 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCulturalFrames: Assessing Cultural Expectation Alignment in Text-to-Image Models and Evaluation Metrics
Jun 10, 2025The increasing ubiquity of text-to-image (T2I) models as tools for visual content generation raises concerns about their ability to accurately represent diverse cultural contexts. In this work, we present the first study to systematically quantify the alignment of T2I models and evaluation metrics with respect to both explicit as well as implicit cultural expectations. To this end, we introduce CulturalFrames, a novel benchmark designed for rigorous human evaluation of cultural representation in visual generations. Spanning 10 countries and 5 socio-cultural domains, CulturalFrames comprises 983 prompts, 3637 corresponding images generated by 4 state-of-the-art T2I models, and over 10k detailed human annotations. We find that T2I models not only fail to meet the more challenging implicit expectations but also the less challenging explicit expectations. Across models and countries, cultural expectations are missed an average of 44% of the time. Among these failures, explicit expectations are missed at a surprisingly high average rate of 68%, while implicit expectation failures are also significant, averaging 49%. Furthermore, we demonstrate that existing T2I evaluation metrics correlate poorly with human judgments of cultural alignment, irrespective of their internal reasoning. Collectively, our findings expose critical gaps, providing actionable directions for developing more culturally informed T2I models and evaluation methodologies.
Direct Motion Models for Assessing Generated Videos
Apr 30, 2025A current limitation of video generative video models is that they generate plausible looking frames, but poor motion -- an issue that is not well captured by FVD and other popular methods for evaluating generated videos. Here we go beyond FVD by developing a metric which better measures plausible object interactions and motion. Our novel approach is based on auto-encoding point tracks and yields motion features that can be used to not only compare distributions of videos (as few as one generated and one ground truth, or as many as two datasets), but also for evaluating motion of single videos. We show that using point tracks instead of pixel reconstruction or action recognition features results in a metric which is markedly more sensitive to temporal distortions in synthetic data, and can predict human evaluations of temporal consistency and realism in generated videos obtained from open-source models better than a wide range of alternatives. We also show that by using a point track representation, we can spatiotemporally localize generative video inconsistencies, providing extra interpretability of generated video errors relative to prior work. An overview of the results and link to the code can be found on the project page: http://trajan-paper.github.io.
Scaling 4D Representations
Dec 19, 2024



Scaling has not yet been convincingly demonstrated for pure self-supervised learning from video. However, prior work has focused evaluations on semantic-related tasks $\unicode{x2013}$ action classification, ImageNet classification, etc. In this paper we focus on evaluating self-supervised learning on non-semantic vision tasks that are more spatial (3D) and temporal (+1D = 4D), such as camera pose estimation, point and object tracking, and depth estimation. We show that by learning from very large video datasets, masked auto-encoding (MAE) with transformer video models actually scales, consistently improving performance on these 4D tasks, as model size increases from 20M all the way to the largest by far reported self-supervised video model $\unicode{x2013}$ 22B parameters. Rigorous apples-to-apples comparison with many recent image and video models demonstrates the benefits of scaling 4D representations.
Probabilistic Inverse Cameras: Image to 3D via Multiview Geometry
Dec 13, 2024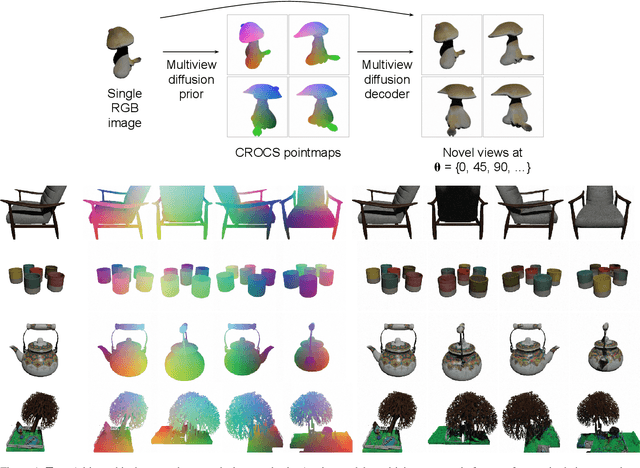


We introduce a hierarchical probabilistic approach to go from a 2D image to multiview 3D: a diffusion "prior" models the unseen 3D geometry, which then conditions a diffusion "decoder" to generate novel views of the subject. We use a pointmap-based geometric representation in a multiview image format to coordinate the generation of multiple target views simultaneously. We facilitate correspondence between views by assuming fixed target camera poses relative to the source camera, and constructing a predictable distribution of geometric features per target. Our modular, geometry-driven approach to novel-view synthesis (called "unPIC") beats SoTA baselines such as CAT3D and One-2-3-45 on held-out objects from ObjaverseXL, as well as real-world objects ranging from Google Scanned Objects, Amazon Berkeley Objects, to the Digital Twin Catalog.
Moving Off-the-Grid: Scene-Grounded Video Representations
Nov 08, 2024



