 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHiMoR: Monocular Deformable Gaussian Reconstruction with Hierarchical Motion Representation
Apr 08, 2025We present Hierarchical Motion Representation (HiMoR), a novel deformation representation for 3D Gaussian primitives capable of achieving high-quality monocular dynamic 3D reconstruction. The insight behind HiMoR is that motions in everyday scenes can be decomposed into coarser motions that serve as the foundation for finer details. Using a tree structure, HiMoR's nodes represent different levels of motion detail, with shallower nodes modeling coarse motion for temporal smoothness and deeper nodes capturing finer motion. Additionally, our model uses a few shared motion bases to represent motions of different sets of nodes, aligning with the assumption that motion tends to be smooth and simple. This motion representation design provides Gaussians with a more structured deformation, maximizing the use of temporal relationships to tackle the challenging task of monocular dynamic 3D reconstruction. We also propose using a more reliable perceptual metric as an alternative, given that pixel-level metrics for evaluating monocular dynamic 3D reconstruction can sometimes fail to accurately reflect the true quality of reconstruction. Extensive experiments demonstrate our method's efficacy in achieving superior novel view synthesis from challenging monocular videos with complex motions.
A Scaling Law for Synthetic-to-Real Transfer: A Measure of Pre-Training
Aug 25, 2021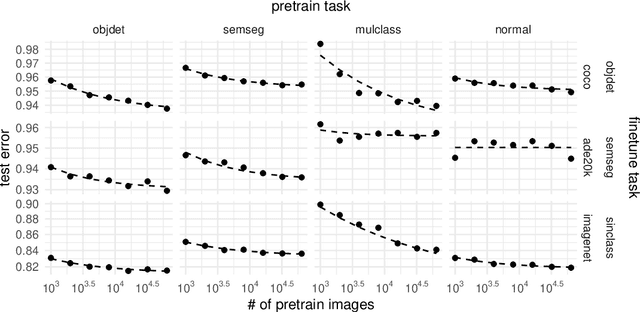

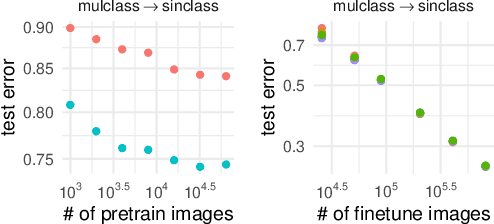
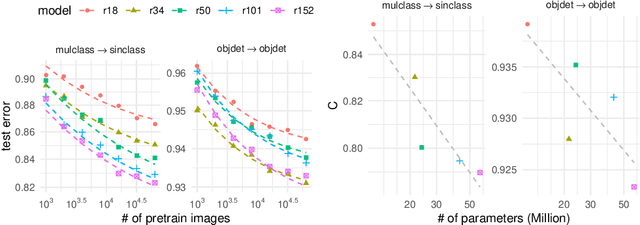
Synthetic-to-real transfer learning is a framework in which we pre-train models with synthetically generated images and ground-truth annotations for real tasks. Although synthetic images overcome the data scarcity issue, it remains unclear how the fine-tuning performance scales with pre-trained models, especially in terms of pre-training data size. In this study, we collect a number of empirical observations and uncover the secret. Through experiments, we observe a simple and general scaling law that consistently describes learning curves in various tasks, models, and complexities of synthesized pre-training data. Further, we develop a theory of transfer learning for a simplified scenario and confirm that the derived generalization bound is consistent with our empirical findings.
Addressing Class Imbalance in Scene Graph Parsing by Learning to Contrast and Score
Oct 05, 2020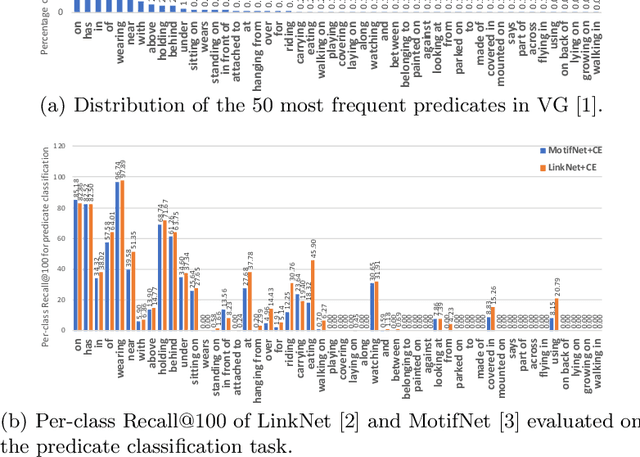
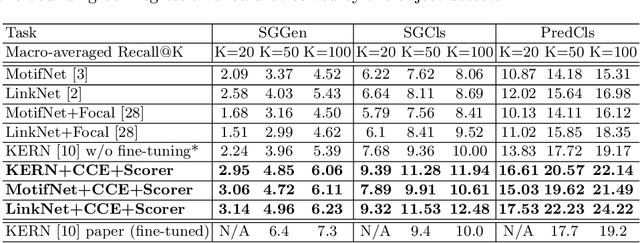
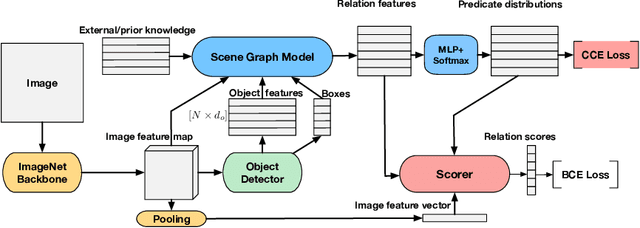
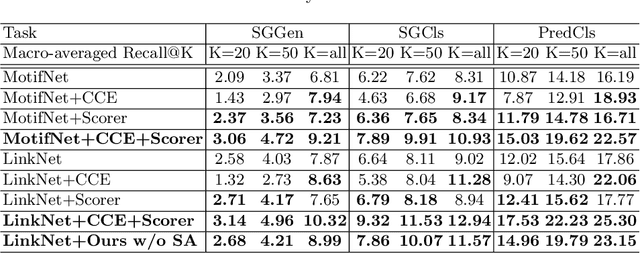
Scene graph parsing aims to detect objects in an image scene and recognize their relations. Recent approaches have achieved high average scores on some popular benchmarks, but fail in detecting rare relations, as the highly long-tailed distribution of data biases the learning towards frequent labels. Motivated by the fact that detecting these rare relations can be critical in real-world applications, this paper introduces a novel integrated framework of classification and ranking to resolve the class imbalance problem in scene graph parsing. Specifically, we design a new Contrasting Cross-Entropy loss, which promotes the detection of rare relations by suppressing incorrect frequent ones. Furthermore, we propose a novel scoring module, termed as Scorer, which learns to rank the relations based on the image features and relation features to improve the recall of predictions. Our framework is simple and effective, and can be incorporated into current scene graph models. Experimental results show that the proposed approach improves the current state-of-the-art methods, with a clear advantage of detecting rare relations.
Interactively Picking Real-World Objects with Unconstrained Spoken Language Instructions
Mar 28, 2018
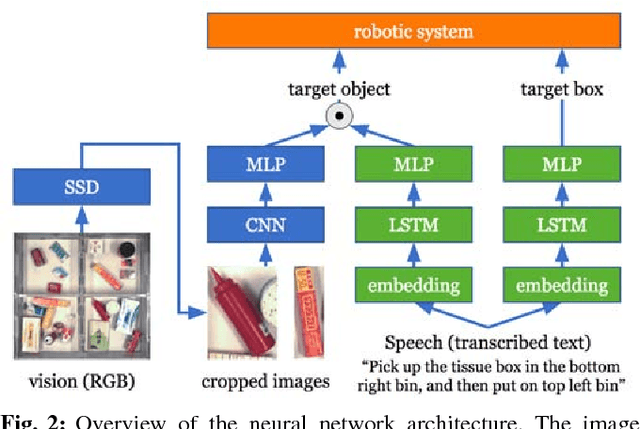

