 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen is Offline Policy Selection Sample Efficient for Reinforcement Learning?
Dec 04, 2023



Offline reinforcement learning algorithms often require careful hyperparameter tuning. Consequently, before deployment, we need to select amongst a set of candidate policies. As yet, however, there is little understanding about the fundamental limits of this offline policy selection (OPS) problem. In this work we aim to provide clarity on when sample efficient OPS is possible, primarily by connecting OPS to off-policy policy evaluation (OPE) and Bellman error (BE) estimation. We first show a hardness result, that in the worst case, OPS is just as hard as OPE, by proving a reduction of OPE to OPS. As a result, no OPS method can be more sample efficient than OPE in the worst case. We then propose a BE method for OPS, called Identifiable BE Selection (IBES), that has a straightforward method for selecting its own hyperparameters. We highlight that using IBES for OPS generally has more requirements than OPE methods, but if satisfied, can be more sample efficient. We conclude with an empirical study comparing OPE and IBES, and by showing the difficulty of OPS on an offline Atari benchmark dataset.
Distributed Reinforcement Learning of Targeted Grasping with Active Vision for Mobile Manipulators
Jul 16, 2020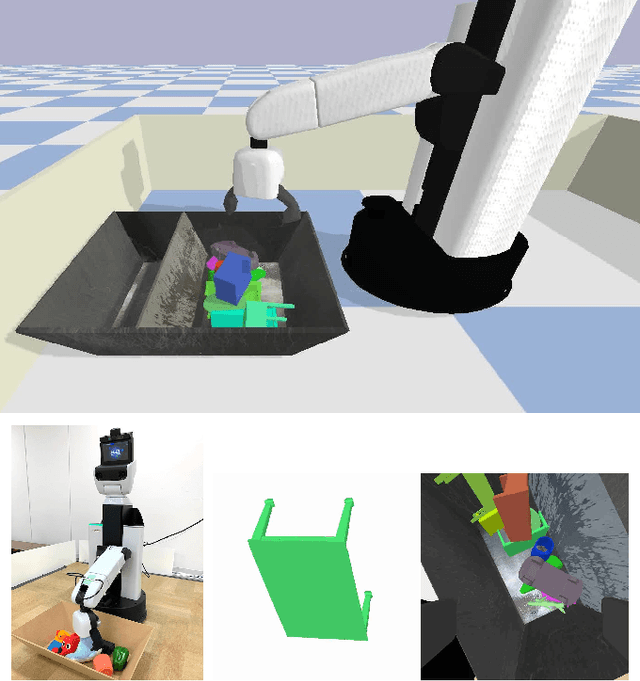
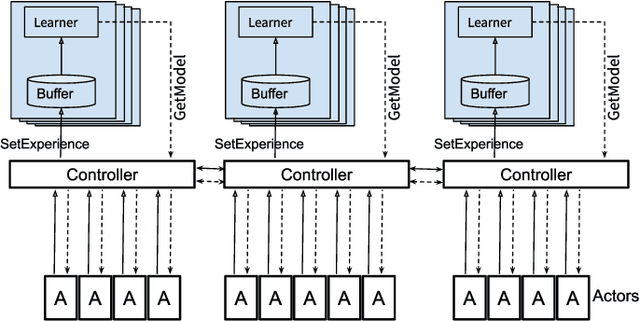
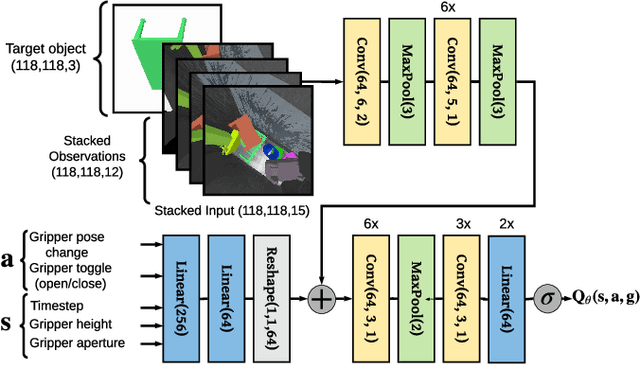
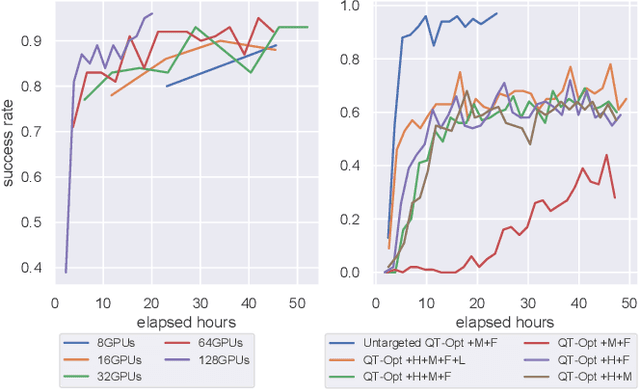
Developing personal robots that can perform a diverse range of manipulation tasks in unstructured environments necessitates solving several challenges for robotic grasping systems. We take a step towards this broader goal by presenting the first RL-based system, to our knowledge, for a mobile manipulator that can (a) achieve targeted