 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty-Aware Self-Supervised Target-Mass Grasping of Granular Foods
May 27, 2021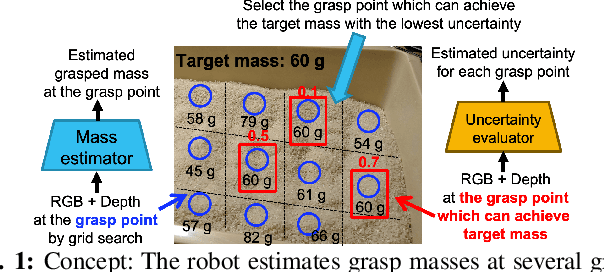
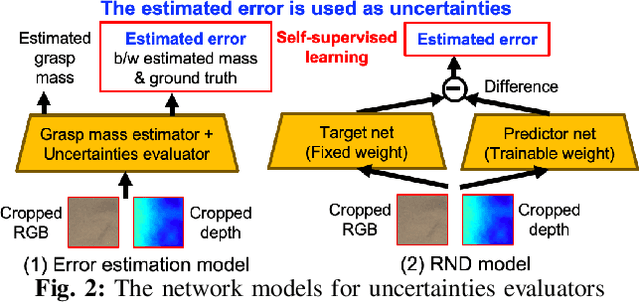

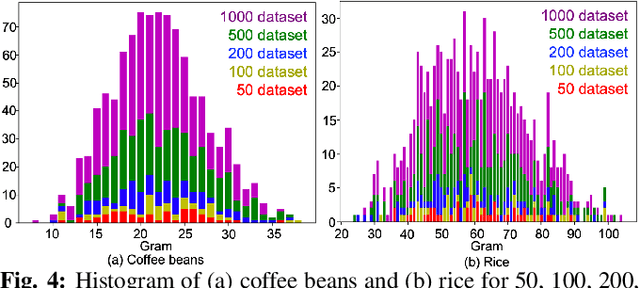
Food packing industry workers typically pick a target amount of food by hand from a food tray and place them in containers. Since menus are diverse and change frequently, robots must adapt and learn to handle new foods in a short time-span. Learning to grasp a specific amount of granular food requires a large training dataset, which is challenging to collect reasonably quickly. In this study, we propose ways to reduce the necessary amount of training data by augmenting a deep neural network with models that estimate its uncertainty through self-supervised learning. To further reduce human effort, we devise a data collection system that automatically generates labels. We build on the idea that we can grasp sufficiently well if there is at least one low-uncertainty (high-confidence) grasp point among the various grasp point candidates. We evaluate the methods we propose in this work on a variety of granular foods -- coffee beans, rice, oatmeal and peanuts -- each of which has a different size, shape and material properties such as volumetric mass density or friction. For these foods, we show significantly improved grasp accuracy of user-specified target masses using smaller datasets by incorporating uncertainty.
Interactively Picking Real-World Objects with Unconstrained Spoken Language Instructions
Mar 28, 2018
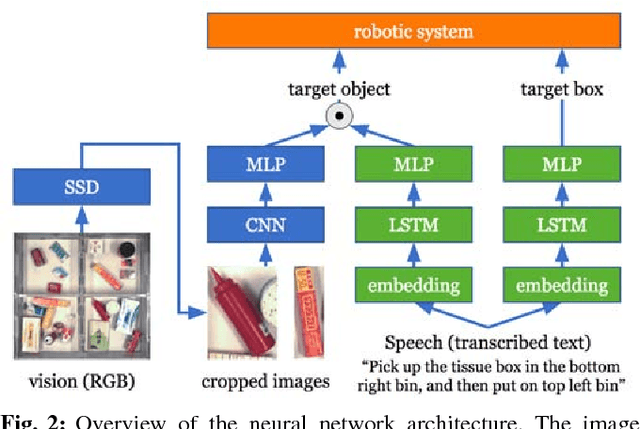