Current vision models typically maintain a fixed correspondence between their representation structure and image space. Each layer comprises a set of tokens arranged "on-the-grid," which biases patches or tokens to encode information at a specific spatio(-temporal) location. In this work we present Moving Off-the-Grid (MooG), a self-supervised video representation model that offers an alternative approach, allowing tokens to move "off-the-grid" to better enable them to represent scene elements consistently, even as they move across the image plane through time. By using a combination of cross-attention and positional embeddings we disentangle the representation structure and image structure. We find that a simple self-supervised objective--next frame prediction--trained on video data, results in a set of latent tokens which bind to specific scene structures and track them as they move. We demonstrate the usefulness of MooG's learned representation both qualitatively and quantitatively by training readouts on top of the learned representation on a variety of downstream tasks. We show that MooG can provide a strong foundation for different vision tasks when compared to "on-the-grid" baselines.
How Does Code Pretraining Affect Language Model Task Performance?
Sep 06, 2024


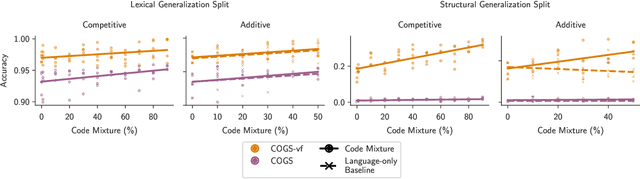
Large language models are increasingly trained on corpora containing both natural language and non-linguistic data like source code. Aside from aiding programming-related tasks, anecdotal evidence suggests that including code in pretraining corpora may improve performance on other, unrelated tasks, yet to date no work has been able to establish a causal connection by controlling between language and code data. Here we do just this. We pretrain language models on datasets which interleave natural language and code in two different settings: additive, in which the total volume of data seen during pretraining is held constant; and competitive, in which the volume of language data is held constant. We study how the pretraining mixture affects performance on (a) a diverse collection of tasks included in the BigBench benchmark, and (b) compositionality, measured by generalization accuracy on semantic parsing and syntactic transformations. We find that pretraining on higher proportions of code improves performance on compositional tasks involving structured output (like semantic parsing), and mathematics. Conversely, increase code mixture can harm performance on other tasks, including on tasks that requires sensitivity to linguistic structure such as syntax or morphology, and tasks measuring real-world knowledge.
Benchmarking Vision Language Models for Cultural Understanding
Jul 15, 2024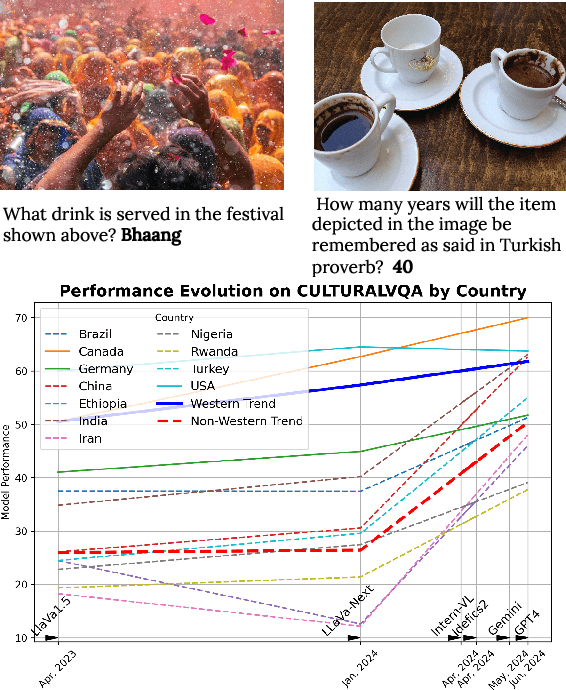
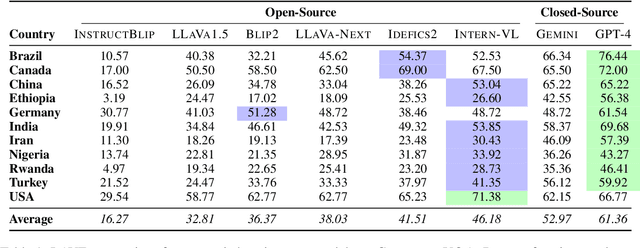

