 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpontaneous symmetry breaking and Goldstone modes for deep information propagation
May 14, 2026In physical systems, whenever a continuous symmetry is spontaneously broken, the system possesses excitations called Goldstone modes, which allow coherent information propagation over long distances and times. In this work, we study deep neural networks whose internal layers are equivariant under a continuous symmetry and may therefore support analogous Goldstone-like degrees of freedom. We demonstrate, both analytically and empirically, that these degrees of freedom enable coherent signal propagation across depth and recurrent iterations, providing a mechanism for stable information flow without relying on architectural stabilizers such as residual connections or normalization. In feedforward networks, this results in improved trainability and representational diversity across layers. In recurrent settings, we demonstrate the same mechanism is valuable for long-term memory by propagating information over recurrent iterations, thereby improving performance of RNNs and GRUs on long-sequence modeling tasks.
Thinking While Listening: Fast-Slow Recurrence for Long-Horizon Sequential Modeling
Apr 02, 2026We extend the recent latent recurrent modeling to sequential input streams. By interleaving fast, recurrent latent updates with self-organizational ability between slow observation updates, our method facilitates the learning of stable internal structures that evolve alongside the input. This mechanism allows the model to maintain coherent and clustered representations over long horizons, improving out-of-distribution generalization in reinforcement learning and algorithmic tasks compared to sequential baselines such as LSTM, state space models, and Transformer variants.
Kuramoto Orientation Diffusion Models
Sep 18, 2025Orientation-rich images, such as fingerprints and textures, often exhibit coherent angular directional patterns that are challenging to model using standard generative approaches based on isotropic Euclidean diffusion. Motivated by the role of phase synchronization in biological systems, we propose a score-based generative model built on periodic domains by leveraging stochastic Kuramoto dynamics in the diffusion process. In neural and physical systems, Kuramoto models capture synchronization phenomena across coupled oscillators -- a behavior that we re-purpose here as an inductive bias for structured image generation. In our framework, the forward process performs \textit{synchronization} among phase variables through globally or locally coupled oscillator interactions and attraction to a global reference phase, gradually collapsing the data into a low-entropy von Mises distribution. The reverse process then performs \textit{desynchronization}, generating diverse patterns by reversing the dynamics with a learned score function. This approach enables structured destruction during forward diffusion and a hierarchical generation process that progressively refines global coherence into fine-scale details. We implement wrapped Gaussian transition kernels and periodicity-aware networks to account for the circular geometry. Our method achieves competitive results on general image benchmarks and significantly improves generation quality on orientation-dense datasets like fingerprints and textures. Ultimately, this work demonstrates the promise of biologically inspired synchronization dynamics as structured priors in generative modeling.
