 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnti Mode-Collapse in Mean-Field Transformer via Auxiliary Variables
May 28, 2026We use a mean-field-based transformer model to theoretically investigate how auxiliary variables, such as positional encoding, prevent mode collapse of self-attention mechanisms. The use of mean-field transformers to analyze the properties of self-attention mechanisms has garnered significant attention in recent years due to their ability to comprehensively analyze token interactions. However, analysis of this simple model suggests that mode collapse, where token distributions degenerate to a single point, occurs during long inferences (i.e., many layers), indicating a discrepancy with reality. This study investigates this mean-field transformer model and demonstrates that the introduction of auxiliary variables, such as positional encoding, acts as a counterforce against theoretical mode collapse. Specifically, we show that in the theoretical scheme, the energy-maximizing distribution does not degenerate to a single point; instead, it is characterized by a pushforward of the auxiliary variable distribution, thereby avoiding concentration in the Dirac measure. Our main examples are the positional encoding and the fixed prompt insertion treated as a parallel auxiliary-variable mechanism. Furthermore, we demonstrate that positional encoding and prompt insertion possess universality of representation in the limit, meaning that the limit distribution of inference can exactly represent a wide class of distributions. We also analyze several key properties of positional encoding and metastability, and validate our theoretical results through mathematical experiments.
C-voting: Confidence-Based Test-Time Voting without Explicit Energy Functions
Apr 15, 2026Neural network models with latent recurrent processing, where identical layers are recursively applied to the latent state, have gained attention as promising models for performing reasoning tasks. A strength of such models is that they enable test-time scaling, where the models can enhance their performance in the test phase without additional training. Models such as the Hierarchical Reasoning Model (HRM) and Artificial Kuramoto Oscillatory Neurons (AKOrN) can facilitate deeper reasoning by increasing the number of recurrent steps, thereby enabling the completion of challenging tasks, including Sudoku, Maze solving, and AGI benchmarks. In this work, we introduce confidence-based voting (C-voting), a test-time scaling strategy designed for recurrent models with multiple latent candidate trajectories. Initializing the latent state with multiple candidates using random variables, C-voting selects the one maximizing the average of top-1 probabilities of the predictions, reflecting the model's confidence. Additionally, it yields 4.9% higher accuracy on Sudoku-hard than the energy-based voting strategy, which is specific to models with explicit energy functions. An essential advantage of C-voting is its applicability: it can be applied to recurrent models without requiring an explicit energy function. Finally, we introduce a simple attention-based recurrent model with randomized initial values named ItrSA++, and demonstrate that when combined with C-voting, it outperforms HRM on Sudoku-extreme (95.2% vs. 55.0%) and Maze (78.6% vs. 74.5%) tasks.
Thinking While Listening: Fast-Slow Recurrence for Long-Horizon Sequential Modeling
Apr 02, 2026We extend the recent latent recurrent modeling to sequential input streams. By interleaving fast, recurrent latent updates with self-organizational ability between slow observation updates, our method facilitates the learning of stable internal structures that evolve alongside the input. This mechanism allows the model to maintain coherent and clustered representations over long horizons, improving out-of-distribution generalization in reinforcement learning and algorithmic tasks compared to sequential baselines such as LSTM, state space models, and Transformer variants.
