 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArtificial Kuramoto Oscillatory Neurons
Oct 17, 2024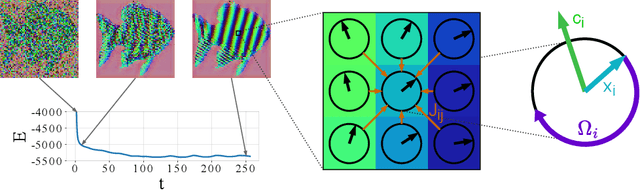
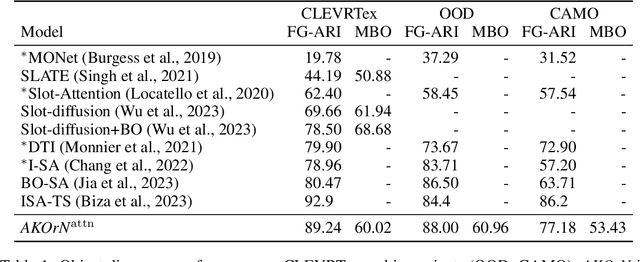
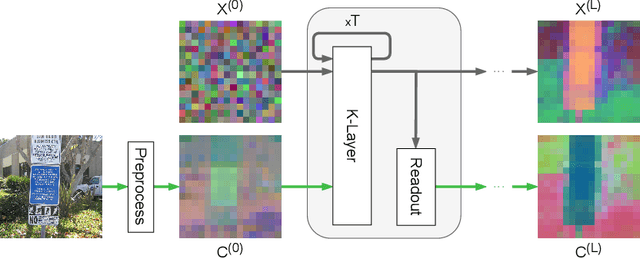
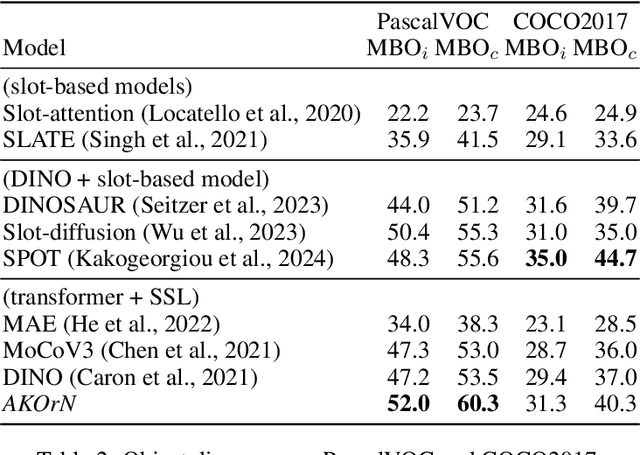
It has long been known in both neuroscience and AI that ``binding'' between neurons leads to a form of competitive learning where representations are compressed in order to represent more abstract concepts in deeper layers of the network. More recently, it was also hypothesized that dynamic (spatiotemporal) representations play an important role in both neuroscience and AI. Building on these ideas, we introduce Artificial Kuramoto Oscillatory Neurons (AKOrN) as a dynamical alternative to threshold units, which can be combined with arbitrary connectivity designs such as fully connected, convolutional, or attentive mechanisms. Our generalized Kuramoto updates bind neurons together through their synchronization dynamics. We show that this idea provides performance improvements across a wide spectrum of tasks such as unsupervised object discovery, adversarial robustness, calibrated uncertainty quantification, and reasoning. We believe that these empirical results show the importance of rethinking our assumptions at the most basic neuronal level of neural representation, and in particular show the importance of dynamical representations.
Binding Dynamics in Rotating Features
Feb 08, 2024In human cognition, the binding problem describes the open question of how the brain flexibly integrates diverse information into cohesive object representations. Analogously, in machine learning, there is a pursuit for models capable of strong generalization and reasoning by learning object-centric representations in an unsupervised manner. Drawing from neuroscientific theories, Rotating Features learn such representations by introducing vector-valued features that encapsulate object characteristics in their magnitudes and object affiliation in their orientations. The "$\chi$-binding" mechanism, embedded in every layer of the architecture, has been shown to be crucial, but remains poorly understood. In this paper, we propose an alternative "cosine binding" mechanism, which explicitly computes the alignment between features and adjusts weights accordingly, and we show that it achieves equivalent performance. This allows us to draw direct connections to self-attention and biological neural processes, and to shed light on the fundamental dynamics for object-centric representations to emerge in Rotating Features.