Artificial Kuramoto Oscillatory Neurons
Oct 17, 2024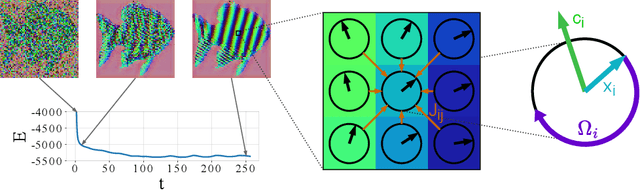
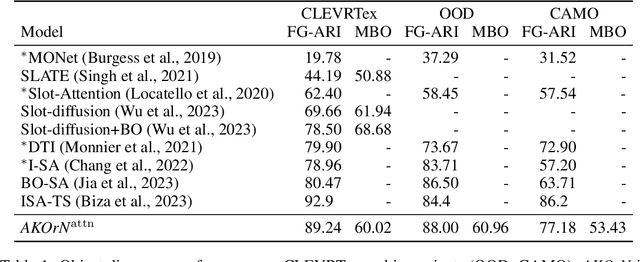
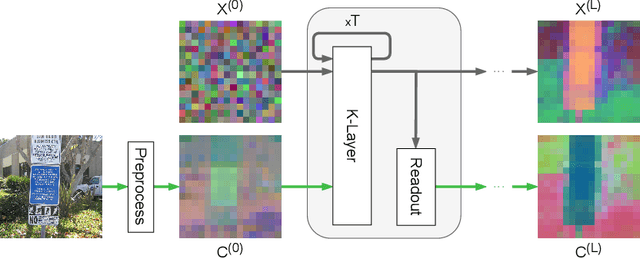
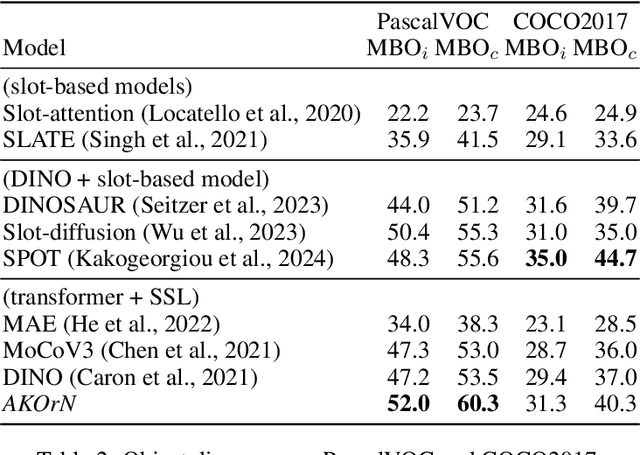
It has long been known in both neuroscience and AI that ``binding'' between neurons leads to a form of competitive learning where representations are compressed in order to represent more abstract concepts in deeper layers of the network. More recently, it was also hypothesized that dynamic (spatiotemporal) representations play an important role in both neuroscience and AI. Building on these ideas, we introduce Artificial Kuramoto Oscillatory Neurons (AKOrN) as a dynamical alternative to threshold units, which can be combined with arbitrary connectivity designs such as fully connected, convolutional, or attentive mechanisms. Our generalized Kuramoto updates bind neurons together through their synchronization dynamics. We show that this idea provides performance improvements across a wide spectrum of tasks such as unsupervised object discovery, adversarial robustness, calibrated uncertainty quantification, and reasoning. We believe that these empirical results show the importance of rethinking our assumptions at the most basic neuronal level of neural representation, and in particular show the importance of dynamical representations.
GTA: A Geometry-Aware Attention Mechanism for Multi-View Transformers
Oct 16, 2023As transformers are equivariant to the permutation of input tokens, encoding the positional information of tokens is necessary for many tasks. However, since existing positional encoding schemes have been initially designed for NLP tasks, their suitability for vision tasks, which typically exhibit different structural properties in their data, is questionable. We argue that existing positional encoding schemes are suboptimal for 3D vision tasks, as they do not respect their underlying 3D geometric structure. Based on this hypothesis, we propose a geometry-aware attention mechanism that encodes the geometric structure of tokens as relative transformation determined by the geometric relationship between queries and key-value pairs. By evaluating on multiple novel view synthesis (NVS) datasets in the sparse wide-baseline multi-view setting, we show that our attention, called Geometric Transform Attention (GTA), improves learning efficiency and performance of state-of-the-art transformer-based NVS models without any additional learned parameters and only minor computational overhead.
Neural Fourier Transform: A General Approach to Equivariant Representation Learning
May 29, 2023
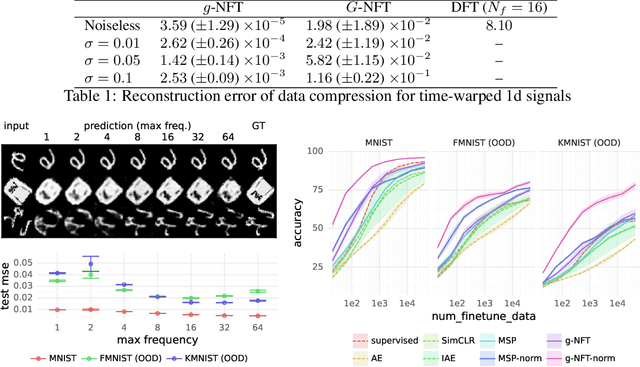
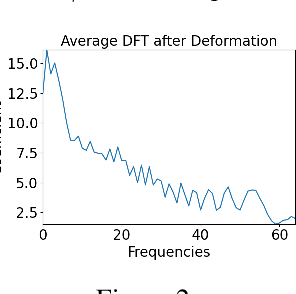