grasping generalizing to unseen target objects, (b) learn complex grasping strategies for cluttered scenes with occluded objects, and (c) perform active vision through its movable wrist camera to better locate objects. The system is informed of the desired target object in the form of a single, arbitrary-pose RGB image of that object, enabling the system to generalize to unseen objects without retraining. To achieve such a system, we combine several advances in deep reinforcement learning and present a large-scale distributed training system using synchronous SGD that seamlessly scales to multi-node, multi-GPU infrastructure to make rapid prototyping easier. We train and evaluate our system in a simulated environment, identify key components for improving performance, analyze its behaviors, and transfer to a real-world setup.
Periodic Intra-Ensemble Knowledge Distillation for Reinforcement Learning
Feb 01, 2020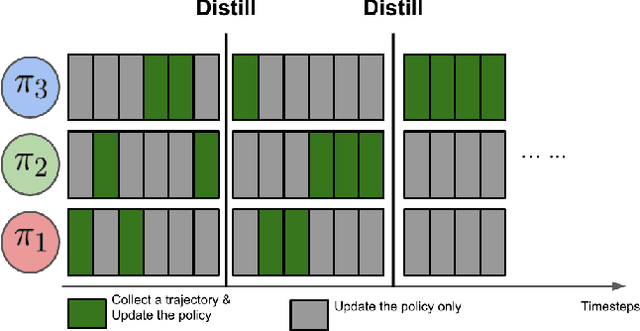
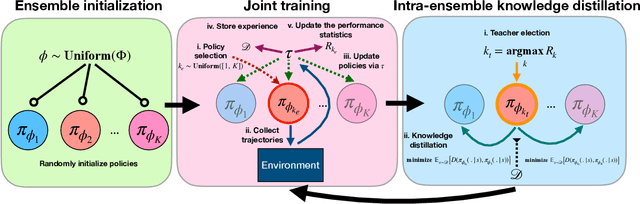

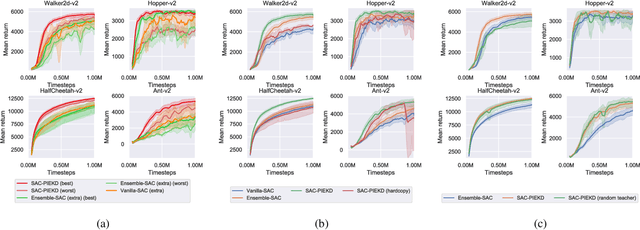
Off-policy ensemble reinforcement learning (RL) methods have demonstrated impressive results across a range of RL benchmark tasks. Recent works suggest that directly imitating experts' policies in a supervised manner before or during the course of training enables faster policy improvement for an RL agent. Motivated by these recent insights, we propose Periodic Intra-Ensemble Knowledge Distillation (PIEKD). PIEKD is a learning framework that uses an ensemble of policies to act in the environment while periodically sharing knowledge amongst policies in the ensemble through knowledge distillation. Our experiments demonstrate that PIEKD improves upon a state-of-the-art RL method in sample efficiency on several challenging MuJoCo benchmark tasks. Additionally, we perform ablation studies to better understand PIEKD.
