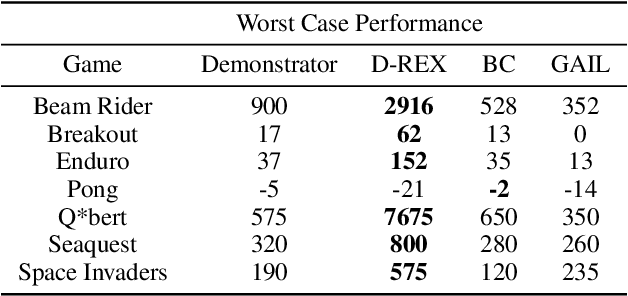
The performance of imitation learning is typically upper-bounded by the performance of the demonstrator. Recent empirical results show that imitation learning via ranked demonstrations allows for better-than-demonstrator performance; however, ranked demonstrations may be difficult to obtain, and little is known theoretically about when such methods can be expected to outperform the demonstrator. To address these issues, we first contribute a sufficient condition for when better-than-demonstrator performance is possible and discuss why ranked demonstrations can contribute to better-than-demonstrator performance. Building on this theory, we then introduce Disturbance-based Reward Extrapolation (D-REX), a ranking-based imitation learning method that injects noise into a policy learned through behavioral cloning to automatically generate ranked demonstrations. By generating rankings automatically, ranking-based imitation learning can be applied in traditional imitation learning settings where only unlabeled demonstrations are available. We empirically validate our approach on standard MuJoCo and Atari benchmarks and show that D-REX can utilize automatic rankings to significantly surpass the performance of the demonstrator and outperform standard imitation learning approaches. D-REX is the first imitation learning approach to achieve significant extrapolation beyond the demonstrator's performance without additional side-information or supervision, such as rewards or human preferences.
Extrapolating Beyond Suboptimal Demonstrations via Inverse Reinforcement Learning from Observations
May 14, 2019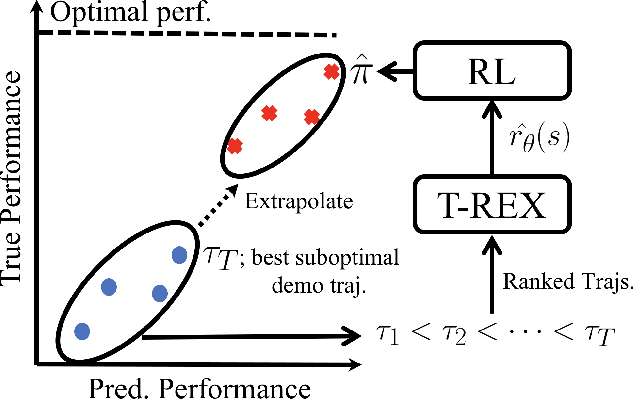

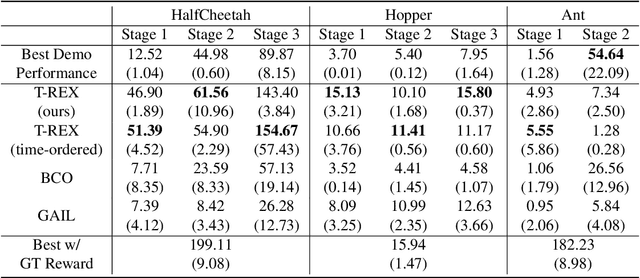
A critical flaw of existing inverse reinforcement learning (IRL) methods is their inability to significantly outperform the demonstrator. This is because IRL typically seeks a reward function that makes the demonstrator appear near-optimal, rather than inferring the underlying intentions of the demonstrator that may have been poorly executed in practice. In this paper, we introduce a novel reward-learning-from-observation algorithm, Trajectory-ranked Reward EXtrapolation (T-REX), that extrapolates beyond a set of (approximately) ranked demonstrations in order to infer high-quality reward functions from a set of potentially poor demonstrations. When combined with deep reinforcement learning, T-REX outperforms state-of-the-art imitation learning and IRL methods on multiple Atari and MuJoCo benchmark tasks and achieves performance that is often more than twice the performance of the best demonstration. We also demonstrate that T-REX is robust to ranking noise and can accurately extrapolate intention by simply watching a learner noisily improve at a task over time.
