 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePLaMo 2 Technical Report
Sep 05, 2025In this report, we introduce PLaMo 2, a series of Japanese-focused large language models featuring a hybrid Samba-based architecture that transitions to full attention via continual pre-training to support 32K token contexts. Training leverages extensive synthetic corpora to overcome data scarcity, while computational efficiency is achieved through weight reuse and structured pruning. This efficient pruning methodology produces an 8B model that achieves performance comparable to our previous 100B model. Post-training further refines the models using a pipeline of supervised fine-tuning (SFT) and direct preference optimization (DPO), enhanced by synthetic Japanese instruction data and model merging techniques. Optimized for inference using vLLM and quantization with minimal accuracy loss, the PLaMo 2 models achieve state-of-the-art results on Japanese benchmarks, outperforming similarly-sized open models in instruction-following, language fluency, and Japanese-specific knowledge.
Four-Axis Adaptive Fingers Hand for Object Insertion: FAAF Hand
Jul 30, 2024



Robots operating in the real world face significant but unavoidable issues in object localization that must be dealt with. A typical approach to address this is the addition of compliance mechanisms to hardware to absorb and compensate for some of these errors. However, for fine-grained manipulation tasks, the location and choice of appropriate compliance mechanisms are critical for success. For objects to be inserted in a target site on a flat surface, the object must first be successfully aligned with the opening of the slot, as well as correctly oriented along its central axis, before it can be inserted. We developed the Four-Axis Adaptive Finger Hand (FAAF hand) that is equipped with fingers that can passively adapt in four axes (x, y, z, yaw) enabling it to perform insertion tasks including lid fitting in the presence of significant localization errors. Furthermore, this adaptivity allows the use of simple control methods without requiring contact sensors or other devices. Our results confirm the ability of the FAAF hand on challenging insertion tasks of square and triangle-shaped pegs (or prisms) and placing of container lids in the presence of position errors in all directions and rotational error along the object's central axis, using a simple control scheme.
SAID-NeRF: Segmentation-AIDed NeRF for Depth Completion of Transparent Objects
Mar 28, 2024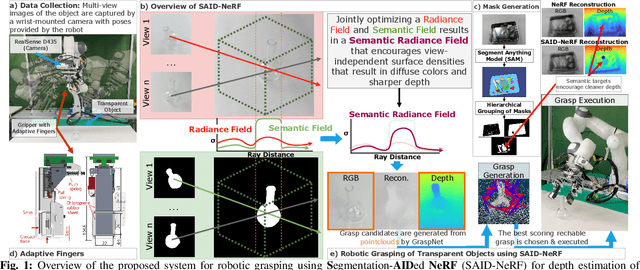
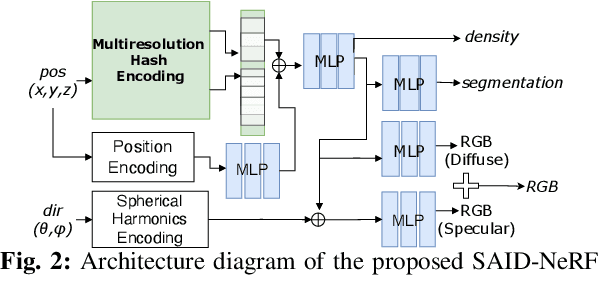


Acquiring accurate depth information of transparent objects using off-the-shelf RGB-D cameras is a well-known challenge in Computer Vision and Robotics. Depth estimation/completion methods are typically employed and trained on datasets with quality depth labels acquired from either simulation, additional sensors or specialized data collection setups and known 3d models. However, acquiring reliable depth information for datasets at scale is not straightforward, limiting training scalability and generalization. Neural Radiance Fields (NeRFs) are learning-free approaches and have demonstrated wide success in novel view synthesis and shape recovery. However, heuristics and controlled environments (lights, backgrounds, etc) are often required to accurately capture specular surfaces. In this paper, we propose using Visual Foundation Models (VFMs) for segmentation in a zero-shot, label-free way to guide the NeRF reconstruction process for these objects via the simultaneous reconstruction of semantic fields and extensions to increase robustness. Our proposed method Segmentation-AIDed NeRF (SAID-NeRF) shows significant performance on depth completion datasets for transparent objects and robotic grasping.