Robust Sim-to-Real Cloth Untangling through Reduced-Resolution Observations via Adaptive Force-Difference Quantization
Mar 14, 2026Robotic cloth untangling requires progressively disentangling fabric by adapting pulling actions to changing contact and tension conditions. Because large-scale real-world training is impractical due to cloth damage and hardware wear, sim-to-real policy transfer is a promising solution. However, cloth manipulation is highly sensitive to interaction dynamics, and policies that depend on precise force magnitudes often fail after transfer because similar force responses cannot be reproduced due to the reality gap. We observe that untangling is largely characterized by qualitative tension transitions rather than exact force values. This indicates that directly minimizing the sim-to-real gap in raw force measurements does not necessarily align with the task structure. We therefore hypothesize that emphasizing coarse force-change patterns while suppressing fine environment-dependent variations can improve robustness of sim-to-real transfer. Based on this insight, we propose Adaptive Force-Difference Quantization (ADQ), which reduces observation resolution by representing force inputs as discretized temporal differences and learning state-dependent quantization thresholds adaptively. This representation mitigates overfitting to environment-specific force characteristics and facilitates direct sim-to-real transfer. Experiments in both simulation and real-world cloth untangling demonstrate that ADQ achieves higher success rates and exhibits greater robustness in sim-to-real transfer than policies using raw force inputs. Supplementary video is available at https://youtu.be/ZeoBs-t0AWc
JFlow: Model-Independent Spherical Jeans Analysis using Equivariant Continuous Normalizing Flows
May 01, 2025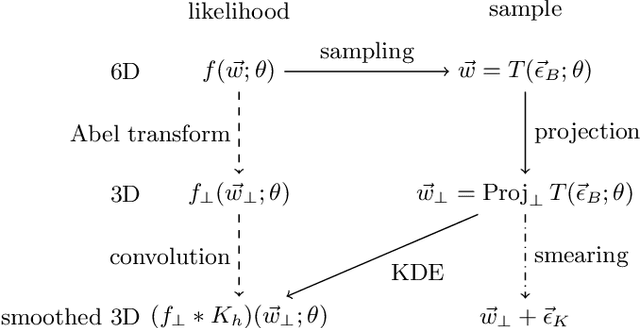



The kinematics of stars in dwarf spheroidal galaxies have been studied to understand the structure of dark matter halos. However, the kinematic information of these stars is often limited to celestial positions and line-of-sight velocities, making full phase space analysis challenging. Conventional methods rely on projected analytic phase space density models with several parameters and infer dark matter halo structures by solving the spherical Jeans equation. In this paper, we introduce an unsupervised machine learning method for solving the spherical Jeans equation in a model-independent way as a first step toward model-independent analysis of dwarf spheroidal galaxies. Using equivariant continuous normalizing flows, we demonstrate that spherically symmetric stellar phase space densities and velocity dispersions can be estimated without model assumptions. As a proof of concept, we apply our method to Gaia challenge datasets for spherical models and measure dark matter mass densities given velocity anisotropy profiles. Our method can identify halo structures accurately, even with a small number of tracer stars.
When Does Metadata Conditioning (NOT) Work for Language Model Pre-Training? A Study with Context-Free Grammars
Apr 24, 2025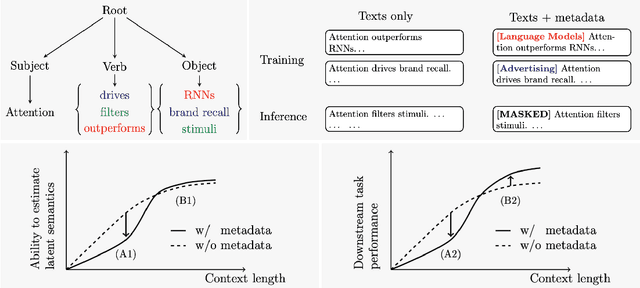
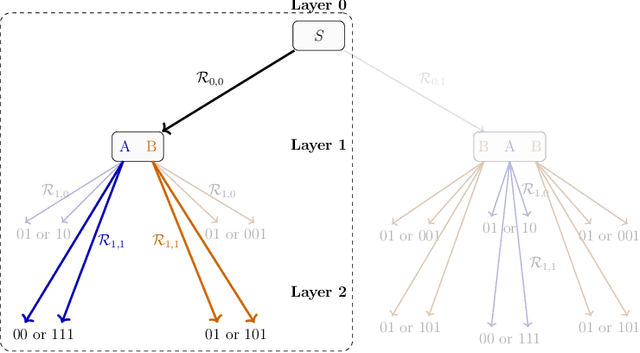
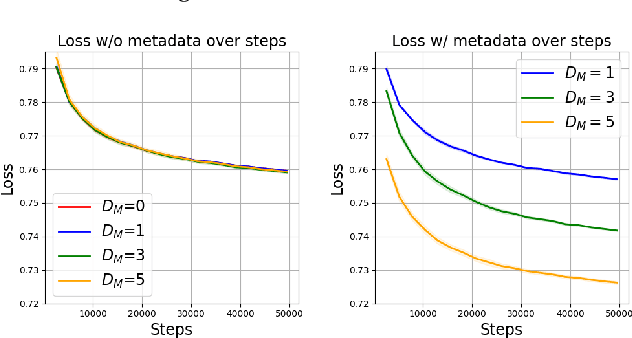

The ability to acquire latent semantics is one of the key properties that determines the performance of language models. One convenient approach to invoke this ability is to prepend metadata (e.g. URLs, domains, and styles) at the beginning of texts in the pre-training data, making it easier for the model to access latent semantics before observing the entire text. Previous studies have reported that this technique actually improves the performance of trained models in downstream tasks; however, this improvement has been observed only in specific downstream tasks, without consistent enhancement in average next-token prediction loss. To understand this phenomenon, we closely investigate how prepending metadata during pre-training affects model performance by examining its behavior using artificial data. Interestingly, we found that this approach produces both positive and negative effects on the downstream tasks. We demonstrate that the effectiveness of the approach depends on whether latent semantics can be inferred from the downstream task's prompt. Specifically, through investigations using data generated by probabilistic context-free grammars, we show that training with metadata helps improve model's performance when the given context is long enough to infer the latent semantics. In contrast, the technique negatively impacts performance when the context lacks the necessary information to make an accurate posterior inference.
