 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAsyncPatch Diffusion: spatially-flexible image generation
Jun 05, 2026Standard diffusion models corrupt an entire sample with a single shared noise level, forcing all spatial regions to follow the same denoising trajectory. We introduce AsyncPatch Diffusion, a joint-diffusion framework that assigns distinct noise levels to different input dimensions, such as image pixels, or latent tokens. We show how this asynchronous corruption defines a valid generative process while supporting a richer family of spatially heterogeneous denoising trajectories, and prove the first valid ELBO for this process. We show that a single pretrained model can perform spatially adaptive generation, where different regions are denoised on different schedules. A key challenge is training: naive independent noise-level sampling overemphasizes highly heterogeneous configurations and underrepresents homogeneous noise levels, that are crucial during sampling. We address this with a controlled noise-level sampler that regulates both the average corruption level and its spatial variability. AsyncPatch achieves generation quality comparable to conventional diffusion on ImageNet 256 and LSUN, while being natively suited for inpainting without task-specific fine-tuning. We further introduce input guidance, which uses clean or partially corrupted regions to guide the generation of unknown regions, improving local consistency and texture matching. Finally, we demonstrate adaptive generation strategies including uncertainty-guided acceleration and autoregressive sampling.
Gemma 3 Technical Report
Mar 25, 2025We introduce Gemma 3, a multimodal addition to the Gemma family of lightweight open models, ranging in scale from 1 to 27 billion parameters. This version introduces vision understanding abilities, a wider coverage of languages and longer context - at least 128K tokens. We also change the architecture of the model to reduce the KV-cache memory that tends to explode with long context. This is achieved by increasing the ratio of local to global attention layers, and keeping the span on local attention short. The Gemma 3 models are trained with distillation and achieve superior performance to Gemma 2 for both pre-trained and instruction finetuned versions. In particular, our novel post-training recipe significantly improves the math, chat, instruction-following and multilingual abilities, making Gemma3-4B-IT competitive with Gemma2-27B-IT and Gemma3-27B-IT comparable to Gemini-1.5-Pro across benchmarks. We release all our models to the community.
Scaling 4D Representations
Dec 19, 2024



Scaling has not yet been convincingly demonstrated for pure self-supervised learning from video. However, prior work has focused evaluations on semantic-related tasks $\unicode{x2013}$ action classification, ImageNet classification, etc. In this paper we focus on evaluating self-supervised learning on non-semantic vision tasks that are more spatial (3D) and temporal (+1D = 4D), such as camera pose estimation, point and object tracking, and depth estimation. We show that by learning from very large video datasets, masked auto-encoding (MAE) with transformer video models actually scales, consistently improving performance on these 4D tasks, as model size increases from 20M all the way to the largest by far reported self-supervised video model $\unicode{x2013}$ 22B parameters. Rigorous apples-to-apples comparison with many recent image and video models demonstrates the benefits of scaling 4D representations.
Moving Off-the-Grid: Scene-Grounded Video Representations
Nov 08, 2024



Current vision models typically maintain a fixed correspondence between their representation structure and image space. Each layer comprises a set of tokens arranged "on-the-grid," which biases patches or tokens to encode information at a specific spatio(-temporal) location. In this work we present Moving Off-the-Grid (MooG), a self-supervised video representation model that offers an alternative approach, allowing tokens to move "off-the-grid" to better enable them to represent scene elements consistently, even as they move across the image plane through time. By using a combination of cross-attention and positional embeddings we disentangle the representation structure and image structure. We find that a simple self-supervised objective--next frame prediction--trained on video data, results in a set of latent tokens which bind to specific scene structures and track them as they move. We demonstrate the usefulness of MooG's learned representation both qualitatively and quantitatively by training readouts on top of the learned representation on a variety of downstream tasks. We show that MooG can provide a strong foundation for different vision tasks when compared to "on-the-grid" baselines.