Laboratory Automation: Precision Insertion with Adaptive Fingers utilizing Contact through Sliding with Tactile-based Pose Estimation
Sep 28, 2023



Micro well-plates are commonly used apparatus in chemical and biological experiments that are a few centimeters in thickness with wells in them. The task we aim to solve is to place (insert) them onto a well-plate holder with grooves a few millimeters in height. Our insertion task has the following facets: 1) There is uncertainty in the detection of the position and pose of the well-plate and well-plate holder, 2) the accuracy required is in the order of millimeter to sub-millimeter, 3) the well-plate holder is not fastened, and moves with external force, 4) the groove is shallow, and 5) the width of the groove is small. Addressing these challenges, we developed a) an adaptive finger gripper with accurate detection of finger position (for (1)), b) grasped object pose estimation using tactile sensors (for (1)), c) a method to insert the well-plate into the target holder by sliding the well-plate while maintaining contact with the edge of the holder (for (2-4)), and d) estimating the orientation of the edge and aligning the well-plate so that the holder does not move when maintaining contact with the edge (for (5)). We show a significantly high success rate on the insertion task of the well-plate, even though under added noise. An accompanying video is available at the following link: https://drive.google.com/file/d/1UxyJ3XIxqXPnHcpfw-PYs5T5oYQxoc6i/view?usp=sharing
Two-fingered Hand with Gear-type Synchronization Mechanism with Magnet for Improved Small and Offset Objects Grasping: F2 Hand
Sep 20, 2023



A problem that plagues robotic grasping is the misalignment of the object and gripper due to difficulties in precise localization, actuation, etc. Under-actuated robotic hands with compliant mechanisms are used to adapt and compensate for these inaccuracies. However, these mechanisms come at the cost of controllability and coordination. For instance, adaptive functions that let the fingers of a two-fingered gripper adapt independently may affect the coordination necessary for grasping small objects. In this work, we develop a two-fingered robotic hand capable of grasping objects that are offset from the gripper's center, while still having the requisite coordination for grasping small objects via a novel gear-type synchronization mechanism with a magnet. This gear synchronization mechanism allows the adaptive finger's tips to be aligned enabling it to grasp objects as small as toothpicks and washers. The magnetic component allows this coordination to automatically turn off when needed, allowing for the grasping of objects that are offset/misaligned from the gripper. This equips the hand with the capability of grasping light, fragile objects (strawberries, creampuffs, etc) to heavy frying pan lids, all while maintaining their position and posture which is vital in numerous applications that require precise positioning or careful manipulation.
F3 Hand: A Versatile Robot Hand Inspired by Human Thumb and Index Fingers
Jun 16, 2022


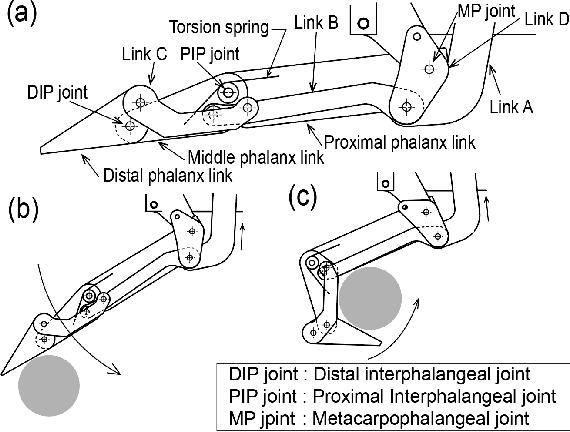
It is challenging to grasp numerous objects with varying sizes and shapes with a single robot hand. To address this, we propose a new robot hand called the 'F3 hand' inspired by the complex movements of human index finger and thumb. The F3 hand attempts to realize complex human-like grasping movements by combining a parallel motion finger and a rotational motion finger with an adaptive function. In order to confirm the performance of our hand, we attached it to a mobile manipulator - the Toyota Human Support Robot (HSR) and conducted grasping experiments. In our results, we show that it is able to grasp all YCB objects (82 in total), including washers with outer diameters as small as 6.4mm. We also built a system for intuitive operation with a 3D mouse and grasp an additional 24 objects, including small toothpicks and paper clips and large pitchers and cracker boxes. The F3 hand is able to achieve a 98% success rate in grasping even under imprecise control and positional offsets. Furthermore, owing to the finger's adaptive function, we demonstrate characteristics of the F3 hand that facilitate the grasping of soft objects such as strawberries in a desirable posture.