Image segmentation with traveling waves in an exactly solvable recurrent neural network
Nov 28, 2023We study image segmentation using spatiotemporal dynamics in a recurrent neural network where the state of each unit is given by a complex number. We show that this network generates sophisticated spatiotemporal dynamics that can effectively divide an image into groups according to a scene's structural characteristics. Using an exact solution of the recurrent network's dynamics, we present a precise description of the mechanism underlying object segmentation in this network, providing a clear mathematical interpretation of how the network performs this task. We then demonstrate a simple algorithm for object segmentation that generalizes across inputs ranging from simple geometric objects in grayscale images to natural images. Object segmentation across all images is accomplished with one recurrent neural network that has a single, fixed set of weights. This demonstrates the expressive potential of recurrent neural networks when constructed using a mathematical approach that brings together their structure, dynamics, and computation.
BISCUIT: Causal Representation Learning from Binary Interactions
Jun 16, 2023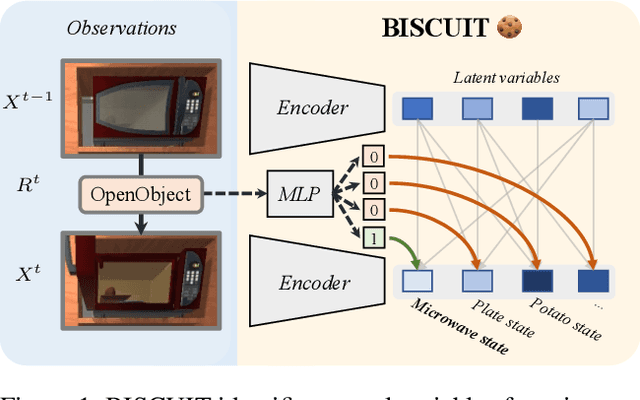



Identifying the causal variables of an environment and how to intervene on them is of core value in applications such as robotics and embodied AI. While an agent can commonly interact with the environment and may implicitly perturb the behavior of some of these causal variables, often the targets it affects remain unknown. In this paper, we show that causal variables can still be identified for many common setups, e.g., additive Gaussian noise models, if the agent's interactions with a causal variable can be described by an unknown binary variable. This happens when each causal variable has two different mechanisms, e.g., an observational and an interventional one. Using this identifiability result, we propose BISCUIT, a method for simultaneously learning causal variables and their corresponding binary interaction variables. On three robotic-inspired datasets, BISCUIT accurately identifies causal variables and can even be scaled to complex, realistic environments for embodied AI.
Rotating Features for Object Discovery
Jun 01, 2023
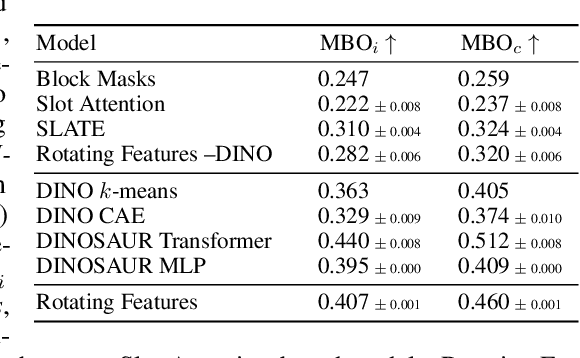

The binding problem in human cognition, concerning how the brain represents and connects objects within a fixed network of neural connections, remains a subject of intense debate. Most machine learning efforts addressing this issue in an unsupervised setting have focused on slot-based methods, which may be limiting due to their discrete nature and difficulty to express uncertainty. Recently, the Complex AutoEncoder was proposed as an alternative that learns continuous and distributed object-centric representations. However, it is only applicable to simple toy data. In this paper, we present Rotating Features, a generalization of complex-valued features to higher dimensions, and a new evaluation procedure for extracting objects from distributed representations. Additionally, we show the applicability of our approach to pre-trained features. Together, these advancements enable us to scale distributed object-centric representations from simple toy to real-world data. We believe this work advances a new paradigm for addressing the binding problem in machine learning and has the potential to inspire further innovation in the field.