Aligning Machine and Human Visual Representations across Abstraction Levels
Sep 10, 2024



Deep neural networks have achieved success across a wide range of applications, including as models of human behavior in vision tasks. However, neural network training and human learning differ in fundamental ways, and neural networks often fail to generalize as robustly as humans do, raising questions regarding the similarity of their underlying representations. What is missing for modern learning systems to exhibit more human-like behavior? We highlight a key misalignment between vision models and humans: whereas human conceptual knowledge is hierarchically organized from fine- to coarse-scale distinctions, model representations do not accurately capture all these levels of abstraction. To address this misalignment, we first train a teacher model to imitate human judgments, then transfer human-like structure from its representations into pretrained state-of-the-art vision foundation models. These human-aligned models more accurately approximate human behavior and uncertainty across a wide range of similarity tasks, including a new dataset of human judgments spanning multiple levels of semantic abstractions. They also perform better on a diverse set of machine learning tasks, increasing generalization and out-of-distribution robustness. Thus, infusing neural networks with additional human knowledge yields a best-of-both-worlds representation that is both more consistent with human cognition and more practically useful, thus paving the way toward more robust, interpretable, and human-like artificial intelligence systems.
Getting aligned on representational alignment
Nov 02, 2023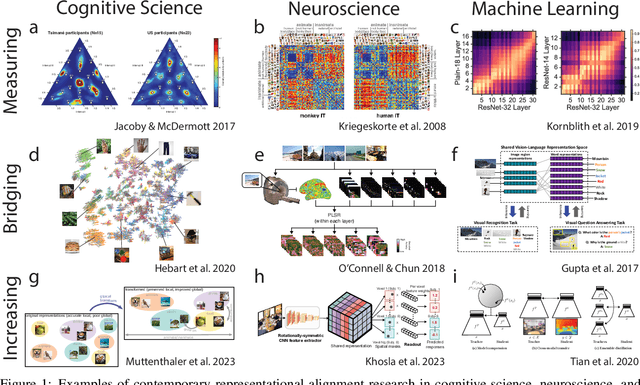
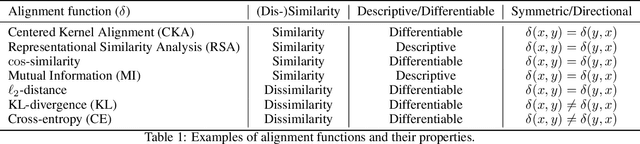
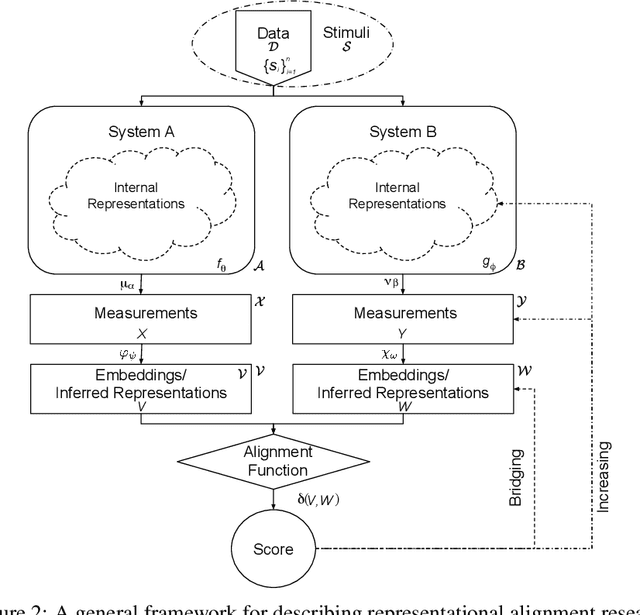
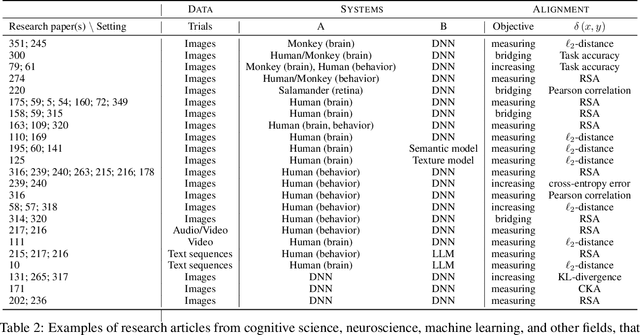
Biological and artificial information processing systems form representations that they can use to categorize, reason, plan, navigate, and make decisions. How can we measure the extent to which the representations formed by these diverse systems agree? Do similarities in representations then translate into similar behavior? How can a system's representations be modified to better match those of another system? These questions pertaining to the study of representational alignment are at the heart of some of the most active research areas in cognitive science, neuroscience, and machine learning. For example, cognitive scientists measure the representational alignment of multiple individuals to identify shared cognitive priors, neuroscientists align fMRI responses from multiple individuals into a shared representational space for group-level analyses, and ML researchers distill knowledge from teacher models into student models by increasing their alignment. Unfortunately, there is limited knowledge transfer between research communities interested in representational alignment, so progress in one field often ends up being rediscovered independently in another. Thus, greater cross-field communication would be advantageous. To improve communication between these fields, we propose a unifying framework that can serve as a common language between researchers studying representational alignment. We survey the literature from all three fields and demonstrate how prior work fits into this framework. Finally, we lay out open problems in representational alignment where progress can benefit all three of these fields. We hope that our work can catalyze cross-disciplinary collaboration and accelerate progress for all communities studying and developing information processing systems. We note that this is a working paper and encourage readers to reach out with their suggestions for future revisions.