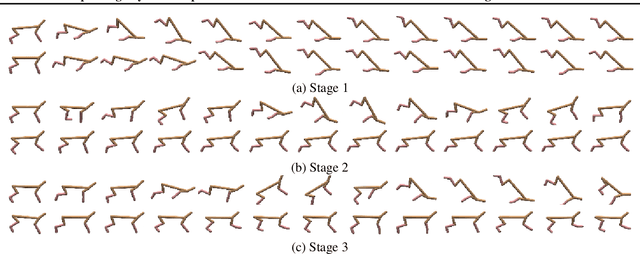
One-Shot Learning of Multi-Step Tasks from Observation via Activity Localization in Auxiliary Video
Sep 19, 2018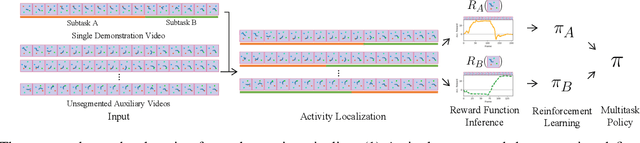

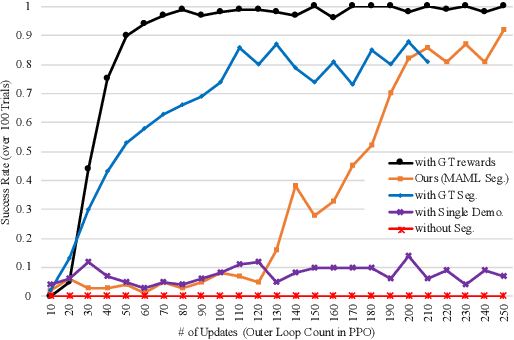
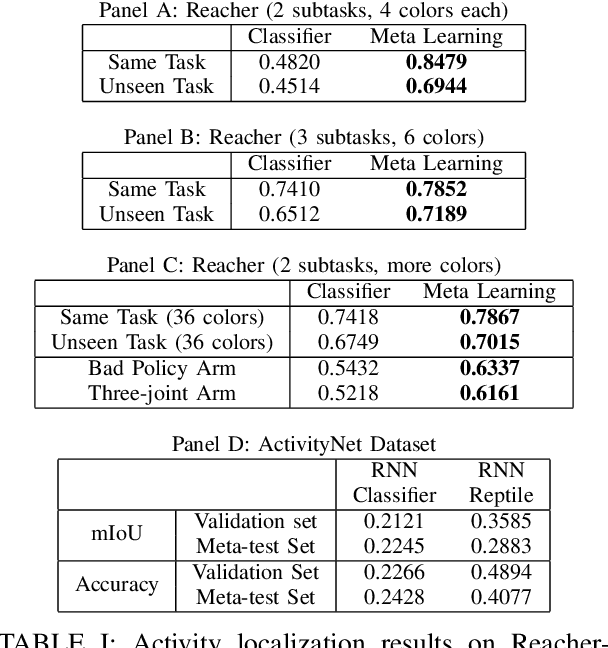
Due to burdensome data requirements, learning from demonstration often falls short of its promise to allow users to quickly and naturally program robots. Demonstrations are inherently ambiguous and incomplete, making correct generalization to unseen situations difficult without a large number of demonstrations in varying conditions. By contrast, humans are often able to learn complex tasks from a single demonstration (typically observations without action labels) by leveraging context learned over a lifetime. Inspired by this capability, our goal is to enable robots to perform one-shot learning of multi-step tasks from observation by leveraging auxiliary video data as context. Our primary contribution is a novel system that achieves this goal by: (1) using a single user-segmented demonstration to define the primitive actions that comprise a task, (2) localizing additional examples of these actions in unsegmented auxiliary videos via a metalearning-based approach, (3) using these additional examples to learn a reward function for each action, and (4) performing reinforcement learning on top of the inferred reward functions to learn action policies that can be combined to accomplish the task. We empirically demonstrate that a robot can learn multi-step tasks more effectively when provided auxiliary video, and that performance greatly improves when localizing individual actions, compared to learning from unsegmented videos.