iCITRIS: Causal Representation Learning for Instantaneous Temporal Effects
Jun 13, 2022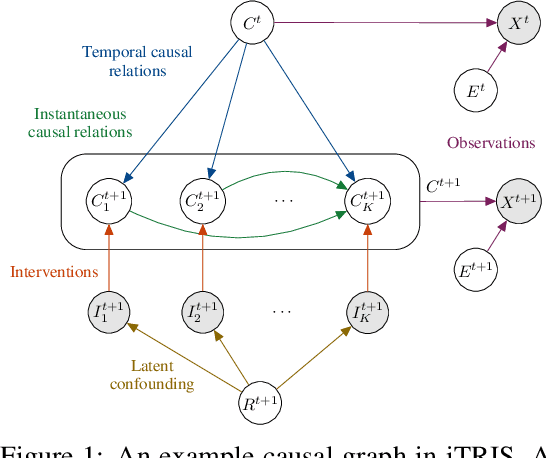

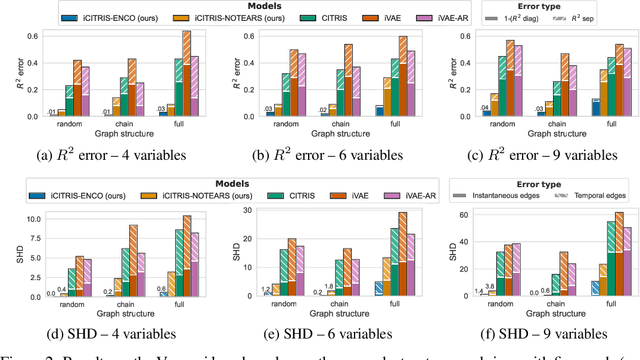

Causal representation learning is the task of identifying the underlying causal variables and their relations from high-dimensional observations, such as images. Recent work has shown that one can reconstruct the causal variables from temporal sequences of observations under the assumption that there are no instantaneous causal relations between them. In practical applications, however, our measurement or frame rate might be slower than many of the causal effects. This effectively creates "instantaneous" effects and invalidates previous identifiability results. To address this issue, we propose iCITRIS, a causal representation learning method that can handle instantaneous effects in temporal sequences when given perfect interventions with known intervention targets. iCITRIS identifies the causal factors from temporal observations, while simultaneously using a differentiable causal discovery method to learn their causal graph. In experiments on three video datasets, iCITRIS accurately identifies the causal factors and their causal graph.
Complex-Valued Autoencoders for Object Discovery
Apr 05, 2022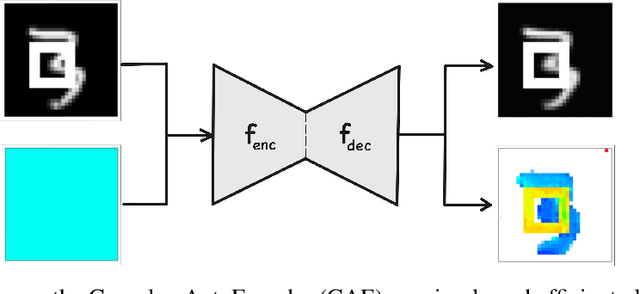
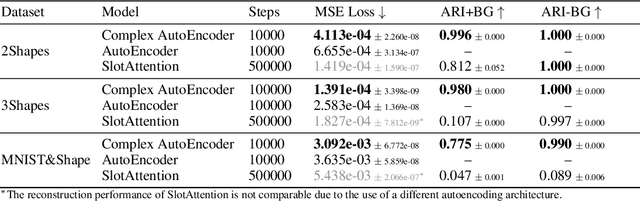

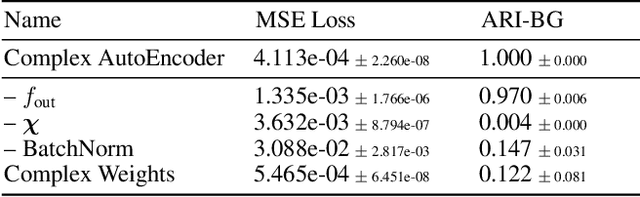
Object-centric representations form the basis of human perception and enable us to reason about the world and to systematically generalize to new settings. Currently, most machine learning work on unsupervised object discovery focuses on slot-based approaches, which explicitly separate the latent representations of individual objects. While the result is easily interpretable, it usually requires the design of involved architectures. In contrast to this, we propose a distributed approach to object-centric representations: the Complex AutoEncoder. Following a coding scheme theorized to underlie object representations in biological neurons, its complex-valued activations represent two messages: their magnitudes express the presence of a feature, while the relative phase differences between neurons express which features should be bound together to create joint object representations. We show that this simple and efficient approach achieves better reconstruction performance than an equivalent real-valued autoencoder on simple multi-object datasets. Additionally, we show that it achieves competitive unsupervised object discovery performance to a SlotAttention model on two datasets, and manages to disentangle objects in a third dataset where SlotAttention fails - all while being 7-70 times faster to train.