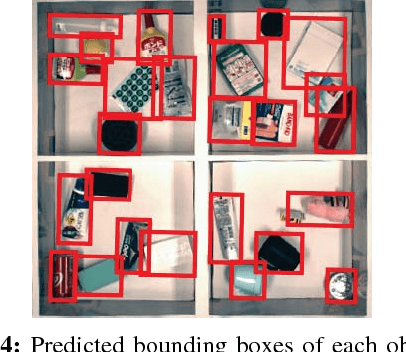
Comprehension of spoken natural language is an essential component for robots to communicate with human effectively. However, handling unconstrained spoken instructions is challenging due to (1) complex structures including a wide variety of expressions used in spoken language and (2) inherent ambiguity in interpretation of human instructions. In this paper, we propose the first comprehensive system that can handle unconstrained spoken language and is able to effectively resolve ambiguity in spoken instructions. Specifically, we integrate deep-learning-based object detection together with natural language processing technologies to handle unconstrained spoken instructions, and propose a method for robots to resolve instruction ambiguity through dialogue. Through our experiments on both a simulated environment as well as a physical industrial robot arm, we demonstrate the ability of our system to understand natural instructions from human operators effectively, and how higher success rates of the object picking task can be achieved through an interactive clarification process.
Neural Sequence Model Training via $α$-divergence Minimization
Jun 30, 2017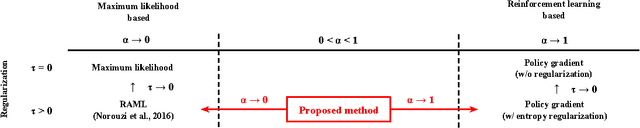

We propose a new neural sequence model training method in which the objective function is defined by $\alpha$-divergence. We demonstrate that the objective function generalizes the maximum-likelihood (ML)-based and reinforcement learning (RL)-based objective functions as special cases (i.e., ML corresponds to $\alpha \to 0$ and RL to $\alpha \to1$). We also show that the gradient of the objective function can be considered a mixture of ML- and RL-based objective gradients. The experimental results of a machine translation task show that minimizing the objective function with $\alpha > 0$ outperforms $\alpha \to 0$, which corresponds to ML-based methods.
Controlling Output Length in Neural Encoder-Decoders
Sep 30, 2016



Neural encoder-decoder models have shown great success in many sequence generation tasks. However, previous work has not investigated situations in which we would like to control the length of encoder-decoder outputs. This capability is crucial for applications such as text summarization, in which we have to generate concise summaries with a desired length. In this paper, we propose methods for controlling the output sequence length for neural encoder-decoder models: two decoding-based methods and two learning-based methods. Results show that our learning-based methods have the capability to control length without degrading summary quality in a summarization task.