Symmetry learning has proven to be an effective approach for extracting the hidden structure of data, with the concept of equivariance relation playing the central role. However, most of the current studies are built on architectural theory and corresponding assumptions on the form of data. We propose Neural Fourier Transform (NFT), a general framework of learning the latent linear action of the group without assuming explicit knowledge of how the group acts on data. We present the theoretical foundations of NFT and show that the existence of a linear equivariant feature, which has been assumed ubiquitously in equivariance learning, is equivalent to the existence of a group invariant kernel on the dataspace. We also provide experimental results to demonstrate the application of NFT in typical scenarios with varying levels of knowledge about the acting group.
Invariance-adapted decomposition and Lasso-type contrastive learning
Oct 13, 2022

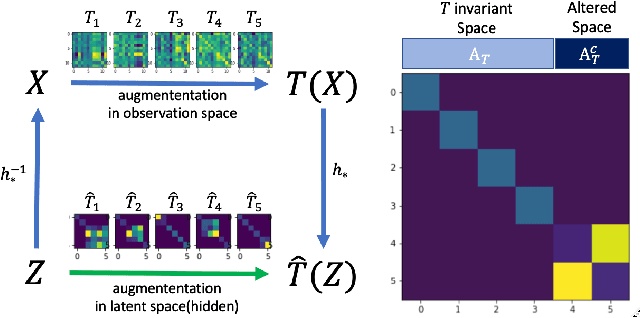

Recent years have witnessed the effectiveness of contrastive learning in obtaining the representation of dataset that is useful in interpretation and downstream tasks. However, the mechanism that describes this effectiveness have not been thoroughly analyzed, and many studies have been conducted to investigate the data structures captured by contrastive learning. In particular, the recent study of \citet{content_isolate} has shown that contrastive learning is capable of decomposing the data space into the space that is invariant to all augmentations and its complement. In this paper, we introduce the notion of invariance-adapted latent space that decomposes the data space into the intersections of the invariant spaces of each augmentation and their complements. This decomposition generalizes the one introduced in \citet{content_isolate}, and describes a structure that is analogous to the frequencies in the harmonic analysis of a group. We experimentally show that contrastive learning with lasso-type metric can be used to find an invariance-adapted latent space, thereby suggesting a new potential for the contrastive learning. We also investigate when such a latent space can be identified up to mixings within each component.
Unsupervised Learning of Equivariant Structure from Sequences
Oct 12, 2022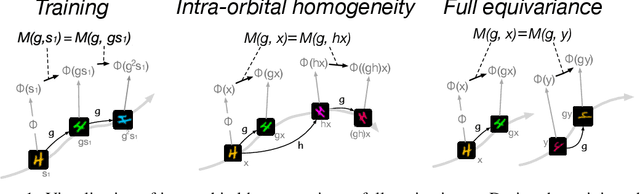

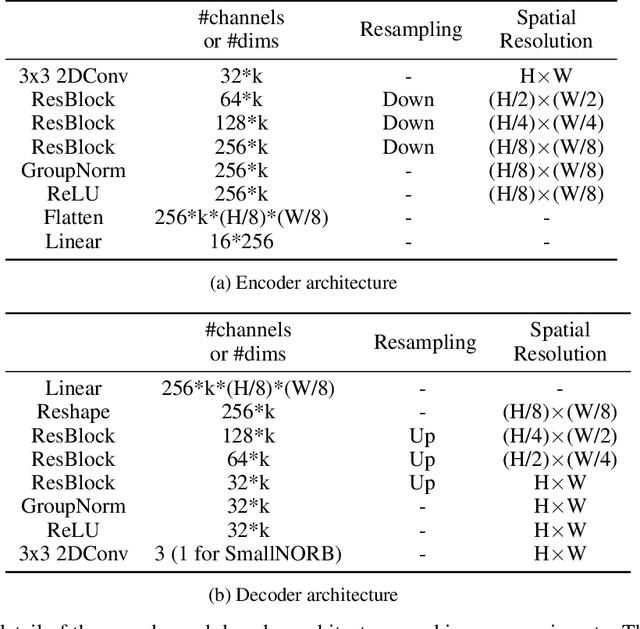
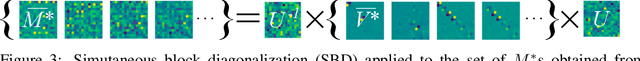
In this study, we present meta-sequential prediction (MSP), an unsupervised framework to learn the symmetry from the time sequence of length at least three. Our method leverages the stationary property (e.g. constant velocity, constant acceleration) of the time sequence to learn the underlying equivariant structure of the dataset by simply training the encoder-decoder model to be able to predict the future observations. We will demonstrate that, with our framework, the hidden disentangled structure of the dataset naturally emerges as a by-product by applying simultaneous block-diagonalization to the transition operators in the latent space, the procedure which is commonly used in representation theory to decompose the feature-space based on the type of response to group actions. We will showcase our method from both empirical and theoretical perspectives. Our result suggests that finding a simple structured relation and learning a model with extrapolation capability are two sides of the same coin. The code is available at https://github.com/takerum/meta_sequential_prediction.
Contrastive Representation Learning with Trainable Augmentation Channel
Nov 15, 2021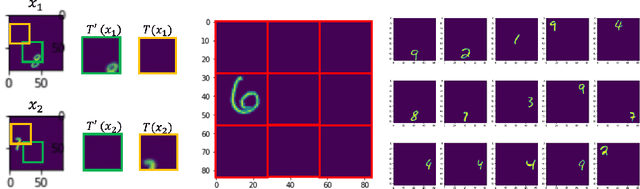