Learning Latent State Spaces for Planning through Reward Prediction
Dec 09, 2019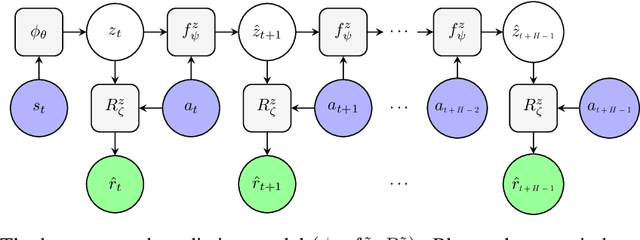
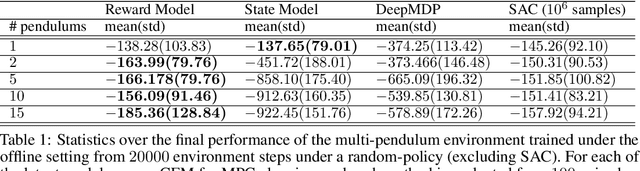
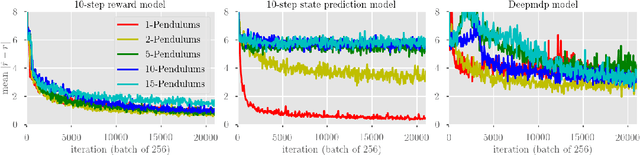
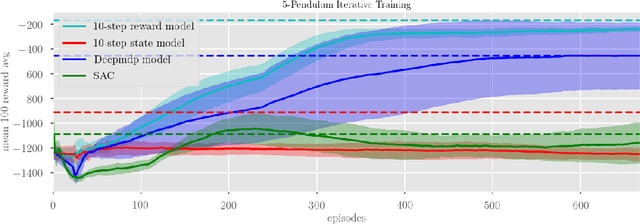
Model-based reinforcement learning methods typically learn models for high-dimensional state spaces by aiming to reconstruct and predict the original observations. However, drawing inspiration from model-free reinforcement learning, we propose learning a latent dynamics model directly from rewards. In this work, we introduce a model-based planning framework which learns a latent reward prediction model and then plans in the latent state-space. The latent representation is learned exclusively from multi-step reward prediction which we show to be the only necessary information for successful planning. With this framework, we are able to benefit from the concise model-free representation, while still enjoying the data-efficiency of model-based algorithms. We demonstrate our framework in multi-pendulum and multi-cheetah environments where several pendulums or cheetahs are shown to the agent but only one of which produces rewards. In these environments, it is important for the agent to construct a concise latent representation to filter out irrelevant observations. We find that our method can successfully learn an accurate latent reward prediction model in the presence of the irrelevant information while existing model-based methods fail. Planning in the learned latent state-space shows strong performance and high sample efficiency over model-free and model-based baselines.
ChainerRL: A Deep Reinforcement Learning Library
Dec 09, 2019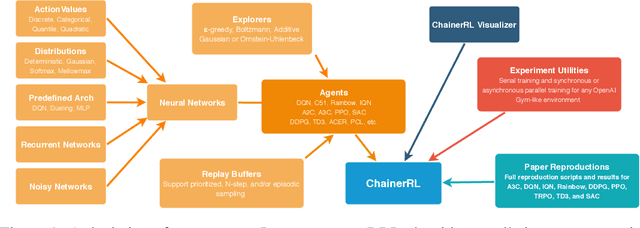
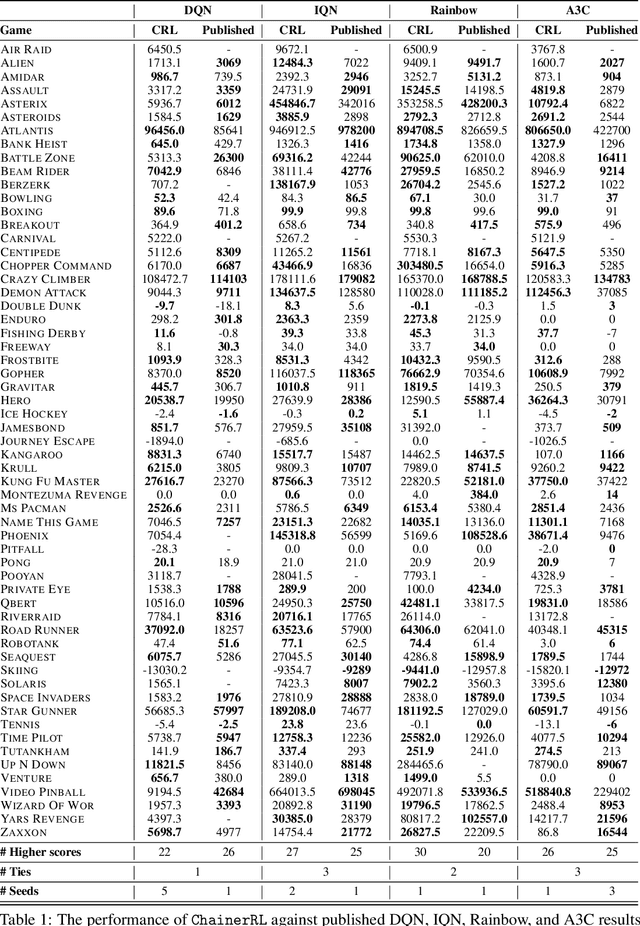
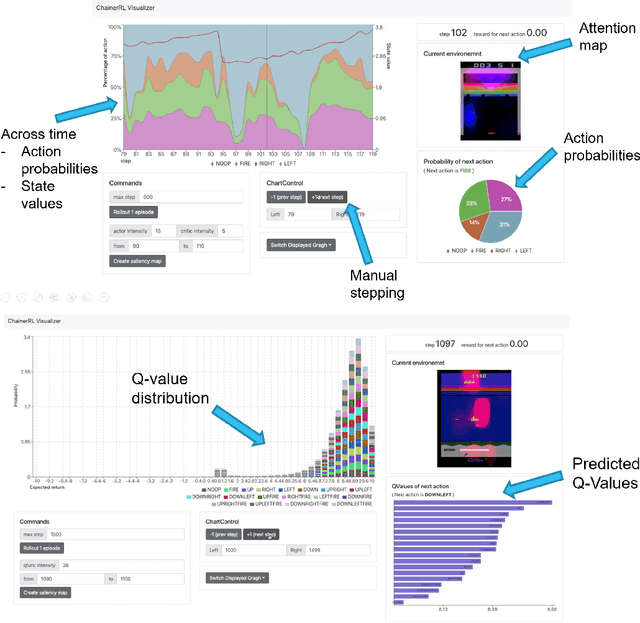

