 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVESTA: Visual Exploration with Statistical Tool Agents
May 29, 2026Fitting quantitative models to data is a central step in scientific workflows, yet it remains one of the least automated. Recent agent-based systems leverage language and vision-language models (VLMs) to iteratively propose and refine statistical models, but these systems struggle on more challenging modeling tasks. To address these limitations, we introduce VESTA: Visual Exploration with Statistical Tool Agents, a framework that equips VLMs with a dynamically growing exploration toolkit to guide model refinement through data transformations, hypothesis-driven visualizations, and robust statistical tests. Unlike prior systems that rely on iterative critique alone, VESTA actively explores data before and during refinement by selecting or creating diagnostic tools, which accumulate in the model's context and can be reused later. We evaluate VESTA against established baselines in three toolkit configurations: no tools, static expert-written tools, and dynamic model-written tools. To support this evaluation, we introduce DAWN (Dataset for Automated Workflows and Numerical Modeling), a benchmark targeting distribution fitting and time series modeling with varying difficulty tiers, and culminating in real-world astronomy tasks including modeling initial mass functions and gravitational-wave chirp signals. We find that VESTA's dynamic tool creation outperforms prior agentic pipelines, with the largest gains on complex and domain-specific tasks. We further show that dynamically generated tools are substantially more sophisticated than those produced by existing visual tool-creation systems, covering more diagnostic categories per function and strongly preferring visual outputs that the VLM critic can reason over directly.
Discovering Failure Modes in Vision-Language Models using RL
Apr 06, 2026Vision-language Models (VLMs), despite achieving strong performance on multimodal benchmarks, often misinterpret straightforward visual concepts that humans identify effortlessly, such as counting, spatial reasoning, and viewpoint understanding. Previous studies manually identified these weaknesses and found that they often stem from deficits in specific skills. However, such manual efforts are costly, unscalable, and subject to human bias, which often overlooks subtle details in favor of salient objects, resulting in an incomplete understanding of a model's vulnerabilities. To address these limitations, we propose a Reinforcement Learning (RL)-based framework to automatically discover the failure modes or blind spots of any candidate VLM on a given data distribution without human intervention. Our framework trains a questioner agent that adaptively generates queries based on the candidate VLM's responses to elicit incorrect answers. Our approach increases question complexity by focusing on fine-grained visual details and distinct skill compositions as training progresses, consequently identifying 36 novel failure modes in which VLMs struggle. We demonstrate the broad applicability of our framework by showcasing its generalizability across various model combinations.
Benchmarking Vision Language Models for Cultural Understanding
Jul 15, 2024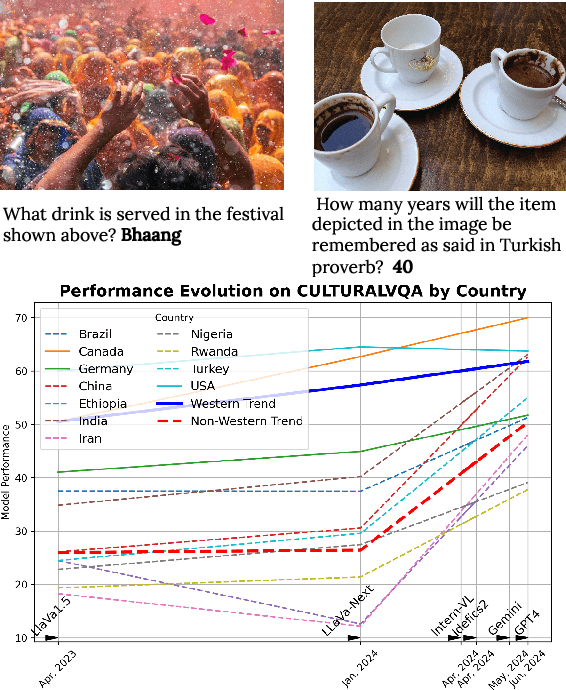
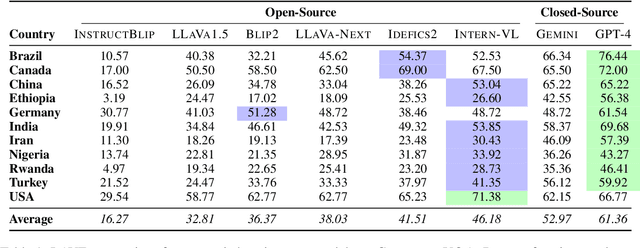