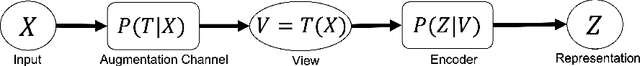

In contrastive representation learning, data representation is trained so that it can classify the image instances even when the images are altered by augmentations. However, depending on the datasets, some augmentations can damage the information of the images beyond recognition, and such augmentations can result in collapsed representations. We present a partial solution to this problem by formalizing a stochastic encoding process in which there exist a tug-of-war between the data corruption introduced by the augmentations and the information preserved by the encoder. We show that, with the infoMax objective based on this framework, we can learn a data-dependent distribution of augmentations to avoid the collapse of the representation.
Robustness to Adversarial Perturbations in Learning from Incomplete Data
May 24, 2019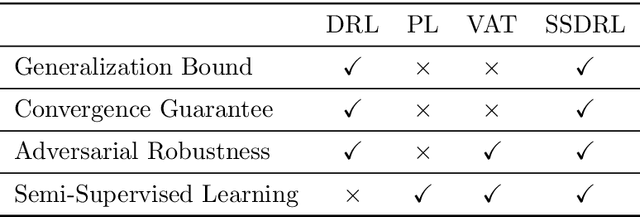
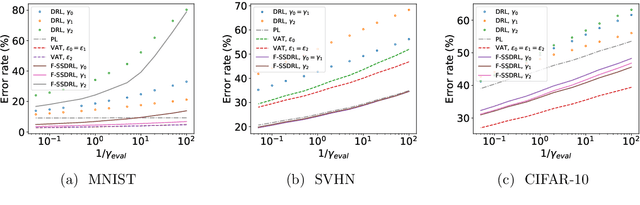

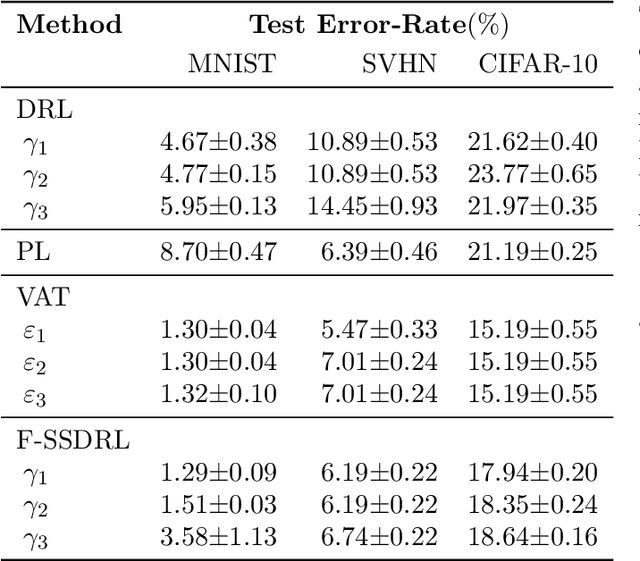
What is the role of unlabeled data in an inference problem, when the presumed underlying distribution is adversarially perturbed? To provide a concrete answer to this question, this paper unifies two major learning frameworks: Semi-Supervised Learning (SSL) and Distributionally Robust Learning (DRL). We develop a generalization theory for our framework based on a number of novel complexity measures, such as an adversarial extension of Rademacher complexity and its semi-supervised analogue. Moreover, our analysis is able to quantify the role of unlabeled data in the generalization under a more general condition compared to the existing theoretical works in SSL. Based on our framework, we also present a hybrid of DRL and EM algorithms that has a guaranteed convergence rate. When implemented with deep neural networks, our method shows a comparable performance to those of the state-of-the-art on a number of real-world benchmark datasets.