CITRIS: Causal Identifiability from Temporal Intervened Sequences
Feb 16, 2022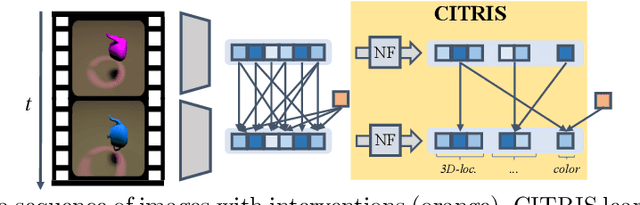



Understanding the latent causal factors of a dynamical system from visual observations is a crucial step towards agents reasoning in complex environments. In this paper, we propose CITRIS, a variational autoencoder framework that learns causal representations from temporal sequences of images in which underlying causal factors have possibly been intervened upon. In contrast to the recent literature, CITRIS exploits temporality and observing intervention targets to identify scalar and multidimensional causal factors, such as 3D rotation angles. Furthermore, by introducing a normalizing flow, CITRIS can be easily extended to leverage and disentangle representations obtained by already pretrained autoencoders. Extending previous results on scalar causal factors, we prove identifiability in a more general setting, in which only some components of a causal factor are affected by interventions. In experiments on 3D rendered image sequences, CITRIS outperforms previous methods on recovering the underlying causal variables. Moreover, using pretrained autoencoders, CITRIS can even generalize to unseen instantiations of causal factors, opening future research areas in sim-to-real generalization for causal representation learning.
Contrastive Predictive Coding for Anomaly Detection
Jul 16, 2021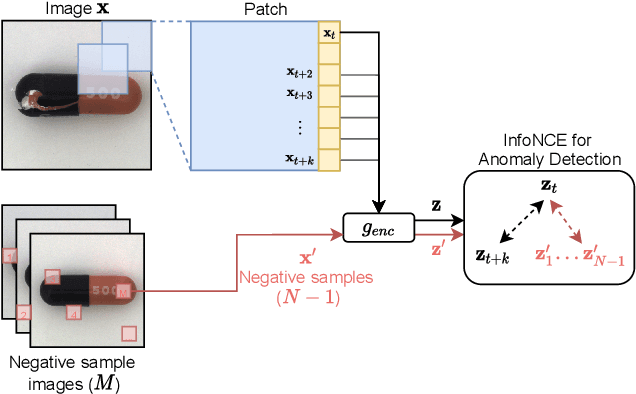
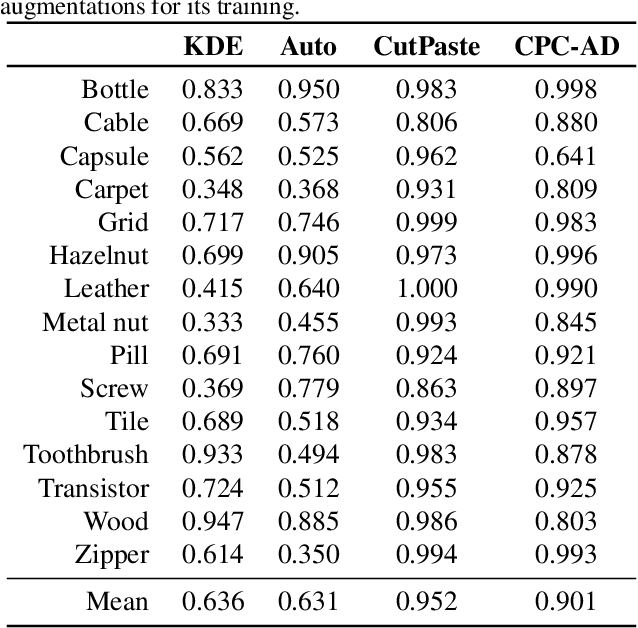

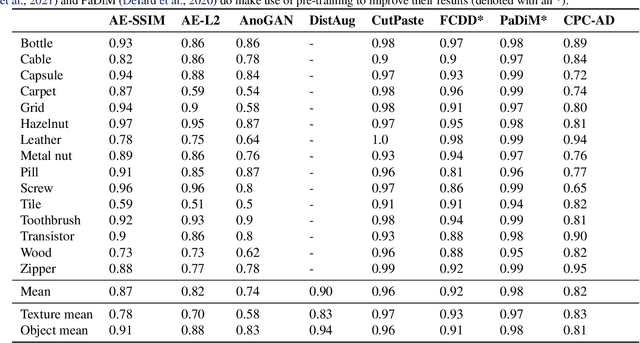
Reliable detection of anomalies is crucial when deploying machine learning models in practice, but remains challenging due to the lack of labeled data. To tackle this challenge, contrastive learning approaches are becoming increasingly popular, given the impressive results they have achieved in self-supervised representation learning settings. However, while most existing contrastive anomaly detection and segmentation approaches have been applied to images, none of them can use the contrastive losses directly for both anomaly detection and segmentation. In this paper, we close this gap by making use of the Contrastive Predictive Coding model (arXiv:1807.03748). We show that its patch-wise contrastive loss can directly be interpreted as an anomaly score, and how this allows for the creation of anomaly segmentation masks. The resulting model achieves promising results for both anomaly detection and segmentation on the challenging MVTec-AD dataset.