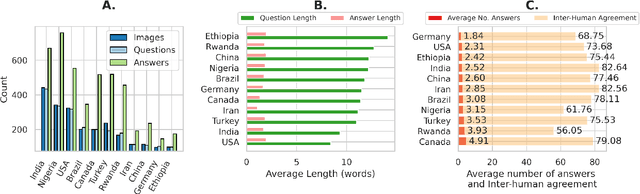
Foundation models and vision-language pre-training have notably advanced Vision Language Models (VLMs), enabling multimodal processing of visual and linguistic data. However, their performance has been typically assessed on general scene understanding - recognizing objects, attributes, and actions - rather than cultural comprehension. This study introduces CulturalVQA, a visual question-answering benchmark aimed at assessing VLM's geo-diverse cultural understanding. We curate a collection of 2,378 image-question pairs with 1-5 answers per question representing cultures from 11 countries across 5 continents. The questions probe understanding of various facets of culture such as clothing, food, drinks, rituals, and traditions. Benchmarking VLMs on CulturalVQA, including GPT-4V and Gemini, reveals disparity in their level of cultural understanding across regions, with strong cultural understanding capabilities for North America while significantly lower performance for Africa. We observe disparity in their performance across cultural facets too, with clothing, rituals, and traditions seeing higher performances than food and drink. These disparities help us identify areas where VLMs lack cultural understanding and demonstrate the potential of CulturalVQA as a comprehensive evaluation set for gauging VLM progress in understanding diverse cultures.
Instance-Level Semantic Maps for Vision Language Navigation
May 23, 2023



Humans have a natural ability to perform semantic associations with the surrounding objects in the environment. This allows them to create a mental map of the environment which helps them to navigate on-demand when given a linguistic instruction. A natural goal in Vision Language Navigation (VLN) research is to impart autonomous agents with similar capabilities. Recently introduced VL Maps \cite{huang23vlmaps} take a step towards this goal by creating a semantic spatial map representation of the environment without any labelled data. However, their representations are limited for practical applicability as they do not distinguish between different instances of the same object. In this work, we address this limitation by integrating instance-level information into spatial map representation using a community detection algorithm and by utilizing word ontology learned by large language models (LLMs) to perform open-set semantic associations in the mapping representation. The resulting map representation improves the navigation performance by two-fold (233\%) on realistic language commands with instance-specific descriptions compared to VL Maps. We validate the practicality and effectiveness of our approach through extensive qualitative and quantitative experiments.
Test-Time Amendment with a Coarse Classifier for Fine-Grained Classification
Feb 01, 2023We investigate the problem of reducing mistake severity for fine-grained classification. Fine-grained classification can be challenging, mainly due to the requirement of knowledge or domain expertise for accurate annotation. However, humans are particularly adept at performing coarse classification as it requires relatively low levels of expertise. To this end, we present a novel approach for Post-Hoc Correction called Hierarchical Ensembles (HiE) that utilizes label hierarchy to improve the performance of fine-grained classification at test-time using the coarse-grained predictions. By only requiring the parents of leaf nodes, our method significantly reduces avg. mistake severity while improving top-1 accuracy on the iNaturalist-19 and tieredImageNet-H datasets, achieving a new state-of-the-art on both benchmarks. We also investigate the efficacy of our approach in the semi-supervised setting. Our approach brings notable gains in top-1 accuracy while significantly decreasing the severity of mistakes as training data decreases for the fine-grained classes. The simplicity and post-hoc nature of HiE render it practical to be used with any off-the-shelf trained model to improve its predictions further.
Ground then Navigate: Language-guided Navigation in Dynamic Scenes
Sep 24, 2022