Cluttered Food Grasping with Adaptive Fingers and Synthetic-Data Trained Object Detection
Mar 10, 2022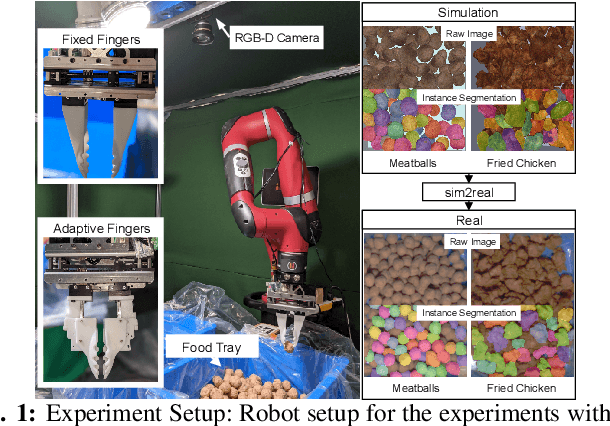


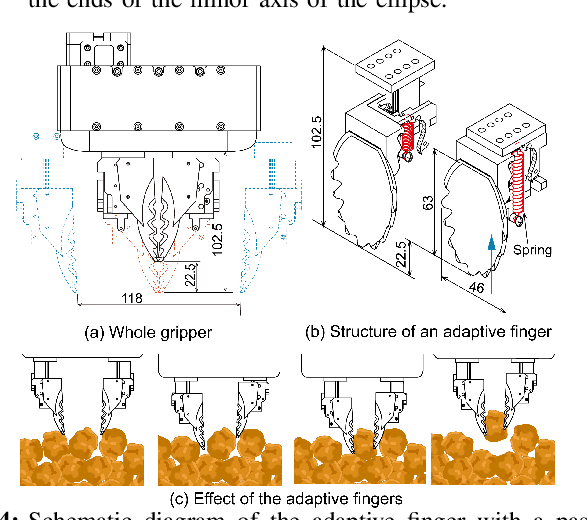
The food packaging industry handles an immense variety of food products with wide-ranging shapes and sizes, even within one kind of food. Menus are also diverse and change frequently, making automation of pick-and-place difficult. A popular approach to bin-picking is to first identify each piece of food in the tray by using an instance segmentation method. However, human annotations to train these methods are unreliable and error-prone since foods are packed close together with unclear boundaries and visual similarity making separation of pieces difficult. To address this problem, we propose a method that trains purely on synthetic data and successfully transfers to the real world using sim2real methods by creating datasets of filled food trays using high-quality 3d models of real pieces of food for the training instance segmentation models. Another concern is that foods are easily damaged during grasping. We address this by introducing two additional methods -- a novel adaptive finger mechanism to passively retract when a collision occurs, and a method to filter grasps that are likely to cause damage to neighbouring pieces of food during a grasp. We demonstrate the effectiveness of the proposed method on several kinds of real foods.