Simultaneous Learning of Optimal Transports for Training All-to-All Flow-Based Condition Transfer Model
Apr 04, 2025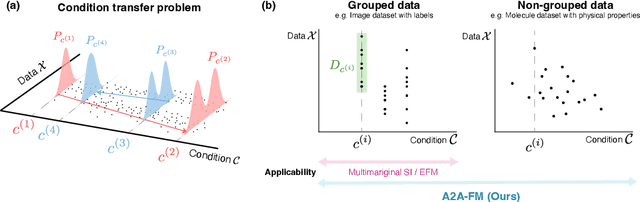

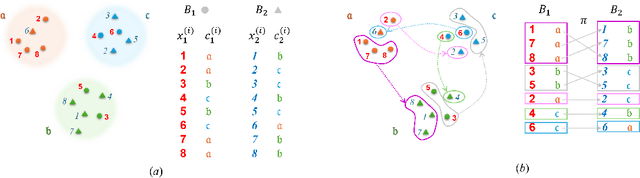

In this paper, we propose a flow-based method for learning all-to-all transfer maps among conditional distributions, approximating pairwise optimal transport. The proposed method addresses the challenge of handling continuous conditions, which often involve a large set of conditions with sparse empirical observations per condition. We introduce a novel cost function that enables simultaneous learning of optimal transports for all pairs of conditional distributions. Our method is supported by a theoretical guarantee that, in the limit, it converges to pairwise optimal transports among infinite pairs of conditional distributions. The learned transport maps are subsequently used to couple data points in conditional flow matching. We demonstrate the effectiveness of this method on synthetic and benchmark datasets, as well as on chemical datasets where continuous physical properties are defined as conditions.
Inter-environmental world modeling for continuous and compositional dynamics
Mar 13, 2025



Various world model frameworks are being developed today based on autoregressive frameworks that rely on discrete representations of actions and observations, and these frameworks are succeeding in constructing interactive generative models for the target environment of interest. Meanwhile, humans demonstrate remarkable generalization abilities to combine experiences in multiple environments to mentally simulate and learn to control agents in diverse environments. Inspired by this human capability, we introduce World modeling through Lie Action (WLA), an unsupervised framework that learns continuous latent action representations to simulate across environments. WLA learns a control interface with high controllability and predictive ability by simultaneously modeling the dynamics of multiple environments using Lie group theory and object-centric autoencoder. On synthetic benchmark and real-world datasets, we demonstrate that WLA can be trained using only video frames and, with minimal or no action labels, can quickly adapt to new environments with novel action sets.
