 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSensitivity of Slot-Based Object-Centric Models to their Number of Slots
Paper and Code
May 30, 2023
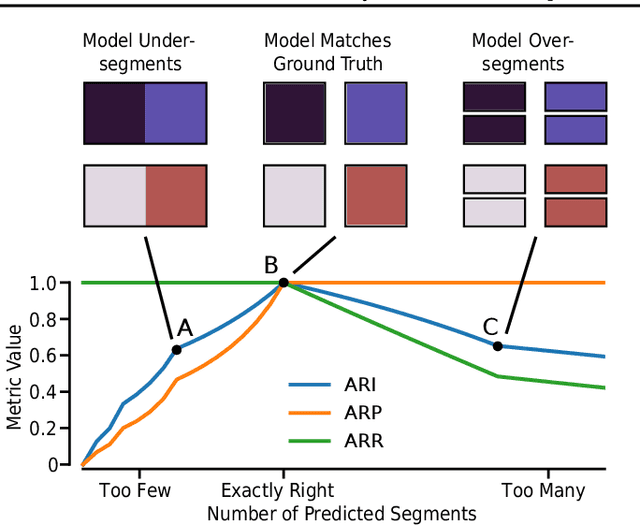
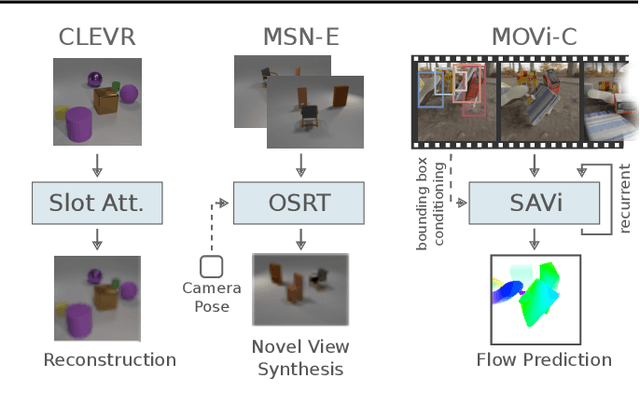
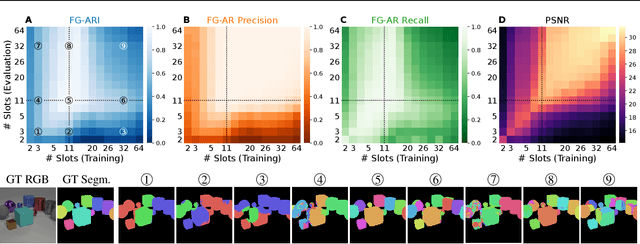
Self-supervised methods for learning object-centric representations have recently been applied successfully to various datasets. This progress is largely fueled by slot-based methods, whose ability to cluster visual scenes into meaningful objects holds great promise for compositional generalization and downstream learning. In these methods, the number of slots (clusters) $K$ is typically chosen to match the number of ground-truth objects in the data, even though this quantity is unknown in real-world settings. Indeed, the sensitivity of slot-based methods to $K$, and how this affects their learned correspondence to objects in the data has largely been ignored in the literature. In this work, we address this issue through a systematic study of slot-based methods. We propose using analogs to precision and recall based on the Adjusted Rand Index to accurately quantify model behavior over a large range of $K$. We find that, especially during training, incorrect choices of $K$ do not yield the desired object decomposition and, in fact, cause substantial oversegmentation or merging of separate objects (undersegmentation). We demonstrate that the choice of the objective function and incorporating instance-level annotations can moderately mitigate this behavior while still falling short of fully resolving this issue. Indeed, we show how this issue persists across multiple methods and datasets and stress its importance for future slot-based models.