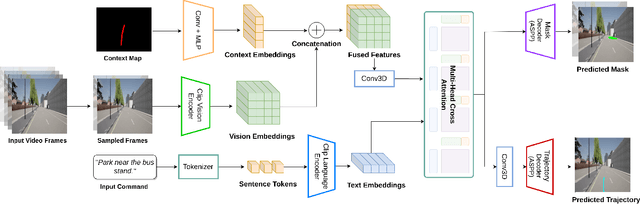
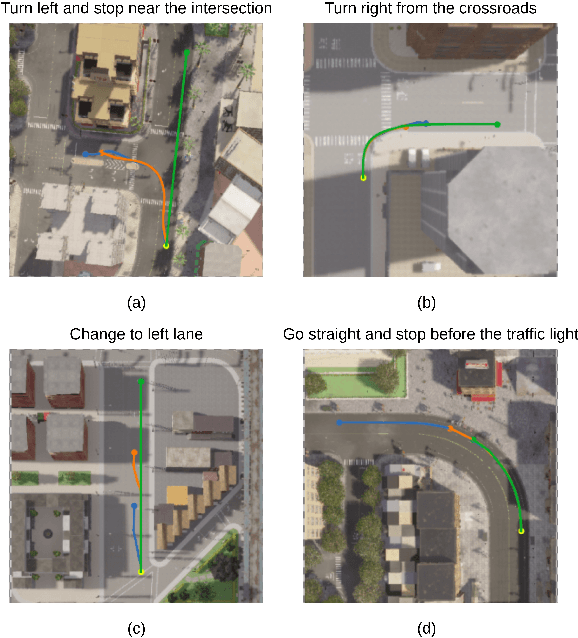
We investigate the Vision-and-Language Navigation (VLN) problem in the context of autonomous driving in outdoor settings. We solve the problem by explicitly grounding the navigable regions corresponding to the textual command. At each timestamp, the model predicts a segmentation mask corresponding to the intermediate or the final navigable region. Our work contrasts with existing efforts in VLN, which pose this task as a node selection problem, given a discrete connected graph corresponding to the environment. We do not assume the availability of such a discretised map. Our work moves towards continuity in action space, provides interpretability through visual feedback and allows VLN on commands requiring finer manoeuvres like "park between the two cars". Furthermore, we propose a novel meta-dataset CARLA-NAV to allow efficient training and validation. The dataset comprises pre-recorded training sequences and a live environment for validation and testing. We provide extensive qualitative and quantitive empirical results to validate the efficacy of the proposed approach.
Grounding Linguistic Commands to Navigable Regions
Dec 24, 2021



Humans have a natural ability to effortlessly comprehend linguistic commands such as "park next to the yellow sedan" and instinctively know which region of the road the vehicle should navigate. Extending this ability to autonomous vehicles is the next step towards creating fully autonomous agents that respond and act according to human commands. To this end, we propose the novel task of Referring Navigable Regions (RNR), i.e., grounding regions of interest for navigation based on the linguistic command. RNR is different from Referring Image Segmentation (RIS), which focuses on grounding an object referred to by the natural language expression instead of grounding a navigable region. For example, for a command "park next to the yellow sedan," RIS will aim to segment the referred sedan, and RNR aims to segment the suggested parking region on the road. We introduce a new dataset, Talk2Car-RegSeg, which extends the existing Talk2car dataset with segmentation masks for the regions described by the linguistic commands. A separate test split with concise manoeuvre-oriented commands is provided to assess the practicality of our dataset. We benchmark the proposed dataset using a novel transformer-based architecture. We present extensive ablations and show superior performance over baselines on multiple evaluation metrics. A downstream path planner generating trajectories based on RNR outputs confirms the efficacy of the proposed framework.
Comprehensive Multi-Modal Interactions for Referring Image Segmentation
Apr 21, 2021

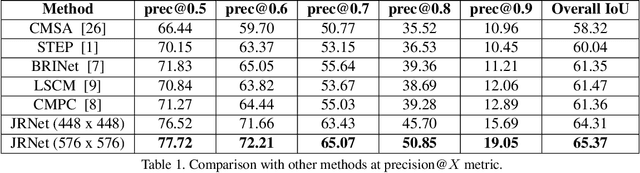

We investigate Referring Image Segmentation (RIS), which outputs a segmentation map corresponding to the given natural language description. To solve RIS efficiently, we need to understand each word's relationship with other words, each region in the image to other regions, and cross-modal alignment between linguistic and visual domains. Recent methods model these three types of interactions sequentially. We argue that such a modular approach limits these methods' performance, and joint simultaneous reasoning can help resolve ambiguities. To this end, we propose a Joint Reasoning (JRM) module and a novel Cross-Modal Multi-Level Fusion (CMMLF) module for tackling this task. JRM effectively models the referent's multi-modal context by jointly reasoning over visual and linguistic modalities (performing word-word, image region-region, word-region interactions in a single module). CMMLF module further refines the segmentation masks by exchanging contextual information across visual hierarchy through linguistic features acting as a bridge. We present thorough ablation studies and validate our approach's performance on four benchmark datasets, and show that the proposed method outperforms the existing state-of-the-art methods on all four datasets by significant margins.