Extended Flow Matching: a Method of Conditional Generation with Generalized Continuity Equation
Mar 03, 2024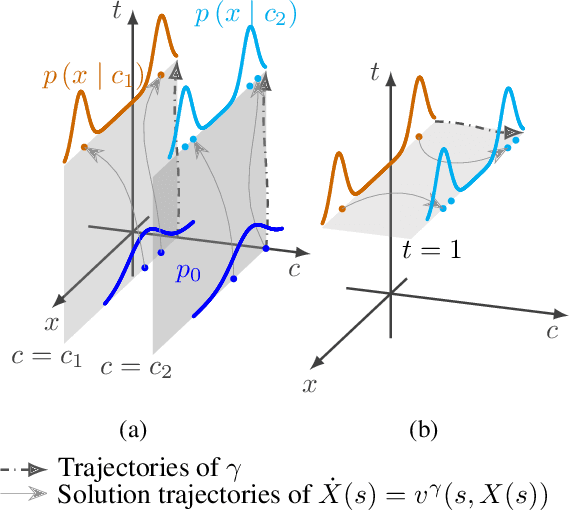
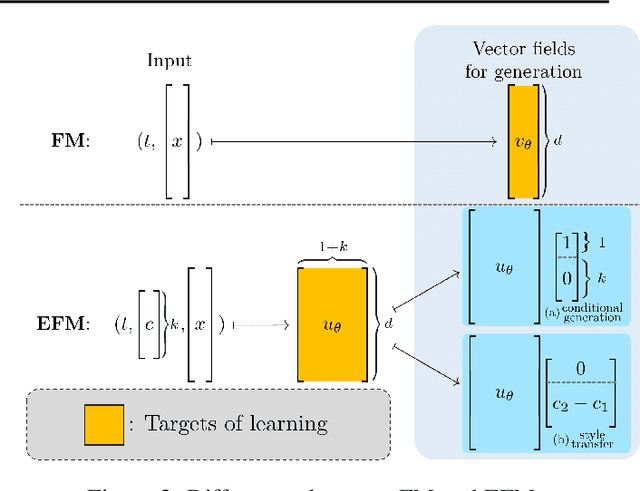
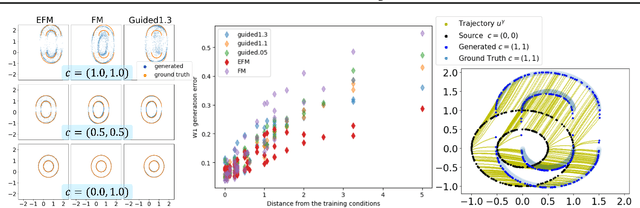
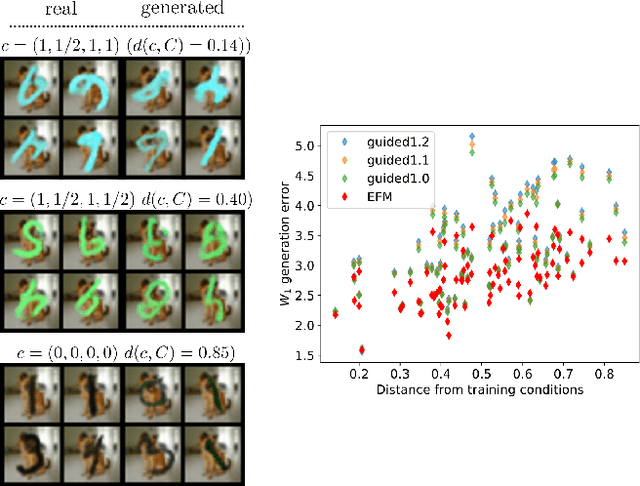
The task of conditional generation is one of the most important applications of generative models, and numerous methods have been developed to date based on the celebrated diffusion models, with the guidance-based classifier-free method taking the lead. However, the theory of the guidance-based method not only requires the user to fine-tune the "guidance strength," but its target vector field does not necessarily correspond to the conditional distribution used in training. In this paper, we develop the theory of conditional generation based on Flow Matching, a current strong contender of diffusion methods. Motivated by the interpretation of a probability path as a distribution on path space, we establish a novel theory of flow-based generation of conditional distribution by employing the mathematical framework of generalized continuity equation instead of the continuity equation in flow matching. This theory naturally derives a method that aims to match the matrix field as opposed to the vector field. Our framework ensures the continuity of the generated conditional distribution through the existence of flow between conditional distributions. We will present our theory through experiments and mathematical results.
CFTM: Continuous time fractional topic model
Feb 07, 2024In this paper, we propose the Continuous Time Fractional Topic Model (cFTM), a new method for dynamic topic modeling. This approach incorporates fractional Brownian motion~(fBm) to effectively identify positive or negative correlations in topic and word distribution over time, revealing long-term dependency or roughness. Our theoretical analysis shows that the cFTM can capture these long-term dependency or roughness in both topic and word distributions, mirroring the main characteristics of fBm. Moreover, we prove that the parameter estimation process for the cFTM is on par with that of LDA, traditional topic models. To demonstrate the cFTM's property, we conduct empirical study using economic news articles. The results from these tests support the model's ability to identify and track long-term dependency or roughness in topics over time.