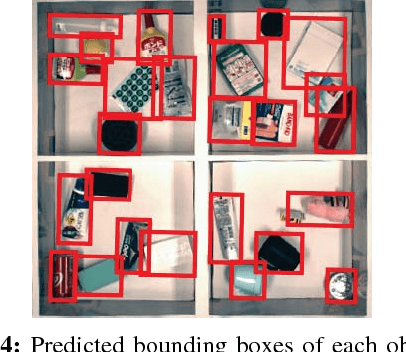
Comprehension of spoken natural language is an essential component for robots to communicate with human effectively. However, handling unconstrained spoken instructions is challenging due to (1) complex structures including a wide variety of expressions used in spoken language and (2) inherent ambiguity in interpretation of human instructions. In this paper, we propose the first comprehensive system that can handle unconstrained spoken language and is able to effectively resolve ambiguity in spoken instructions. Specifically, we integrate deep-learning-based object detection together with natural language processing technologies to handle unconstrained spoken instructions, and propose a method for robots to resolve instruction ambiguity through dialogue. Through our experiments on both a simulated environment as well as a physical industrial robot arm, we demonstrate the ability of our system to understand natural instructions from human operators effectively, and how higher success rates of the object picking task can be achieved through an interactive clarification process.
Map-based Multi-Policy Reinforcement Learning: Enhancing Adaptability of Robots by Deep Reinforcement Learning
Oct 18, 2017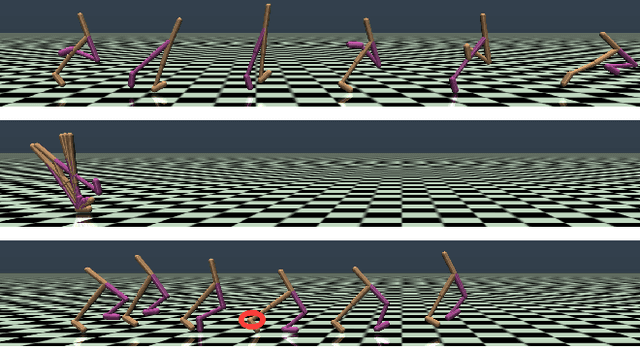
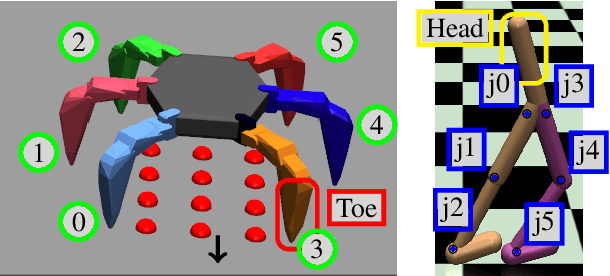

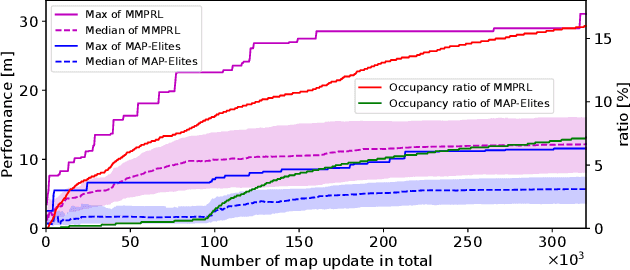
In order for robots to perform mission-critical tasks, it is essential that they are able to quickly adapt to changes in their environment as well as to injuries and or other bodily changes. Deep reinforcement learning has been shown to be successful in training robot control policies for operation in complex environments. However, existing methods typically employ only a single policy. This can limit the adaptability since a large environmental modification might require a completely different behavior compared to the learning environment. To solve this problem, we propose Map-based Multi-Policy Reinforcement Learning (MMPRL), which aims to search and store multiple policies that encode different behavioral features while maximizing the expected reward in advance of the environment change. Thanks to these policies, which are stored into a multi-dimensional discrete map according to its behavioral feature, adaptation can be performed within reasonable time without retraining the robot. An appropriate pre-trained policy from the map can be recalled using Bayesian optimization. Our experiments show that MMPRL enables robots to quickly adapt to large changes without requiring any prior knowledge on the type of injuries that could occur. A highlight of the learned behaviors can be found here: https://youtu.be/QwInbilXNOE .
Team Delft's Robot Winner of the Amazon Picking Challenge 2016
Oct 18, 2016
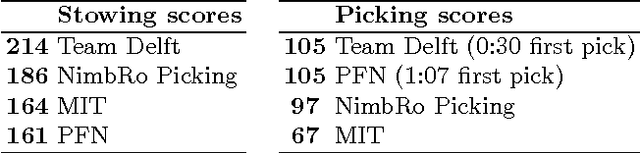

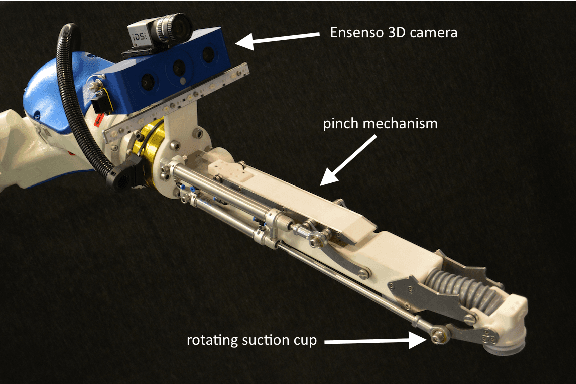
This paper describes Team Delft's robot, which won the Amazon Picking Challenge 2016, including both the Picking and the Stowing competitions. The goal of the challenge is to automate pick and place operations in unstructured environments, specifically the shelves in an Amazon warehouse. Team Delft's robot is based on an industrial robot arm, 3D cameras and a customized gripper. The robot's software uses ROS to integrate off-the-shelf components and modules developed specifically for the competition, implementing Deep Learning and other AI techniques for object recognition and pose estimation, grasp planning and motion planning. This paper describes the main components in the system, and discusses its performance and results at the Amazon Picking Challenge 2016 finals.