 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Scaling Law for Synthetic-to-Real Transfer: A Measure of Pre-Training
Paper and Code
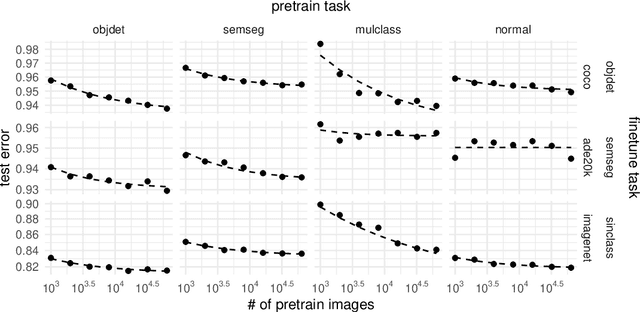

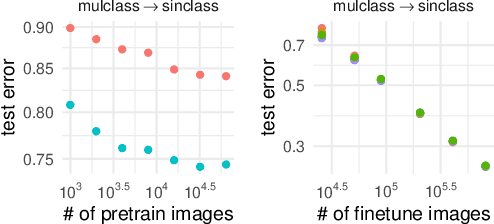
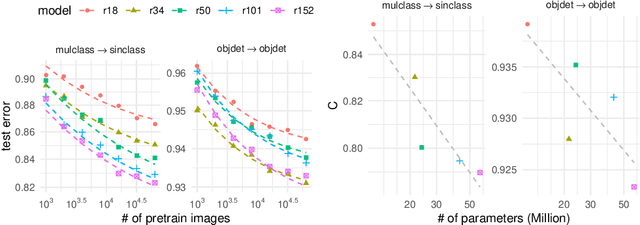
Synthetic-to-real transfer learning is a framework in which we pre-train models with synthetically generated images and ground-truth annotations for real tasks. Although synthetic images overcome the data scarcity issue, it remains unclear how the fine-tuning performance scales with pre-trained models, especially in terms of pre-training data size. In this study, we collect a number of empirical observations and uncover the secret. Through experiments, we observe a simple and general scaling law that consistently describes learning curves in various tasks, models, and complexities of synthesized pre-training data. Further, we develop a theory of transfer learning for a simplified scenario and confirm that the derived generalization bound is consistent with our empirical findings.