DyST: Towards Dynamic Neural Scene Representations on Real-World Videos
Oct 09, 2023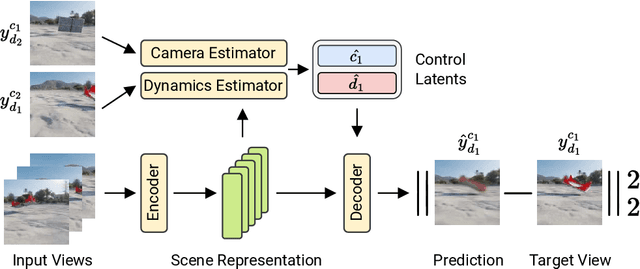
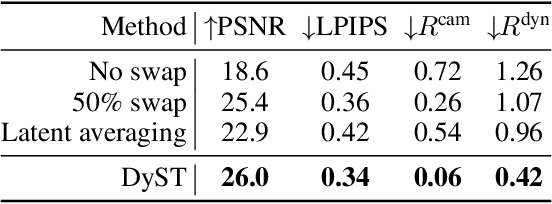


Visual understanding of the world goes beyond the semantics and flat structure of individual images. In this work, we aim to capture both the 3D structure and dynamics of real-world scenes from monocular real-world videos. Our Dynamic Scene Transformer (DyST) model leverages recent work in neural scene representation to learn a latent decomposition of monocular real-world videos into scene content, per-view scene dynamics, and camera pose. This separation is achieved through a novel co-training scheme on monocular videos and our new synthetic dataset DySO. DyST learns tangible latent representations for dynamic scenes that enable view generation with separate control over the camera and the content of the scene.
Sensitivity of Slot-Based Object-Centric Models to their Number of Slots
May 30, 2023
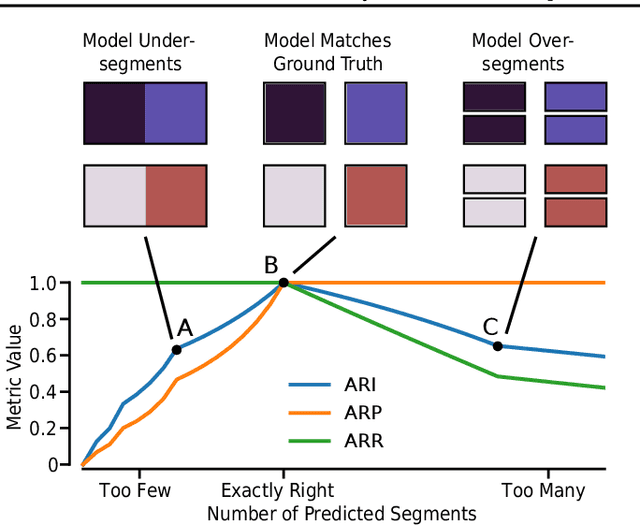
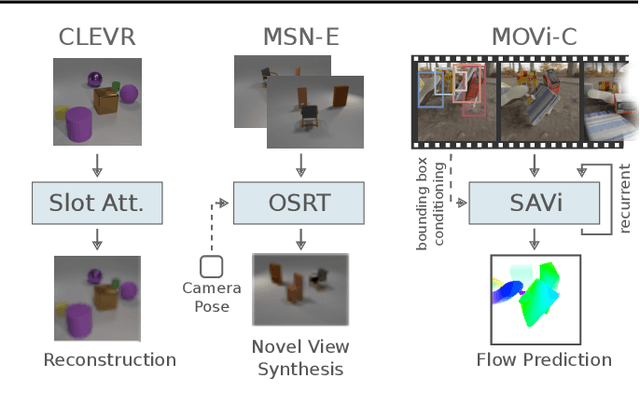
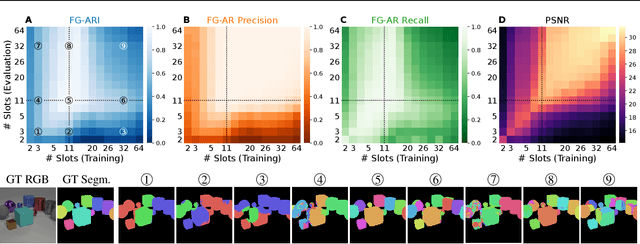
Self-supervised methods for learning object-centric representations have recently been applied successfully to various datasets. This progress is largely fueled by slot-based methods, whose ability to cluster visual scenes into meaningful objects holds great promise for compositional generalization and downstream learning. In these methods, the number of slots (clusters) $K$ is typically chosen to match the number of ground-truth objects in the data, even though this quantity is unknown in real-world settings. Indeed, the sensitivity of slot-based methods to $K$, and how this affects their learned correspondence to objects in the data has largely been ignored in the literature. In this work, we address this issue through a systematic study of slot-based methods. We propose using analogs to precision and recall based on the Adjusted Rand Index to accurately quantify model behavior over a large range of $K$. We find that, especially during training, incorrect choices of $K$ do not yield the desired object decomposition and, in fact, cause substantial oversegmentation or merging of separate objects (undersegmentation). We demonstrate that the choice of the objective function and incorporating instance-level annotations can moderately mitigate this behavior while still falling short of fully resolving this issue. Indeed, we show how this issue persists across multiple methods and datasets and stress its importance for future slot-based models.