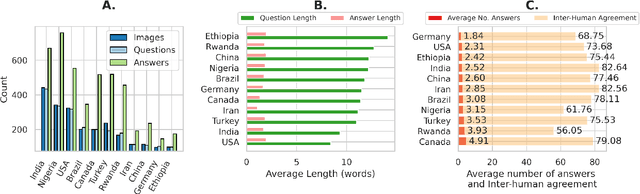
Foundation models and vision-language pre-training have notably advanced Vision Language Models (VLMs), enabling multimodal processing of visual and linguistic data. However, their performance has been typically assessed on general scene understanding - recognizing objects, attributes, and actions - rather than cultural comprehension. This study introduces CulturalVQA, a visual question-answering benchmark aimed at assessing VLM's geo-diverse cultural understanding. We curate a collection of 2,378 image-question pairs with 1-5 answers per question representing cultures from 11 countries across 5 continents. The questions probe understanding of various facets of culture such as clothing, food, drinks, rituals, and traditions. Benchmarking VLMs on CulturalVQA, including GPT-4V and Gemini, reveals disparity in their level of cultural understanding across regions, with strong cultural understanding capabilities for North America while significantly lower performance for Africa. We observe disparity in their performance across cultural facets too, with clothing, rituals, and traditions seeing higher performances than food and drink. These disparities help us identify areas where VLMs lack cultural understanding and demonstrate the potential of CulturalVQA as a comprehensive evaluation set for gauging VLM progress in understanding diverse cultures.
Neural Assets: 3D-Aware Multi-Object Scene Synthesis with Image Diffusion Models
Jun 13, 2024
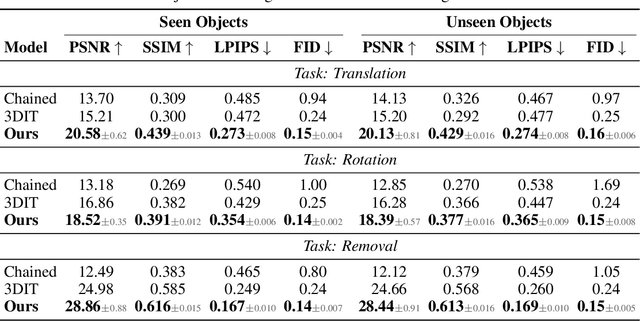

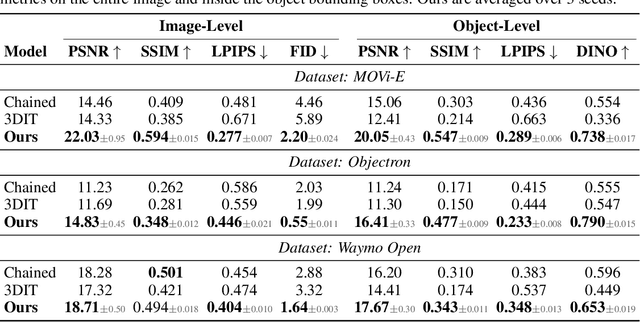
We address the problem of multi-object 3D pose control in image diffusion models. Instead of conditioning on a sequence of text tokens, we propose to use a set of per-object representations, Neural Assets, to control the 3D pose of individual objects in a scene. Neural Assets are obtained by pooling visual representations of objects from a reference image, such as a frame in a video, and are trained to reconstruct the respective objects in a different image, e.g., a later frame in the video. Importantly, we encode object visuals from the reference image while conditioning on object poses from the target frame. This enables learning disentangled appearance and pose features. Combining visual and 3D pose representations in a sequence-of-tokens format allows us to keep the text-to-image architecture of existing models, with Neural Assets in place of text tokens. By fine-tuning a pre-trained text-to-image diffusion model with this information, our approach enables fine-grained 3D pose and placement control of individual objects in a scene. We further demonstrate that Neural Assets can be transferred and recomposed across different scenes. Our model achieves state-of-the-art multi-object editing results on both synthetic 3D scene datasets, as well as two real-world video datasets (Objectron, Waymo Open).
DreamSync: Aligning Text-to-Image Generation with Image Understanding Feedback
Nov 29, 2023



Despite their wide-spread success, Text-to-Image models (T2I) still struggle to produce images that are both aesthetically pleasing and faithful to the user's input text. We introduce DreamSync, a model-agnostic training algorithm by design that improves T2I models to be faithful to the text input. DreamSync builds off a recent insight from TIFA's evaluation framework -- that large vision-language models (VLMs) can effectively identify the fine-grained discrepancies between generated images and the text inputs. DreamSync uses this insight to train T2I models without any labeled data; it improves T2I models using its own generations. First, it prompts the model to generate several candidate images for a given input text. Then, it uses two VLMs to select the best generation: a Visual Question Answering model that measures the alignment of generated images to the text, and another that measures the generation's aesthetic quality. After selection, we use LoRA to iteratively finetune the T2I model to guide its generation towards the selected best generations. DreamSync does not need any additional human annotation. model architecture changes, or reinforcement learning. Despite its simplicity, DreamSync improves both the semantic alignment and aesthetic appeal of two diffusion-based T2I models, evidenced by multiple benchmarks (+1.7% on TIFA, +2.9% on DSG1K, +3.4% on VILA aesthetic) and human evaluation.
A Systematic Comparison of Syllogistic Reasoning in Humans and Language Models
Nov 01, 2023



A central component of rational behavior is logical inference: the process of determining which conclusions follow from a set of premises. Psychologists have documented several ways in which humans' inferences deviate from the rules of logic. Do language models, which are trained on text generated by humans, replicate these biases, or are they able to overcome them? Focusing on the case of syllogisms -- inferences from two simple premises, which have been studied extensively in psychology -- we show that larger models are more logical than smaller ones, and also more logical than humans. At the same time, even the largest models make systematic errors, some of which mirror human reasoning biases such as ordering effects and logical fallacies. Overall, we find that language models mimic the human biases included in their training data, but are able to overcome them in some cases.