 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrounding Linguistic Commands to Navigable Regions
Dec 24, 2021



Humans have a natural ability to effortlessly comprehend linguistic commands such as "park next to the yellow sedan" and instinctively know which region of the road the vehicle should navigate. Extending this ability to autonomous vehicles is the next step towards creating fully autonomous agents that respond and act according to human commands. To this end, we propose the novel task of Referring Navigable Regions (RNR), i.e., grounding regions of interest for navigation based on the linguistic command. RNR is different from Referring Image Segmentation (RIS), which focuses on grounding an object referred to by the natural language expression instead of grounding a navigable region. For example, for a command "park next to the yellow sedan," RIS will aim to segment the referred sedan, and RNR aims to segment the suggested parking region on the road. We introduce a new dataset, Talk2Car-RegSeg, which extends the existing Talk2car dataset with segmentation masks for the regions described by the linguistic commands. A separate test split with concise manoeuvre-oriented commands is provided to assess the practicality of our dataset. We benchmark the proposed dataset using a novel transformer-based architecture. We present extensive ablations and show superior performance over baselines on multiple evaluation metrics. A downstream path planner generating trajectories based on RNR outputs confirms the efficacy of the proposed framework.
Cosine meets Softmax: A tough-to-beat baseline for visual grounding
Sep 13, 2020
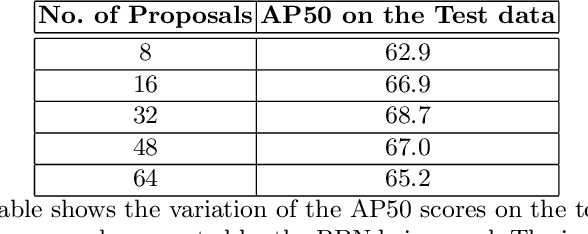

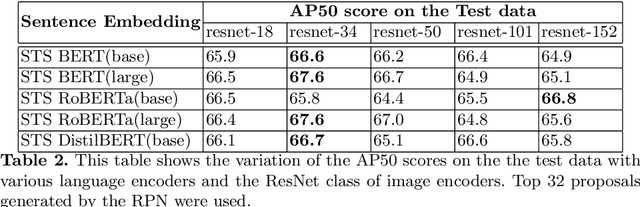
In this paper, we present a simple baseline for visual grounding for autonomous driving which outperforms the state of the art methods, while retaining minimal design choices. Our framework minimizes the cross-entropy loss over the cosine distance between multiple image ROI features with a text embedding (representing the give sentence/phrase). We use pre-trained networks for obtaining the initial embeddings and learn a transformation layer on top of the text embedding. We perform experiments on the Talk2Car dataset and achieve 68.7% AP50 accuracy, improving upon the previous state of the art by 8.6%. Our investigation suggests reconsideration towards more approaches employing sophisticated attention mechanisms or multi-stage reasoning or complex metric learning loss functions by showing promise in simpler alternatives.
SROM: Simple Real-time Odometry and Mapping using LiDAR data for Autonomous Vehicles
May 07, 2020
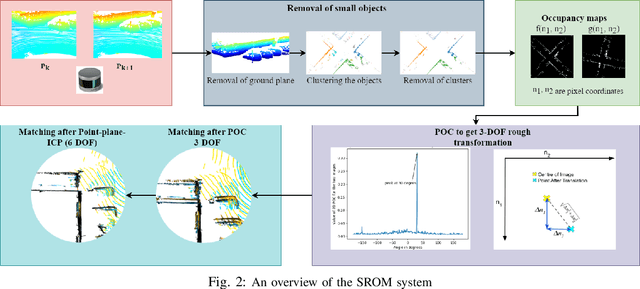
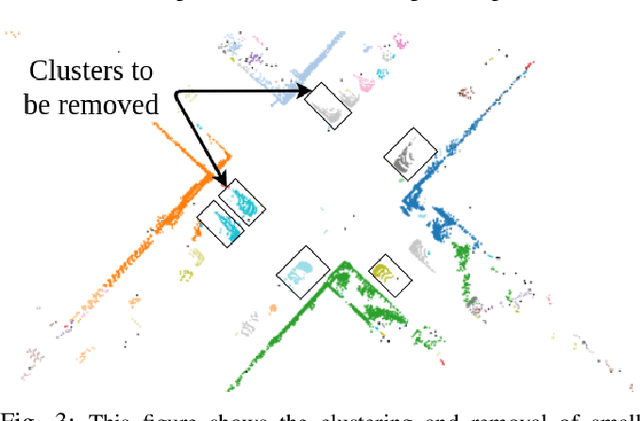