In this paper, we introduce ChainerRL, an open-source Deep Reinforcement Learning (DRL) library built using Python and the Chainer deep learning framework. ChainerRL implements a comprehensive set of DRL algorithms and techniques drawn from the state-of-the-art research in the field. To foster reproducible research, and for instructional purposes, ChainerRL provides scripts that closely replicate the original papers' experimental settings and reproduce published benchmark results for several algorithms. Lastly, ChainerRL offers a visualization tool that enables the qualitative inspection of trained agents. The ChainerRL source code can be found on GitHub: https://github.com/chainer/chainerrl .
Extrapolating Beyond Suboptimal Demonstrations via Inverse Reinforcement Learning from Observations
May 14, 2019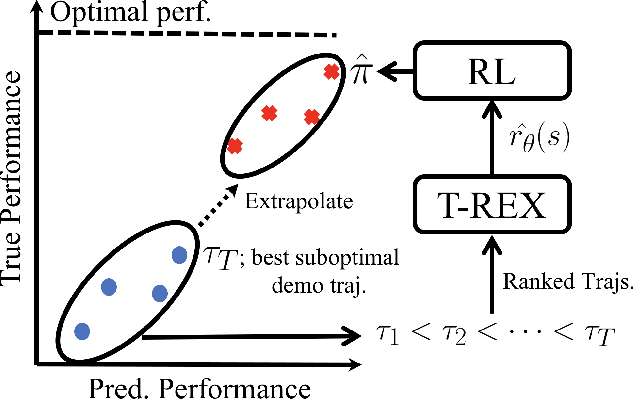

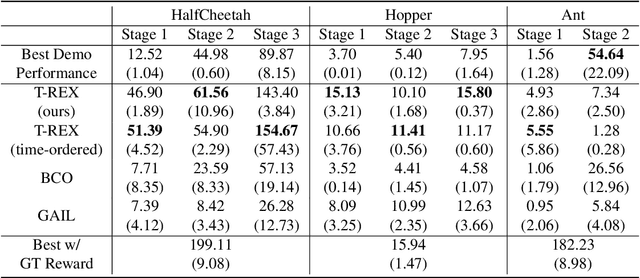
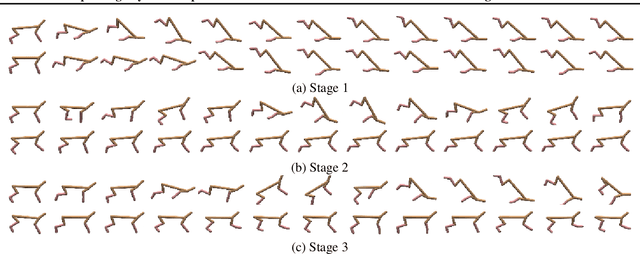
A critical flaw of existing inverse reinforcement learning (IRL) methods is their inability to significantly outperform the demonstrator. This is because IRL typically seeks a reward function that makes the demonstrator appear near-optimal, rather than inferring the underlying intentions of the demonstrator that may have been poorly executed in practice. In this paper, we introduce a novel reward-learning-from-observation algorithm, Trajectory-ranked Reward EXtrapolation (T-REX), that extrapolates beyond a set of (approximately) ranked demonstrations in order to infer high-quality reward functions from a set of potentially poor demonstrations. When combined with deep reinforcement learning, T-REX outperforms state-of-the-art imitation learning and IRL methods on multiple Atari and MuJoCo benchmark tasks and achieves performance that is often more than twice the performance of the best demonstration. We also demonstrate that T-REX is robust to ranking noise and can accurately extrapolate intention by simply watching a learner noisily improve at a task over time.