Learning Object-Centric Video Models by Contrasting Sets
Nov 20, 2020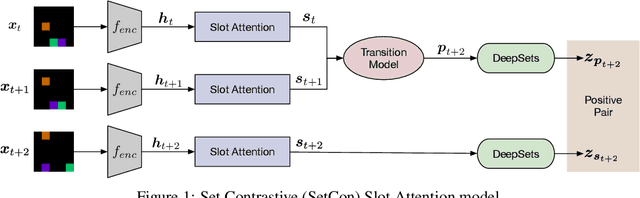
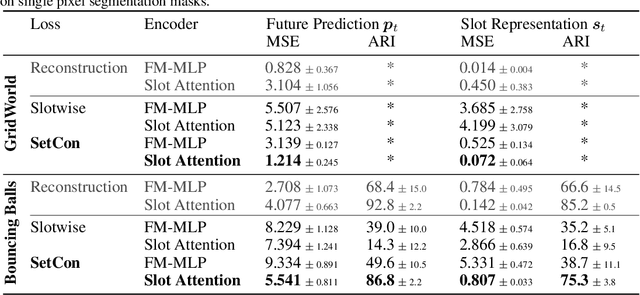
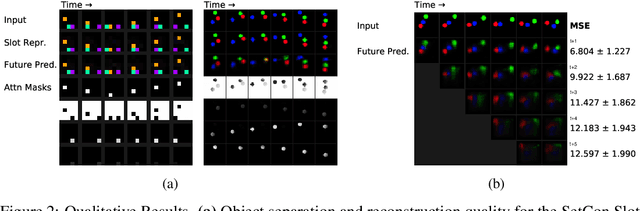
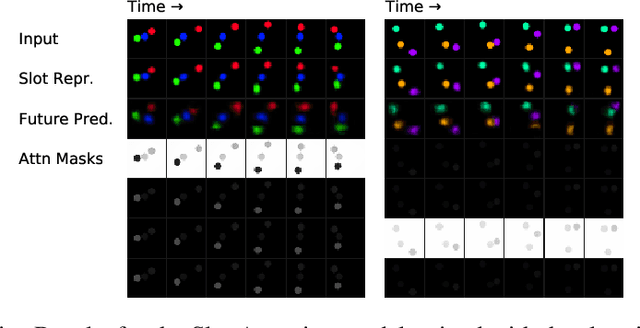
Contrastive, self-supervised learning of object representations recently emerged as an attractive alternative to reconstruction-based training. Prior approaches focus on contrasting individual object representations (slots) against one another. However, a fundamental problem with this approach is that the overall contrastive loss is the same for (i) representing a different object in each slot, as it is for (ii) (re-)representing the same object in all slots. Thus, this objective does not inherently push towards the emergence of object-centric representations in the slots. We address this problem by introducing a global, set-based contrastive loss: instead of contrasting individual slot representations against one another, we aggregate the representations and contrast the joined sets against one another. Additionally, we introduce attention-based encoders to this contrastive setup which simplifies training and provides interpretable object masks. Our results on two synthetic video datasets suggest that this approach compares favorably against previous contrastive methods in terms of reconstruction, future prediction and object separation performance.