AudioSlots: A slot-centric generative model for audio separation
May 09, 2023In a range of recent works, object-centric architectures have been shown to be suitable for unsupervised scene decomposition in the vision domain. Inspired by these methods we present AudioSlots, a slot-centric generative model for blind source separation in the audio domain. AudioSlots is built using permutation-equivariant encoder and decoder networks. The encoder network based on the Transformer architecture learns to map a mixed audio spectrogram to an unordered set of independent source embeddings. The spatial broadcast decoder network learns to generate the source spectrograms from the source embeddings. We train the model in an end-to-end manner using a permutation invariant loss function. Our results on Libri2Mix speech separation constitute a proof of concept that this approach shows promise. We discuss the results and limitations of our approach in detail, and further outline potential ways to overcome the limitations and directions for future work.
PaLM-E: An Embodied Multimodal Language Model
Mar 06, 2023

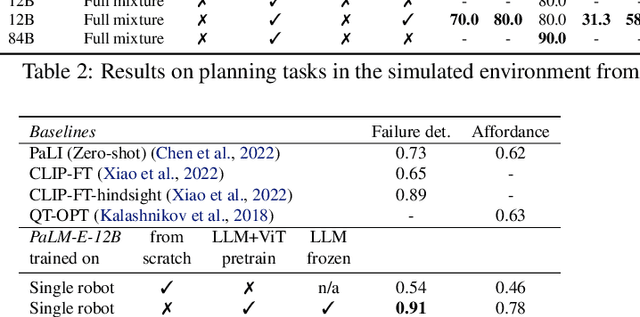

Large language models excel at a wide range of complex tasks. However, enabling general inference in the real world, e.g., for robotics problems, raises the challenge of grounding. We propose embodied language models to directly incorporate real-world continuous sensor modalities into language models and thereby establish the link between words and percepts. Input to our embodied language model are multi-modal sentences that interleave visual, continuous state estimation, and textual input encodings. We train these encodings end-to-end, in conjunction with a pre-trained large language model, for multiple embodied tasks including sequential robotic manipulation planning, visual question answering, and captioning. Our evaluations show that PaLM-E, a single large embodied multimodal model, can address a variety of embodied reasoning tasks, from a variety of observation modalities, on multiple embodiments, and further, exhibits positive transfer: the model benefits from diverse joint training across internet-scale language, vision, and visual-language domains. Our largest model, PaLM-E-562B with 562B parameters, in addition to being trained on robotics tasks, is a visual-language generalist with state-of-the-art performance on OK-VQA, and retains generalist language capabilities with increasing scale.