In this paper, we present SROM, a novel real-time Simultaneous Localization and Mapping (SLAM) system for autonomous vehicles. The keynote of the paper showcases SROM's ability to maintain localization at low sampling rates or at high linear or angular velocities where most popular LiDAR based localization approaches get degraded fast. We also demonstrate SROM to be computationally efficient and capable of handling high-speed maneuvers. It also achieves low drifts without the need for any other sensors like IMU and/or GPS. Our method has a two-layer structure wherein first, an approximate estimate of the rotation angle and translation parameters are calculated using a Phase Only Correlation (POC) method. Next, we use this estimate as an initialization for a point-to-plane ICP algorithm to obtain fine matching and registration. Another key feature of the proposed algorithm is the removal of dynamic objects before matching the scans. This improves the performance of our system as the dynamic objects can corrupt the matching scheme and derail localization. Our SLAM system can build reliable maps at the same time generating high-quality odometry. We exhaustively evaluated the proposed method in many challenging highways/country/urban sequences from the KITTI dataset and the results demonstrate better accuracy in comparisons to other state-of-the-art methods with reduced computational expense aiding in real-time realizations. We have also integrated our SROM system with our in-house autonomous vehicle and compared it with the state-of-the-art methods like LOAM and LeGO-LOAM.
SVM Enhanced Frenet Frame Planner For Safe Navigation Amidst Moving Agents
Jul 02, 2019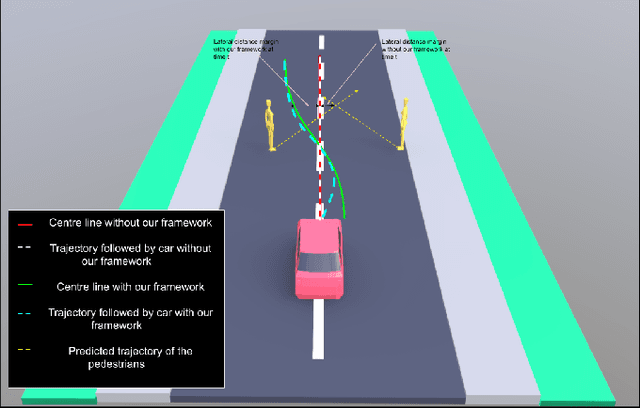


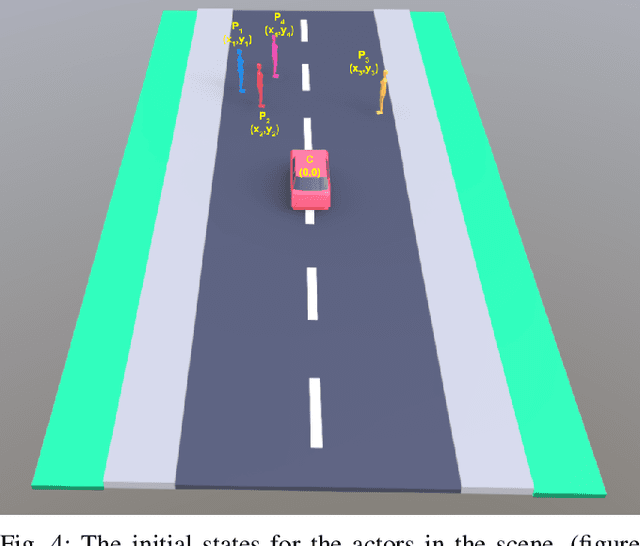
This paper proposes an SVM Enhanced Trajectory Planner for dynamic scenes, typically those encountered in on road settings. Frenet frame based trajectory generation is popular in the context of autonomous driving both in research and industry. We incorporate a safety based maximal margin criteria using a SVM layer that generates control points that are maximally separated from all dynamic obstacles in the scene. A kinematically consistent trajectory generator then computes a path through these waypoints. We showcase through simulations as well as real world experiments on a self driving car that the SVM enhanced planner provides for a larger offset with dynamic obstacles than the regular Frenet frame based trajectory generation. Thereby, the authors argue that such a formulation is inherently suited for navigation amongst pedestrians. We assume the availability of an intent or trajectory prediction module that predicts the future trajectories of all dynamic actors in the scene.