Deterministic Implementations for Reproducibility in Deep Reinforcement Learning
Sep 19, 2018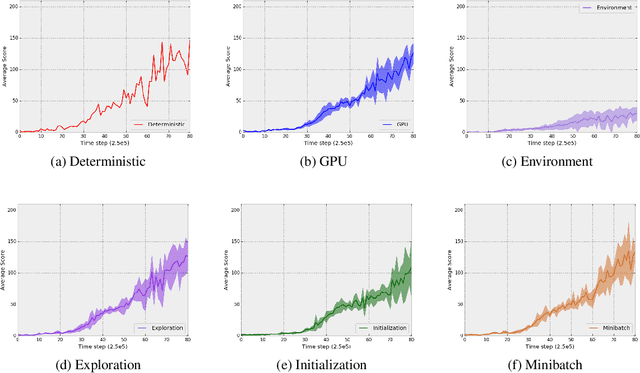
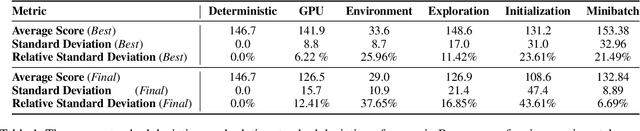
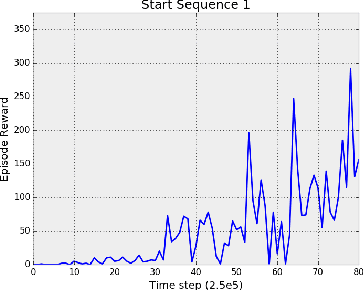
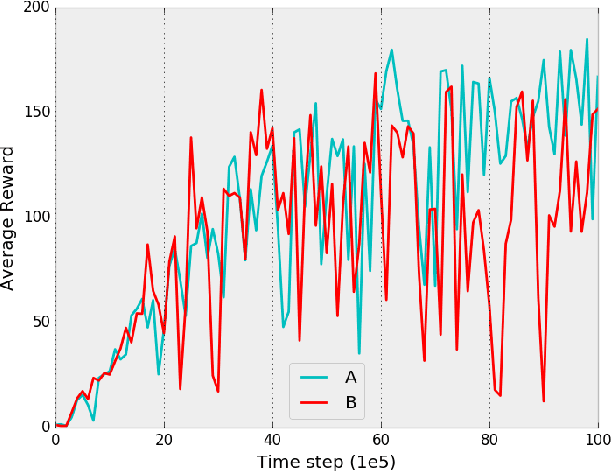
While deep reinforcement learning (DRL) has led to numerous successes in recent years, reproducing these successes can be extremely challenging. One reproducibility challenge particularly relevant to DRL is nondeterminism in the training process, which can substantially affect the results. Motivated by this challenge, we study the positive impacts of deterministic implementations in eliminating nondeterminism in training. To do so, we consider the particular case of the deep Q-learning algorithm, for which we produce a deterministic implementation by identifying and controlling all sources of nondeterminism in the training process. One by one, we then allow individual sources of nondeterminism to affect our otherwise deterministic implementation, and measure the impact of each source on the variance in performance. We find that individual sources of nondeterminism can substantially impact the performance of agent, illustrating the benefits of deterministic implementations. In addition, we also discuss the important role of deterministic implementations in achieving exact replicability of results.