Target-mass Grasping of Entangled Food using Pre-grasping & Post-grasping
Jan 11, 2022
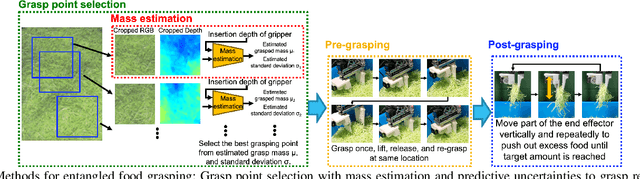
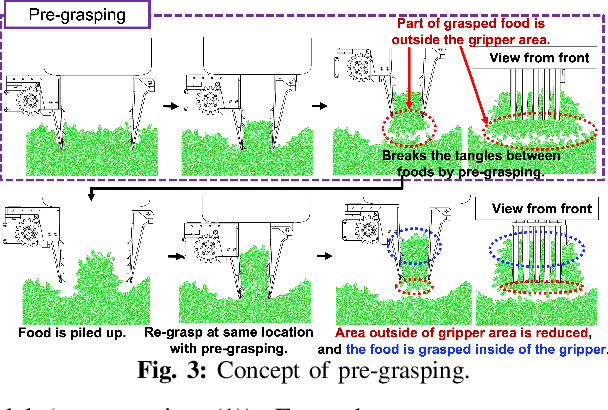
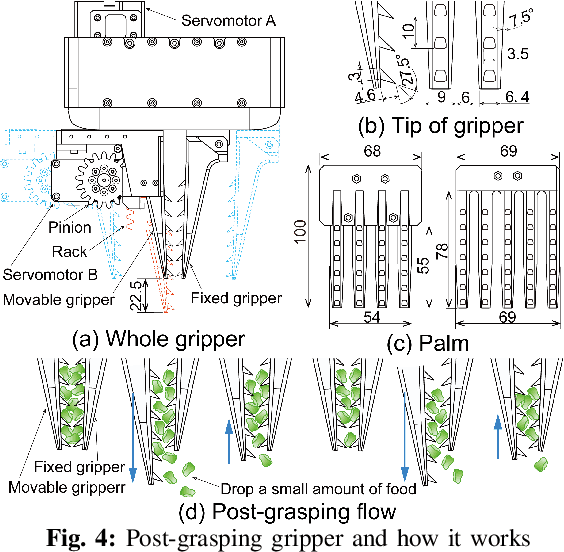
Food packing industries typically use seasonal ingredients with immense variety that factory workers manually pack. For small pieces of food picked by volume or weight that tend to get entangled, stick or clump together, it is difficult to predict how intertwined they are from a visual examination, making it a challenge to grasp the requisite target mass accurately. Workers rely on a combination of weighing scales and a sequence of complex maneuvers to separate out the food and reach the target mass. This makes automation of the process a non-trivial affair. In this study, we propose methods that combines 1) pre-grasping to reduce the degree of the entanglement, 2) post-grasping to adjust the grasped mass using a novel gripper mechanism to carefully discard excess food when the grasped amount is larger than the target mass, and 3) selecting the grasping point to grasp an amount likely to be reasonably higher than target grasping mass with confidence. We evaluate the methods on a variety of foods that entangle, stick and clump, each of which has a different size, shape, and material properties such as volumetric mass density. We show significant improvement in grasp accuracy of user-specified target masses using our proposed methods.
* 8 pages. Accepted at IEEE Robotics and Automation Letters (RA-L). Under review for option of ICRA2022. An accompanying video is available at the following link: https://youtu.be/jGYGq5hDybs
Uncertainty-Aware Self-Supervised Target-Mass Grasping of Granular Foods
May 27, 2021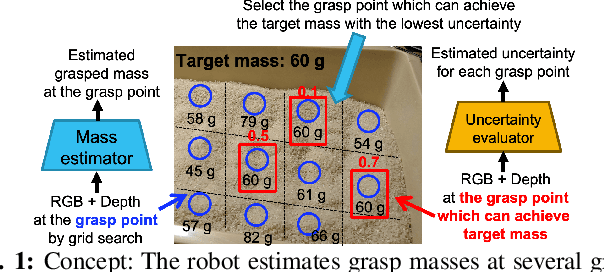
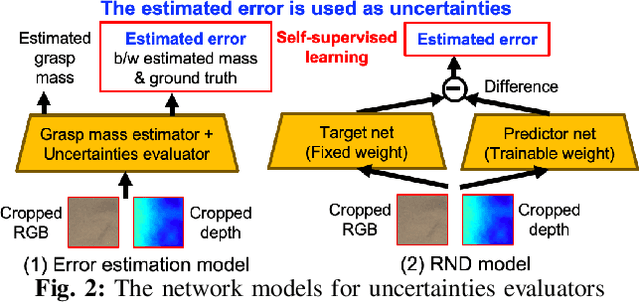

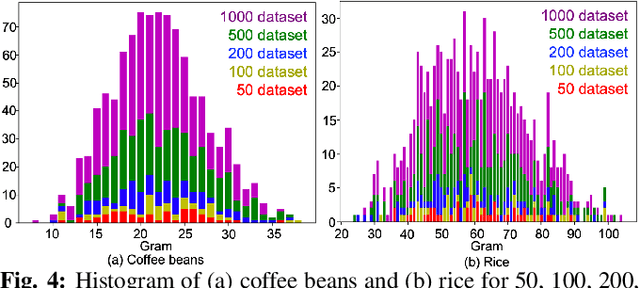
Food packing industry workers typically pick a target amount of food by hand from a food tray and place them in containers. Since menus are diverse and change frequently, robots must adapt and learn to handle new foods in a short time-span. Learning to grasp a specific amount of granular food requires a large training dataset, which is challenging to collect reasonably quickly. In this study, we propose ways to reduce the necessary amount of training data by augmenting a deep neural network with models that estimate its uncertainty through self-supervised learning. To further reduce human effort, we devise a data collection system that automatically generates labels. We build on the idea that we can grasp sufficiently well if there is at least one low-uncertainty (high-confidence) grasp point among the various grasp point candidates. We evaluate the methods we propose in this work on a variety of granular foods -- coffee beans, rice, oatmeal and peanuts -- each of which has a different size, shape and material properties such as volumetric mass density or friction. For these foods, we show significantly improved grasp accuracy of user-specified target masses using smaller datasets by incorporating uncertainty.
The MineRL 2020 Competition on Sample Efficient Reinforcement Learning using Human Priors
Jan 26, 2021
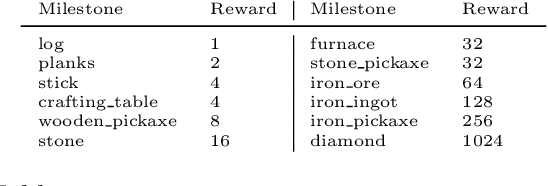
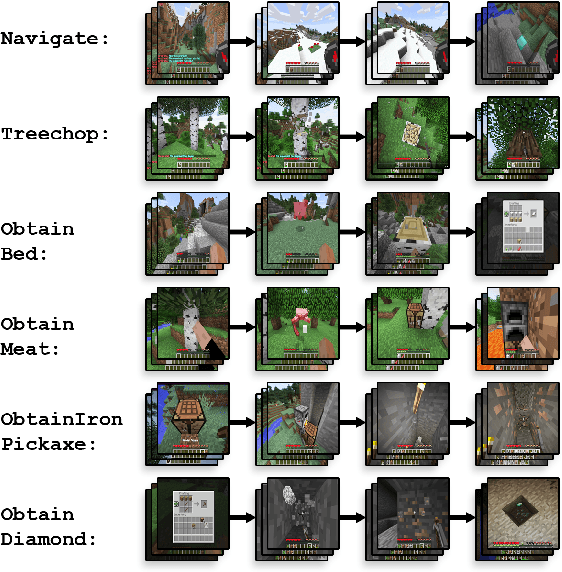
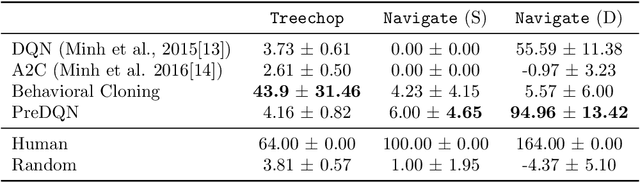
Although deep reinforcement learning has led to breakthroughs in many difficult domains, these successes have required an ever-increasing number of samples, affording only a shrinking segment of the AI community access to their development. Resolution of these limitations requires new, sample-efficient methods. To facilitate research in this direction, we propose this second iteration of the MineRL Competition. The primary goal of the competition is to foster the development of algorithms which can efficiently leverage human demonstrations to drastically reduce the number of samples needed to solve complex, hierarchical, and sparse environments. To that end, participants compete under a limited environment sample-complexity budget to develop systems which solve the MineRL ObtainDiamond task in Minecraft, a sequential decision making environment requiring long-term planning, hierarchical control, and efficient exploration methods. The competition is structured into two rounds in which competitors are provided several paired versions of the dataset and environment with different game textures and shaders. At the end of each round, competitors submit containerized versions of their learning algorithms to the AIcrowd platform where they are trained from scratch on a hold-out dataset-environment pair for a total of 4-days on a pre-specified hardware platform. In this follow-up iteration to the NeurIPS 2019 MineRL Competition, we implement new features to expand the scale and reach of the competition. In response to the feedback of the previous participants, we introduce a second minor track focusing on solutions without access to environment interactions of any kind except during test-time. Further we aim to prompt domain agnostic submissions by implementing several novel competition mechanics including action-space randomization and desemantization of observations and actions.